用huggingface.Accelerate进行分布式训练
诸神缄默不语-个人CSDN博文目录
本文属于huggingface.transformers全部文档学习笔记博文的一部分。
全文链接:huggingface transformers包 文档学习笔记(持续更新ing…)
本部分网址:https://huggingface.co/docs/transformers/main/en/accelerate
本文介绍如何使用huggingface.accelerate(官方文档:https://huggingface.co/docs/accelerate/index)进行分布式训练。
此外还参考了accelerate的安装文档:https://huggingface.co/docs/accelerate/basic_tutorials/install
一个本文代码可用的Python环境:Python 3.9.7, PyTorch 2.0.1, transformers 4.31.0, accelerate 0.22.0
parallelism能让我们实现在硬件条件受限时训练更大的模型,训练速度能加快几个数量级。
文章目录
- 1. 安装与配置
- 2. 在代码中使用
1. 安装与配置
安装:pip install accelerate
配置:accelerate config
然后它会给出一些问题,通过上下键更换选项,用Enter确定
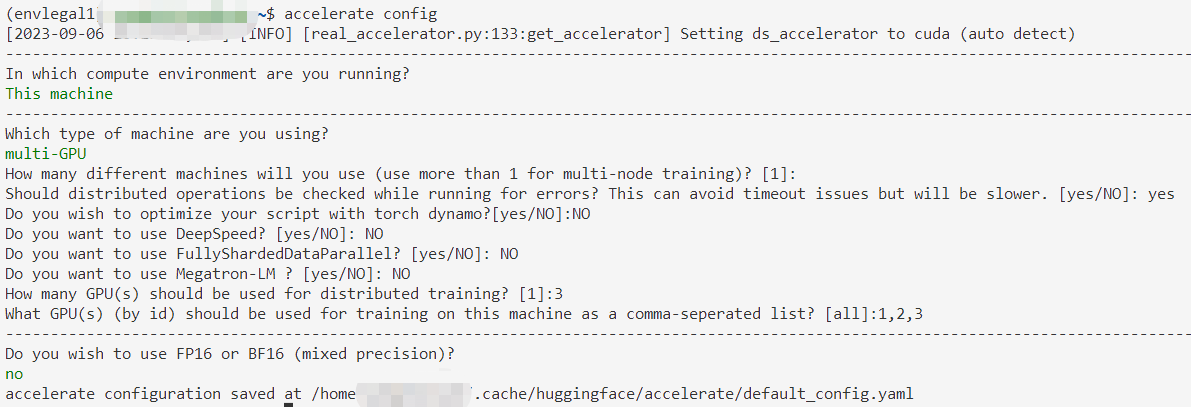
选错了也没啥关系,反正能改
用accelerate env命令可以查看配置环境。
2. 在代码中使用
用accelerate之前的脚本(具体讲解可见我之前写的博文:用huggingface.transformers.AutoModelForSequenceClassification在文本分类任务上微调预训练模型 用的是原生PyTorch那一版,因为Trainer会自动使用分布式训练。metric部分改成新版,并用全部数据来训练):
from tqdm.auto import tqdmimport torch
from torch.utils.data import DataLoader
from torch.optim import AdamWimport datasets,evaluate
from transformers import AutoTokenizer,AutoModelForSequenceClassification,get_schedulerdataset=datasets.load_from_disk("download/yelp_full_review_disk")tokenizer=AutoTokenizer.from_pretrained("/data/pretrained_models/bert-base-cased")def tokenize_function(examples):return tokenizer(examples["text"], padding="max_length",truncation=True,max_length=512)tokenized_datasets=dataset.map(tokenize_function, batched=True)#Postprocess dataset
tokenized_datasets=tokenized_datasets.remove_columns(["text"])
#删除模型不用的text列tokenized_datasets=tokenized_datasets.rename_column("label", "labels")
#改名label列为labels,因为AutoModelForSequenceClassification的入参键名为label
#我不知道为什么dataset直接叫label就可以啦……tokenized_datasets.set_format("torch") #将值转换为torch.Tensor对象small_train_dataset=tokenized_datasets["train"].shuffle(seed=42)
small_eval_dataset=tokenized_datasets["test"].shuffle(seed=42)train_dataloader=DataLoader(small_train_dataset,shuffle=True,batch_size=32)
eval_dataloader=DataLoader(small_eval_dataset,batch_size=64)model=AutoModelForSequenceClassification.from_pretrained("/data/pretrained_models/bert-base-cased",num_labels=5)optimizer=AdamW(model.parameters(),lr=5e-5)num_epochs=3
num_training_steps=num_epochs*len(train_dataloader)
lr_scheduler=get_scheduler(name="linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps)device=torch.device("cuda:1") if torch.cuda.is_available() else torch.device("cpu")
model.to(device)progress_bar = tqdm(range(num_training_steps))model.train()
for epoch in range(num_epochs):for batch in train_dataloader:batch={k:v.to(device) for k,v in batch.items()}outputs=model(**batch)loss=outputs.lossloss.backward()optimizer.step()lr_scheduler.step()optimizer.zero_grad()progress_bar.update(1)metric=evaluate.load("accuracy")
model.eval()
