2023大数据面试总结
文章目录
- Flink(SQL相关后面专题补充)
- 1. 把状态后端从FileSystem改为RocksDB后,Flink任务状态存储会发生哪些变化?
- 2. Flink SQL API State TTL 的过期机制是 onCreateAndUpdate 还是 onReadAndWrite?
- 3. watermark 到底是干啥的?应用场景?
- 4. 一个flink任务中可以既有事件时间窗口,又有处理时间窗口吗?
- 5. Flink为什么强调function实现时,实例化的变量要实现 serializable接口?
- 6. Flink 提交作业的流程?以及与yarn的互动?
- 7. Operator Chains了解吗?
- 8. 10个int以数组的形式保存,保存在什么状态好?VlaueState还是 ListState?存在哪个的性能比较好?
- 9. 一个窗口,现在只取第一帧和最后一帧,如何实现?
- 10. 背压的原理?解决办法?
- 11. 遇到状态放不下的场景怎么办?
- 12. 使用flink统计订单表的GMV(商品交易总额),如果mysql中的数据出现错误,之后在mysql中做数据的修改操作,那么flink程序如何保证GMV的正确性,你们是如何解决?
- 13. 开窗函数有哪些?
- 14. 没有数据流的时候,窗口存在吗
- 15. 1小时的滚动窗口,一小时处理一次的压力比较大想让他5分钟处理一次.怎么办?(问石林)
- 16. 两个流先后顺序不确定,到达的间隔也不确定,如何拼接成宽表?(问石林)
- 17. 为什么使用维表?什么情况下使用?
- 18. Flink维表关联怎么做的?(问石林)
- 19.
- 20.
Flink(SQL相关后面专题补充)
1. 把状态后端从FileSystem改为RocksDB后,Flink任务状态存储会发生哪些变化?
- Flink任务中的operator-state。无论用户配置哪种状态后端(无论是memory, filesystem,rocksdb),都是使用DefaultOperatorStateBackend 来管理的, 状态数据都存储在内存中,做Checkpoint时同步到远程文件存储中(比如HDFS)。
- Flink任务中的keyed-state。用户在配置rocksdb时,会使用 RocksdbKeyedStateBackend 去管理状态;用户在配置memory,filesystem时,会使用HeapKeyedStateBackend去管理状态。因此就有了这个问题的结论,配置 rocksdb只会影响keyed-state存储的方式和地方,operator-state不会受到影响。
2. Flink SQL API State TTL 的过期机制是 onCreateAndUpdate 还是 onReadAndWrite?
- 结论:Flink SQL API State TTL 的过期机制目前只支持 onCreateAndUpdate,DataStream API 两个都支持。
- 剖析:
- onCreateAndUpdate:是在创建State和更新State时【更新StateTTL】
- onReadAndWrite:是在访问State和写入State时【更新StateTTL】
- 实际踩坑场景:Flink SQL Deduplicate 写法,row_number partition by user_id
order by proctimeasc,此SQL最后生成的算子只会在第一条数据来的时候更新
state,后续访问不会更新stateTTL,因此state会在用户设置的stateTTL时间之后过期。
3. watermark 到底是干啥的?应用场景?
- 标识flink任务的事件时间进度,从而能够推动事件时间窗口的触发、计算
- 解决事件时间窗口的乱序问题
4. 一个flink任务中可以既有事件时间窗口,又有处理时间窗口吗?
结论:一个 Flink 任务可以同时有事件时间窗口,又有处理时间窗口。
两个角度说明:
- 我们其实没有必要把一个Flink任务和某种特定的时间语义进行绑定。对于事件时间窗口来说,我们只要给它watermark,能让watermark一直往前推进,让事件时间窗口能够持续触发计算就行。对于处理时间来说更简单,只要窗口算子按照本地时间按照固定的时间间隔进行触发就行。无论哪种时间窗口,主要满足时间窗口的触发条件就行。
- Flink的实现上来说也是支持的。Flink是使用一个叫做TimerService的组件来管理
timer的,我们可以同时注册事件时间和处理时间的timer,Flink会自行判断timer是否满足触发条件,如果是,则回调窗口处理函数进行计算。
5. Flink为什么强调function实现时,实例化的变量要实现 serializable接口?
其实这个问题可以延伸成3个问题:
- 为什么Flink要用到Java序列化机制。和Flink类型系统的数据序列化机制的用途有啥区别?
