(二十八)大数据实战——Flume数据采集之kafka数据生产与消费集成案例
前言
本节内容我们主要介绍一下flume数据采集和kafka消息中间键的整合。通过flume监听nc端口的数据,将数据发送到kafka消息的first主题中,然后在通过flume消费kafka中的主题消息,将消费到的消息打印到控制台上。集成使用flume作为kafka的生产者和消费者。关于nc工具、flume以及kafka的安装部署,这里不在赘述,请读者查看作者往期博客内容。整体架构如下:

正文
-
启动Kafka集群,创建first主题
- 启动Kafka集群
- 创建first主题
kafka-topics.sh --bootstrap-server hadoop101:9092 --create --topic first --partitions 3 --replication-factor 3
- 查看first主题详情
kafka-topics.sh --bootstrap-server hadoop101:9092 --describe --topic first



- 在hadoop101服务器flume安装目录/opt/module/apache-flume-1.9.0/job下创建nc监听服务
- 创建nc监听的flume任务:job-netcat-flume-kafka.conf
# 1 组件定义 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 2 配置 source a1.sources.r1.type = netcat a1.sources.r1.bind = hadoop101 a1.sources.r1.port = 1111 # 3 配置 channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 4 配置 sink a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.bootstrap.servers = hadoop101:9092,hadoop102:9092,hadoop103:9092 a1.sinks.k1.kafka.topic = first a1.sinks.k1.kafka.flumeBatchSize = 20 a1.sinks.k1.kafka.producer.acks = 1 a1.sinks.k1.kafka.producer.linger.ms = 1 # 5 拼接组件 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1

- 在hadoop102服务器flume安装目录/opt/module/apache-flume-1.9.0/job下创建kafka监听r任务
- 创建kafka监听的flume任务:job-kafka-flume-console.conf
# 1 组件定义 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # 2 配置 source a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource a1.sources.r1.batchSize = 50 a1.sources.r1.batchDurationMillis = 200 a1.sources.r1.kafka.bootstrap.servers = hadoop101:9092,hadoop102:9092,hadoop103:9092 a1.sources.r1.kafka.topics = first a1.sources.r1.kafka.consumer.group.id = custom.g.id # 3 配置 channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 4 配置 sink a1.sinks.k1.type = logger # 5 拼接组件 a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
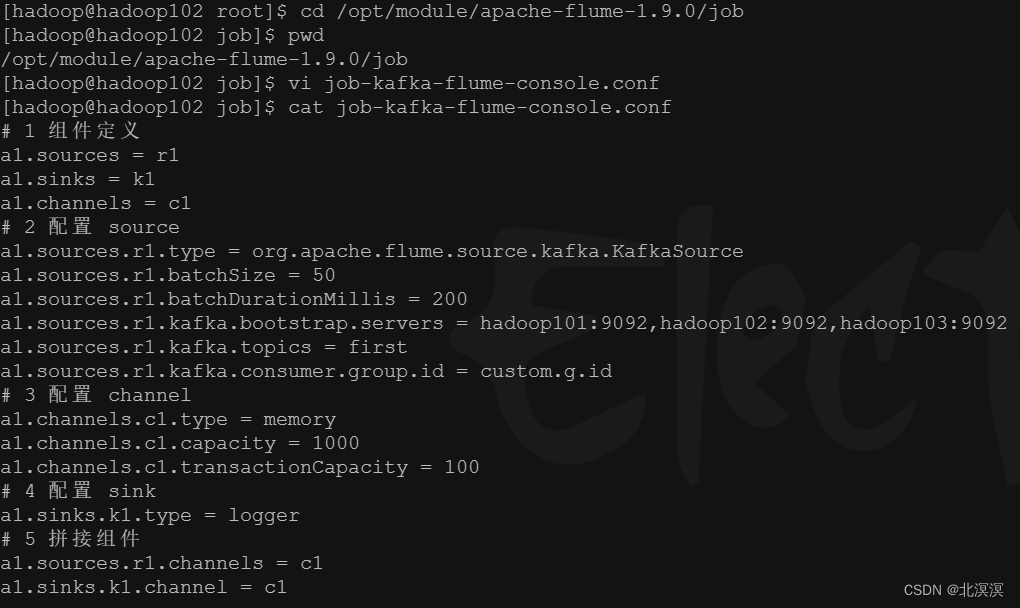
- 在hadoop102服务器启动kafka监听任务job-kafka-flume-console.conf
- 启动job-kafka-flume-console.conf任务
bin/flume-ng agent -c conf/ -n a1 -f job/job-kafka-flume-console.conf -Dflume.root.logger=INFO,console

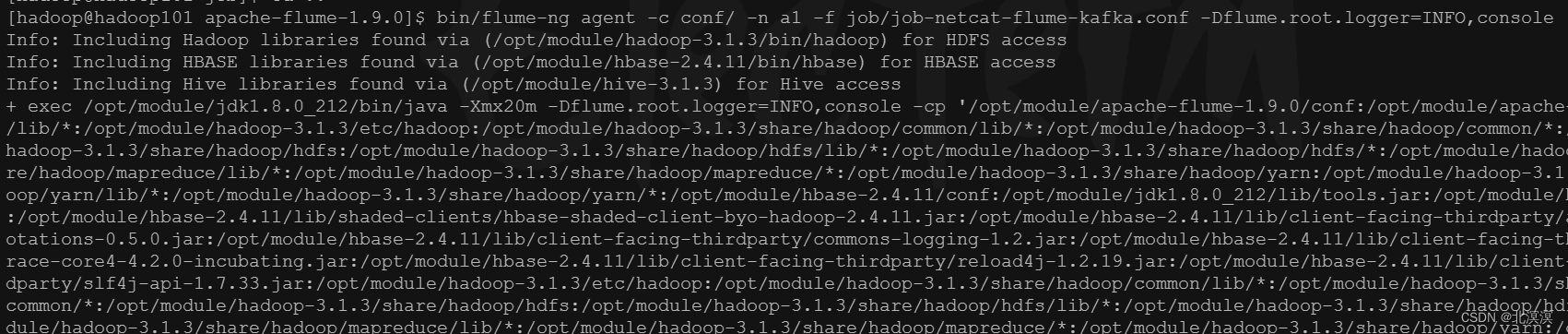
- 在hadoop101服务器启动nc监听任务job-netcat-flume-kafka.conf
- 启动job-netcat-flume-kafka.conf任务
bin/flume-ng agent -c conf/ -n a1 -f job/job-netcat-flume-kafka.conf -Dflume.root.logger=INFO,console
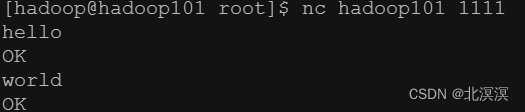
- 使用netcat工具发送数据到nc服务1111端口
- 发送nc消息
- 查看结果
- 控制台结果

结语
该案例证明了flume1成功采集到了nc监听端口的数据,并将数据发送到了kafka主题first中,flume2成功从kafka主题中消费到了数据并打印到了控制台。关于Flume数据采集之kafka数据生产与消费的集成案例到这里就结束了,我们下期见。。。。。。