C++项目——高并发内存池(2)——thread_cache的基础功能实现
1.并发内存池concurrent memory pool
组成部分
thread cache、central cache、page cache
- thread cache:线程缓存是每个线程独有的,用于小于64k的内存的分配,线程从这里申请内存不需要加锁,每个线程独享一个cache,这也就是这个并发线程池高效的地方。
- central cache:中心缓存是所有线程所共享,thread cache是按需从central cache中获取的对象。central cache周期性的回收thread cache中的对象,避免一个线程占用了太多的内存,而其他线程的内存吃紧。达到内存分配在多个线程中更均衡的按需调度的目的。central cache是存在竞争的,所以从这里取内存对象是需要加锁,但只会在两个及以上thread cache同时内存不够时,才会发生竞争。
- page cache:页缓存是在central cache缓存上面的一层缓存,存储的内存是以页为单位存储及分配的,central cache没有内存对象时,从page cache分配出一定数量的page,并切割成定长大小的小块内存,分配给central cache。page cache会回收central cache满足条件的span对象,并且合并相邻的页,组成更大的页,缓解内存碎片的问题。
2.thread cache
thread cache是哈希桶结构,每个桶是一个按桶位置映射大小的内存块对象的自由链表,即每一个桶都是一个定长内存池。C++项目——高并发内存池(1)--介绍及定长内存池_Gosolo!的博客-CSDN博客
每个线程都有一个thread cache对象,所以每个线程在这里获取对象和释放对象是无锁的。
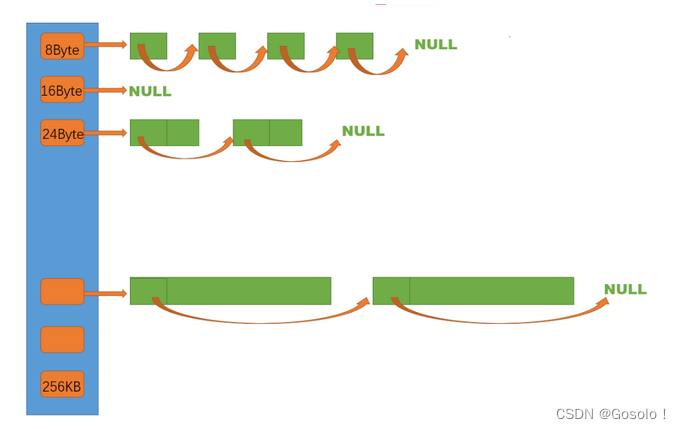
既然是哈希桶,那映射关系如何确定呢?
2.1 计算对象大小的对齐映射规则
首先进行内存拆分,每个thread cache总共享有64kb的缓存池
[1,128] 8byte对齐 freelist[0,16)
[128+1,1024] 16byte对齐 freelist[16,72)
[1024+1,8*1024] 128byte对齐 freelist[72,128)
[8*1024+1,64*1024] 1024byte对齐 freelist[128,184)
[64*1024+1,256*1024] 8*1024byte对齐 freelist[184,208) 这个不是给thread cache用的
那也就是说,根据我申请空间的大小不同,我们使用不同的桶来给予内存。
申请空间在[1,128],我们8个字节8个字节的给。
申请空间在[128+1,1024],16个字节16个字节的给。
所以当申请内存时,需要计算给他几个内存小块,即对齐数。
2.1.1 确认分配的内存空间
class SizeClass
{
public: //按照申请的内存大小 决定分配多少对齐数整数倍的内存空间static size_t _RoundUp(size_t size, size_t alignNum){size_t alignSize;if (size % alignNum != 0){alignSize = (size / alignNum + 1)*alignNum;}else{alignSize = size;}return alignSize;}static inline size_t RoundUp(size_t size){if (size <= 128){return _RoundUp(size, 8);}else if (size <= 1024){return _RoundUp(size, 16);}else if (size <= 8 * 1024){return _RoundUp(size, 128);}else if (size <= 64 * 1024){return _RoundUp(size, 1024);}else if (size <= 256 * 1024){return _RoundUp(size, 8 * 1024);}else{assert(false);return -1;}}
};更好的一种写法
static inline size_t _RoundUp(size_t bytes, size_t alignNum){return ((bytes + alignNum - 1) & ~(alignNum - 1));}
2.1.2 确定哈希桶编号
简单写法
size_t _Index(size_t bytes, size_t alignNum){//假如需要8字节 那他在下标为0的桶if (bytes % alignNum == 0){return bytes / alignNum - 1;}else//假如需要8字节 那他在下标为0的桶{ return bytes / alignNum;}}利用位运算的高效方法
class SizeClass
{