- 非实例化的变量没有实现Serializable为啥就不报错,实例化就报错?
- 为啥加transient就不报错?
上面3个问题的答案如下:
- Flink写的函数式编程代码或者说闭包,需要Java序列化从JobManager分发到 TaskManager,而Flink类型系统的数据序列化机制是为了分发数据,不是分发代码,可以用非Java的序列化机制,比如Kyro。
- 编译期不做序列化,所以不实现Serializable不会报错,但是运行期会执行序列化动
作,没实现Serializable接口的就报错了 - Flink DataStreamAPI的Function作为闭包在网络传输,必须采用Java序列化, 所以要通过Serializable接口标记,根据Java序列化的规定,内部成员变量要么都可序列化,要么通过transient关键字跳过序列化,否则Java序列化的时候会报错。静态变量不参与序列化,所以不用加transient。
6. Flink 提交作业的流程?以及与yarn的互动?
略
7. Operator Chains了解吗?
为了更高效地分布式执行,Flink 会尽可能地将operator的subtask链接(chain)在一起形成task。每个task在一个线程中执行。
将operators链接成task是非常有效的优化:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。这就是Operator Chains(算子链)。
8. 10个int以数组的形式保存,保存在什么状态好?VlaueState还是 ListState?存在哪个的性能比较好?
ValueState[Array[Int]] update形式。
ListState[Int]:add形式添加。
对于操控来说ListState方便取值与更改。
按键分区状态(Keyed State)选择ValueState ListState。
算子状态(Operator State)选择ListState。
9. 一个窗口,现在只取第一帧和最后一帧,如何实现?
略
10. 背压的原理?解决办法?
略
11. 遇到状态放不下的场景怎么办?
有时候需要求uv,内存或者状态中存过多数据,导致压力巨大,这个时候可以结合 Redis或者布隆过滤器来去重。
注意:布隆过滤器存在非常小的误判几率,不能判断某个元素一定百分之百存在,所以只能用在允许有少量误判的场景,不能用在需要100%精确判断存在的场景。
12. 使用flink统计订单表的GMV(商品交易总额),如果mysql中的数据出现错误,之后在mysql中做数据的修改操作,那么flink程序如何保证GMV的正确性,你们是如何解决?
CDC 动态捕捉MySQL数据变化,实时处理后数据入湖-Hudi,MOR 机制 快速对下游可见。
另:一般也会有离线Job来恢复和完善实时数据。
13. 开窗函数有哪些?
