数据结构——哈希表
哈希表
这里没有讲哈希表底层的概念,什么转红黑树,什么链表的,这篇文章主要讲的是如何用C实现哈希表,以及哈希表的基本概念。后面我会出一篇文章来讲C++中hashmap中的底层逻辑的知识。
哈希表的概念
哈希表是一种数据结构,类似于数组,但它的主要优势在于快速查找和检索数据。在数组中,每个位置可以存储值,查找或删除特定位置的值的效率是O(1),只需将相应的索引提供给数组即可直接访问。然而,如果您只有值,想要在数组中查找这个值时,时间复杂度会变成O(n),因为您需要遍历整个数组来找到匹配的值。
哈希表通过使用哈希函数来改善这种情况,将查找操作的平均时间复杂度降低到O(1)。哈希函数将键(key)映射到数组的特定位置,这个位置通常称为“桶”。通过哈希函数,我们可以快速确定要查找或删除的数据所在的桶,从而显著减少了查找的时间。
然而,哈希表的优化是基于空间换时间的原则。它需要使用额外的内存空间来存储哈希表本身,而且在某些情况下,不同的键可能会映射到相同的桶,导致哈希冲突。解决哈希冲突需要额外的处理,例如链地址法或开放寻址法。尽管如此,总体而言,哈希表仍然提供了一种高效的数据存储和检索方式,特别适用于需要快速查找数据的应用场景。
它的数据结构:
结构定义:
物理结构:
数据域:存储数据的位置,也就是概念中所说的桶,每个桶用于存储一个数据项或多个数据项的链表(或其他数据结构)。数组的大小通常是一个固定的值,但在一些实现中也可以动态调整。
哈希函数:哈希函数接受键(Key)作为输入,并生成一个整数值,这个值通常被称为索引。哈希函数的作用是将键映射到数组(桶)中的一个特定位置,然后就可以通过Key值获得索引,看当前位置是否有Key值。