for batch in eval_dataloader:batch={k:v.to(device) for k,v in batch.items()}with torch.no_grad():outputs=model(**batch)logits=outputs.logitspredictions=torch.argmax(logits, dim=-1)metric.add_batch(predictions=predictions, references=batch["labels"])print(metric.compute())
懒得跑完了,总之预计要跑11个小时来着,非常慢。
添加如下代码:
from accelerate import Acceleratoraccelerator = Accelerator()#去掉将模型和数据集放到指定卡上的代码#在建立好数据集、模型和优化器之后:
train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(train_dataloader, eval_dataloader, model, optimizer
)#训练阶段将loss.backward()替换成
accelerator.backward(loss)
添加后的代码(我用全部数据集出来预计训练时间是4小时(3张卡),但我懒得跑这么久了,我就还是用1000条跑跑,把整个流程跑完意思一下):
用accelerate launch Python脚本路径运行
验证部分的情况见代码后面
from tqdm.auto import tqdmimport torch
from torch.utils.data import DataLoader
from torch.optim import AdamWimport datasets
from transformers import AutoTokenizer,AutoModelForSequenceClassification,get_schedulerfrom accelerate import Acceleratoraccelerator = Accelerator()dataset=datasets.load_from_disk("download/yelp_full_review_disk")tokenizer=AutoTokenizer.from_pretrained("/data/pretrained_models/bert-base-cased")def tokenize_function(examples):return tokenizer(examples["text"], padding="max_length",truncation=True,max_length=512)tokenized_datasets=dataset.map(tokenize_function, batched=True)#Postprocess dataset
tokenized_datasets=tokenized_datasets.remove_columns(["text"])
#删除模型不用的text列tokenized_datasets=tokenized_datasets.rename_column("label", "labels")
#改名label列为labels,因为AutoModelForSequenceClassification的入参键名为label
#我不知道为什么dataset直接叫label就可以啦……tokenized_datasets.set_format("torch") #将值转换为torch.Tensor对象small_train_dataset=tokenized_datasets["train"].shuffle(seed=42).select(range(1000))
small_eval_dataset=tokenized_datasets["test"].shuffle(seed=42).select(range(1000))train_dataloader=DataLoader(small_train_dataset,shuffle=True,batch_size=32)
eval_dataloader=DataLoader(small_eval_dataset,batch_size=64)model=AutoModelForSequenceClassification.from_pretrained("/data/pretrained_models/bert-base-cased",num_labels=5)optimizer=AdamW(model.parameters(),lr=5e-5)train_dataloader, eval_dataloader, model, optimizer = accelerator.prepare(train_dataloader, eval_dataloader, model, optimizer
)num_epochs=3
num_training_steps=num_epochs*len(train_dataloader)
lr_scheduler=get_scheduler(name="linear",optimizer=optimizer,num_warmup_steps=0,num_training_steps=num_training_steps)progress_bar = tqdm(range(num_training_steps))model.train()
for epoch in range(num_epochs):for batch in train_dataloader:outputs=model(**batch)loss=outputs.lossaccelerator.backward(loss)optimizer.step()lr_scheduler.step()optimizer.zero_grad()progress_bar.update(1)
验证部分是这样的,直接用原来的验证部分就也能跑,但是因为脚本会被运行2遍,所以验证部分也会运行2遍。
所以我原则上建议用accelerate的话就光训练,验证的部分还是单卡实现。
如果还是想在训练过程中看一下验证效果,可以正常验证;也可以将验证部分限定在if accelerator.is_main_process:里,这样就只有主进程(通常是第一个GPU)会执行验证代码,而其他GPU不会,这样就只会打印一次指标了。