- Flink SQL:
- 待补充
- Flink Stream:
- ReduceFunction、AggregateFunction:窗口不维护原始数据,只维护中间结果。每次基于中间结果和增量数据进行聚合
- ProcessWindowFunction:维护全部原始数据,窗口触发时进行全量聚合
14. 没有数据流的时候,窗口存在吗
不存在,没有数据,窗口不产生
15. 1小时的滚动窗口,一小时处理一次的压力比较大想让他5分钟处理一次.怎么办?(问石林)
自定义触发器,4个方法,一个Close三个用于控制计算和输出
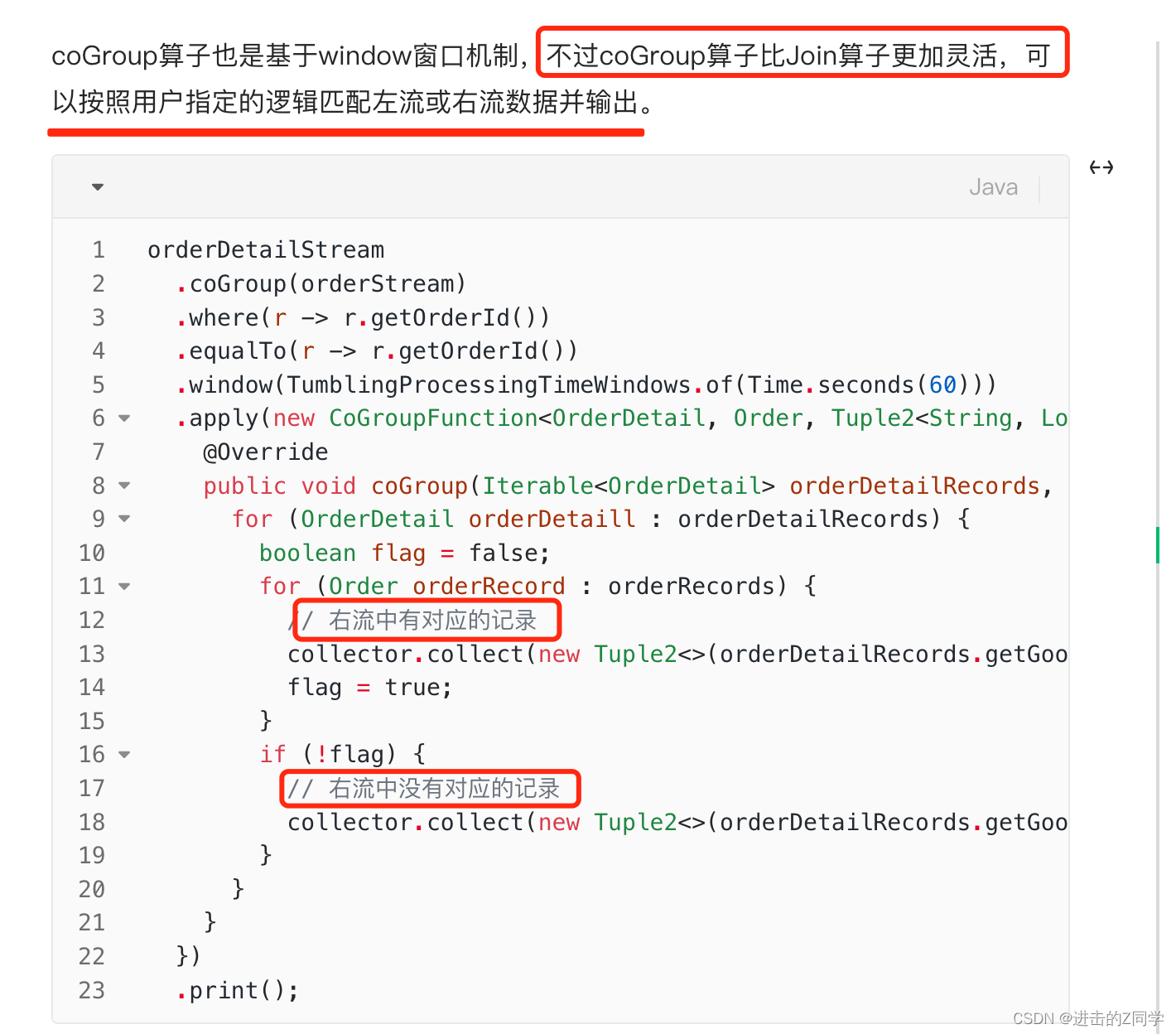
16. 两个流先后顺序不确定,到达的间隔也不确定,如何拼接成宽表?(问石林)
因为无法确定先到的是哪个流,所以没法用 internal join?因为这个需要指定拼接的驱动主流?
17. 为什么使用维表?什么情况下使用?
在一些数据量较小,且变化不大的场景下使用维表(如省份信息关联查询拼接)
18. Flink维表关联怎么做的?(问石林)
1、async io
2、broadcast
3、async io + cache
4、open方法中读取,然后定时线程刷新,缓存更新是先删除,之后再来一条之后再负责写入缓存