public:static inline size_t _Index(size_t bytes, size_t align_shift){return ((bytes + (1 << align_shift) - 1) >> align_shift) - 1;}// 计算映射的哪一个自由链表桶static inline size_t Index(size_t bytes){assert(bytes <= MAX_BYTES);// 每个区间有多少个链static int group_array[4] = { 16, 56, 56, 56 };if (bytes <= 128){return _Index(bytes, 3);}else if (bytes <= 1024){return _Index(bytes - 128, 4) + group_array[0];}else if (bytes <= 8 * 1024){return _Index(bytes - 1024, 7) + group_array[1] + group_array[0];}else if (bytes <= 64 * 1024){return _Index(bytes - 8 * 1024, 10) + group_array[2] + group_array[1] + group_array[0];}else if (bytes <= 256 * 1024){return _Index(bytes - 64 * 1024, 13) + group_array[3] + group_array[2] + group_array[1] + group_array[0];}else{assert(false);}return -1;}};2.2 thread cache框架
class ThreadCache
{
public:// 申请和释放内存对象void* Allocate(size_t size);void Deallocate(void* ptr, size_t size);/************************************本文先实现申请和释放对象************************************/// 从中心缓存获取对象void* FetchFromCentralCache(size_t index, size_t size);// 释放对象时,链表过长时,回收内存回到中心缓存void ListTooLong(FreeList* list, size_t size);
private:FreeList _freeLists[NFREELISTS];
};
/*TLS thread lcoal storage 为了使线程从thread cache 里申请内存不加锁 就需要一个仅自己可见,其他线程不可见的变量存储方式
*/
static _declspec(thread) ThreadCache* pTLSThreadCache = nullptr;2.2.1 TLS
TLS介绍转载自
Thread Local Storage_evilswords的博客-CSDN博客
Instance(单件)机制原本是让代码执行时只有一个实例,但有的时候又希望每个线程各自能有自己的"单件"相互不影响,处理类似的需求最先想到的就是全局表,然后按线程id或是管理线程的key索引到对应的单件上,取全局表的时候需要加锁。 虽然这样也能实现目的,但是代码看上去很不自然。最近发现还是有更自然的方法能实现这一点,就是 TLS 线程本地存储。
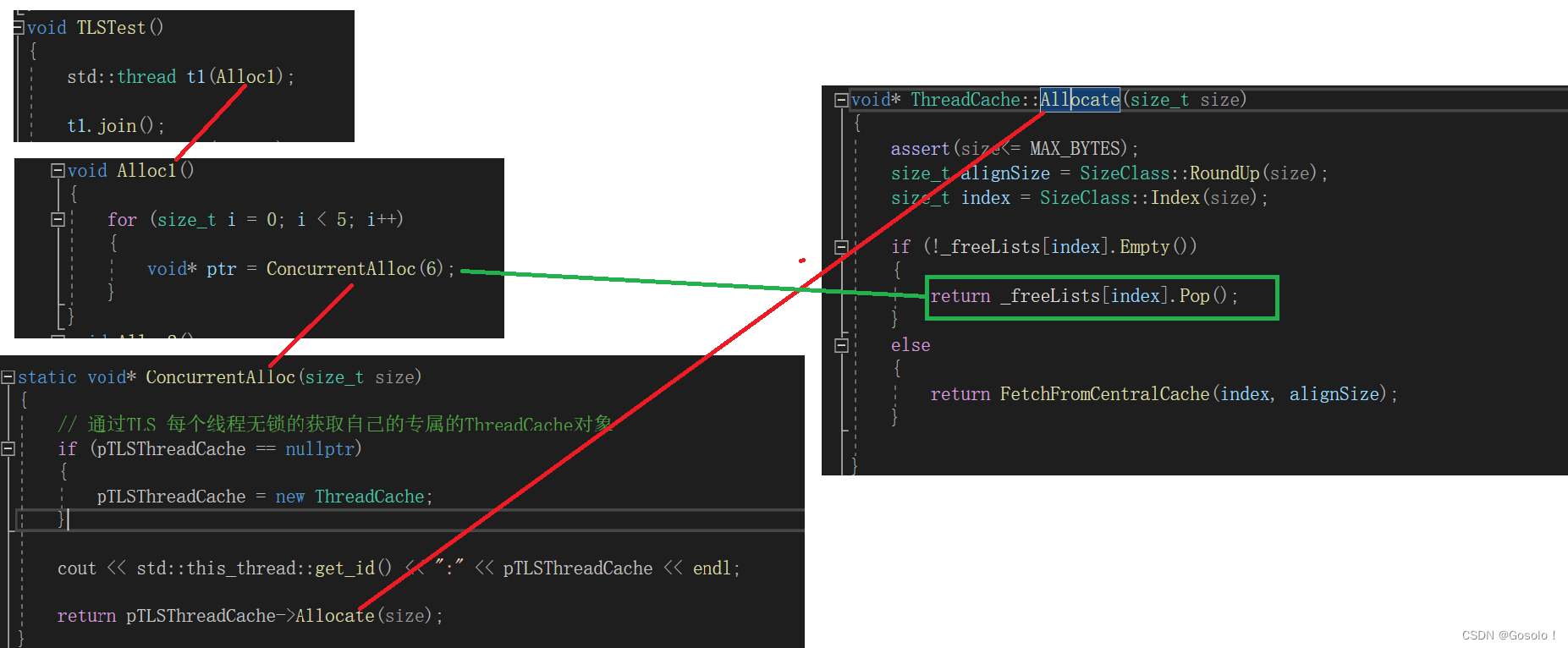
static void* ConcurrentAlloc(size_t size)
{// 通过TLS 每个线程无锁的获取自己的专属的ThreadCache对象if (pTLSThreadCache == nullptr){pTLSThreadCache = new ThreadCache;}cout << std::this_thread::get_id() << ":" << pTLSThreadCache << endl;return pTLSThreadCache->Allocate(size);
}static void ConcurrentFree(void* ptr, size_t size)
{assert(pTLSThreadCache);pTLSThreadCache->Deallocate(ptr, size);
}
2.2.2 thread cache具体实现
void* ThreadCache::Allocate(size_t size)
{assert(size<= MAX_BYTES);size_t alignSize = SizeClass::RoundUp(size);size_t index = SizeClass::Index(size);if (!_freeLists[index].Empty()){return _freeLists[index].Pop();}else{return FetchFromCentralCache(index, alignSize);}
}
void ThreadCache::Deallocate(void* ptr, size_t size)
{assert(ptr);assert(size <= MAX_BYTES);size_t index = SizeClass::Index(size);_freeLists[index].Push(ptr);}2.2.3 流程图