冲突处理机制:由于不同的键可能映射到相同的桶位置,因此哈希表需要一种方法来处理这种冲突。常见的冲突处理方法包括链地址法,在同一个位置,也就是同一个通中形成一个链表讲不同的Key值像链表一样串起来;开放寻址法(在冲突的情况下寻找下一个可用的桶),或者再哈希法(讲带入过哈希函数的返回的值,再次带入哈希函数)。
typedef struct Node {//结点void key;//这里就是存储的key值,可以是任何类型,字符串,数值,字符等等struct Node *next;//链表,肯定需要记录下一个结点的地址嘛 } Node;typedef struct Hash{int size;//哈希表的长度Node **data;//数据域,这里用到了链表,也就是链式地址法,俗称拉链法//假如哈希冲突了,不同的key值,找到了同一个位置,然后就直接接到这个链表的后面,然后进行对比该条链表的结点的key值,如果找到了说明存在key值,如果没找到就说不不纯在key值 } Hash;int Hashfunchtion(void key) {//哈希函数return ;//这里就需要看key是对应的什么类型来定义哈希函数 }逻辑结构:
键-值对:哈希表的逻辑结构由键-值对组成。键是用户提供的数据,而值是与键关联的实际数据。哈希表使用键来计算索引,并将值存储在对应的桶中。
索引:索引是通过哈希函数计算得到的整数值,它用于确定数据项在数组中的位置。索引是键的逻辑表示,在查找、插入和删除数据时都用到。
结构操作:
哈希表主要就是插入和查找操作,其他的操作只要学会了前面两个操作,基本都能自己实现,下面我就讲述插入和查找操作:
插入操作:
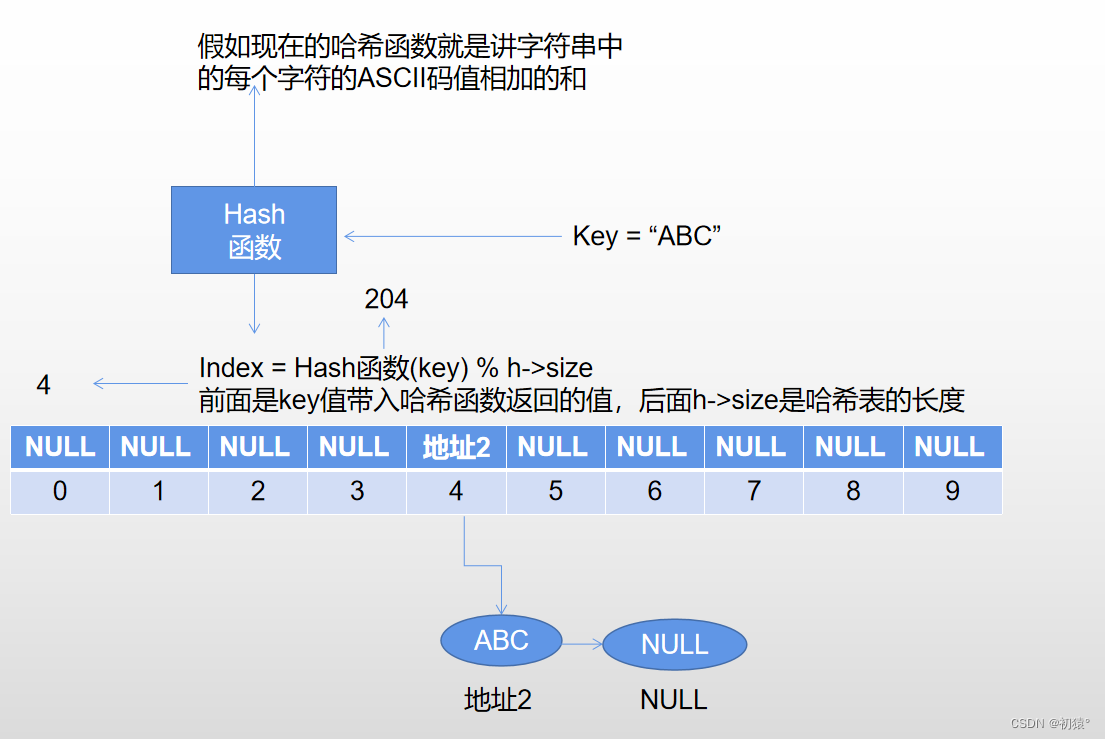
如图:插入操作,这里的key值用的是字符串,将字符串ABC添加入哈希表中:
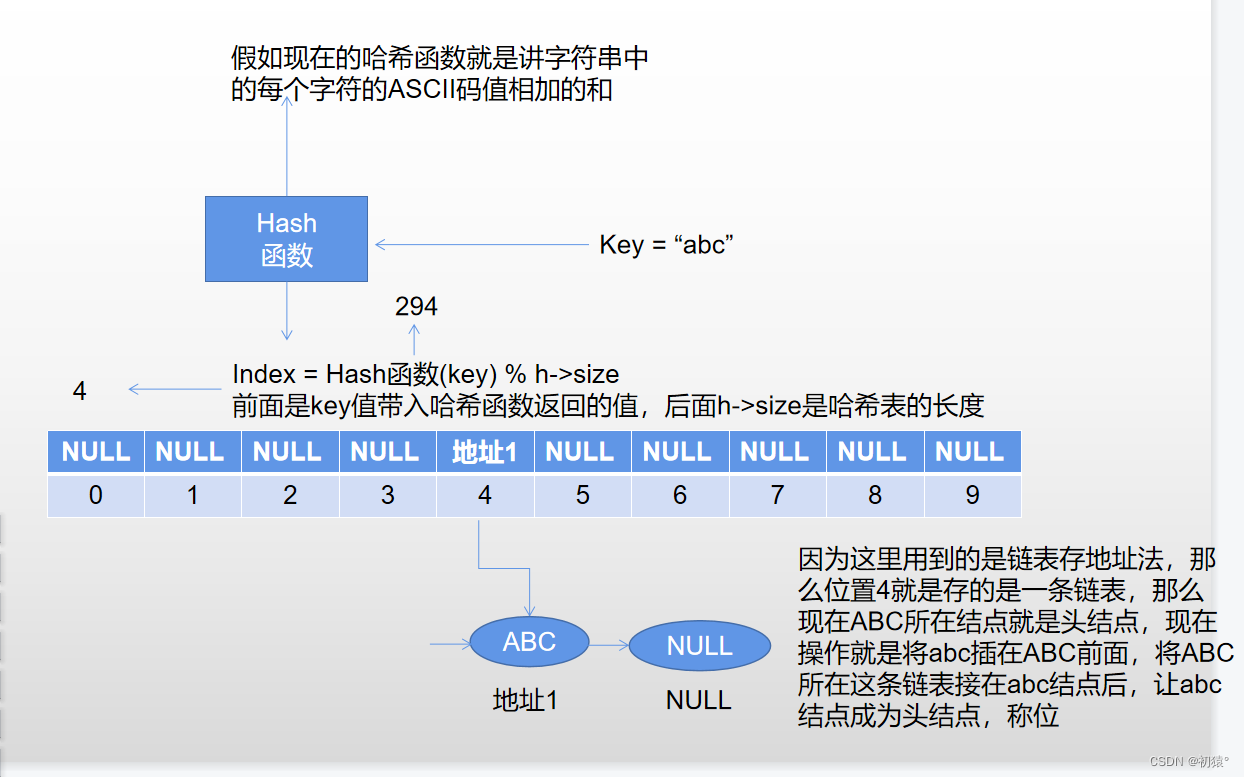
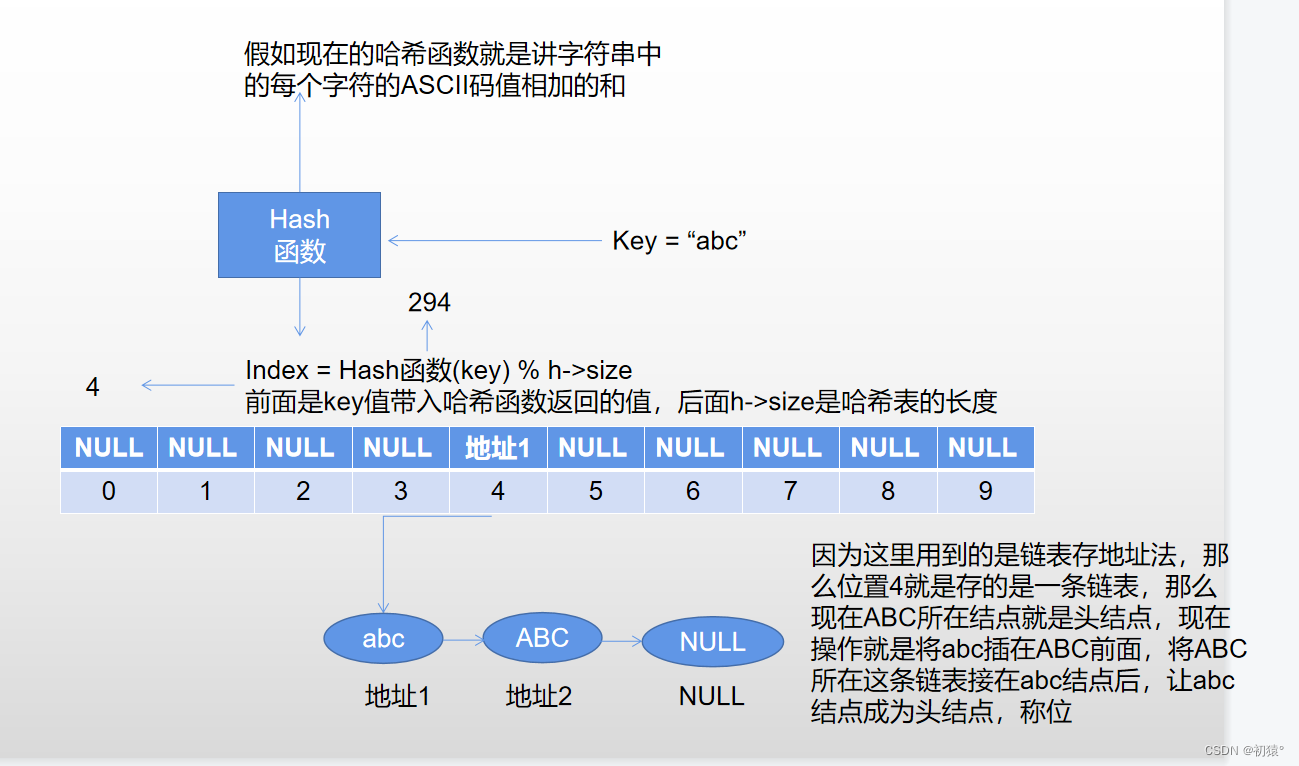
假如key值换了,然后获得的下标也是4,下面就是防冲突机制处理,这里添加的字符串是abc:
然后完成了冲突操作的插入;
片段代码实现:
int Hashfunchtion(char *key) {//哈希函数,这里用到的和图中的不一样,这样可以更高效的防冲突int seed = 18, hash = 0;for (int i = 0; key[i]; i++) hash = hash * seed + key[i];//这里可能会变为负数return hash & 0x7fffffff;//0x7fffffff这是16进制你转换为二进制就是除了符号位都是1//正数与上它不变,负数与上就变为整数 }Node *getNewNode(char *key, Node *head) {Node *p = (Node *)malloc(sizeof(Node));p->key = strdup(key);p->next = head;//这里用到的是头插法,从头部直接插入,接上后面的结点,如果是第一次插入这个位置,那么head就是NULL;return p; }int insert(Hash *h, char *key) {//插入元素int ind = Hashfunchtion(key) % h->size;//先将key带入哈希函数转为整数,然后模上哈希表的长度,使他的值不会超出哈希表的范围,最后获得索引h->data[ind] = getNewNode(key, h->data[ind]);return 1; }查找操作:
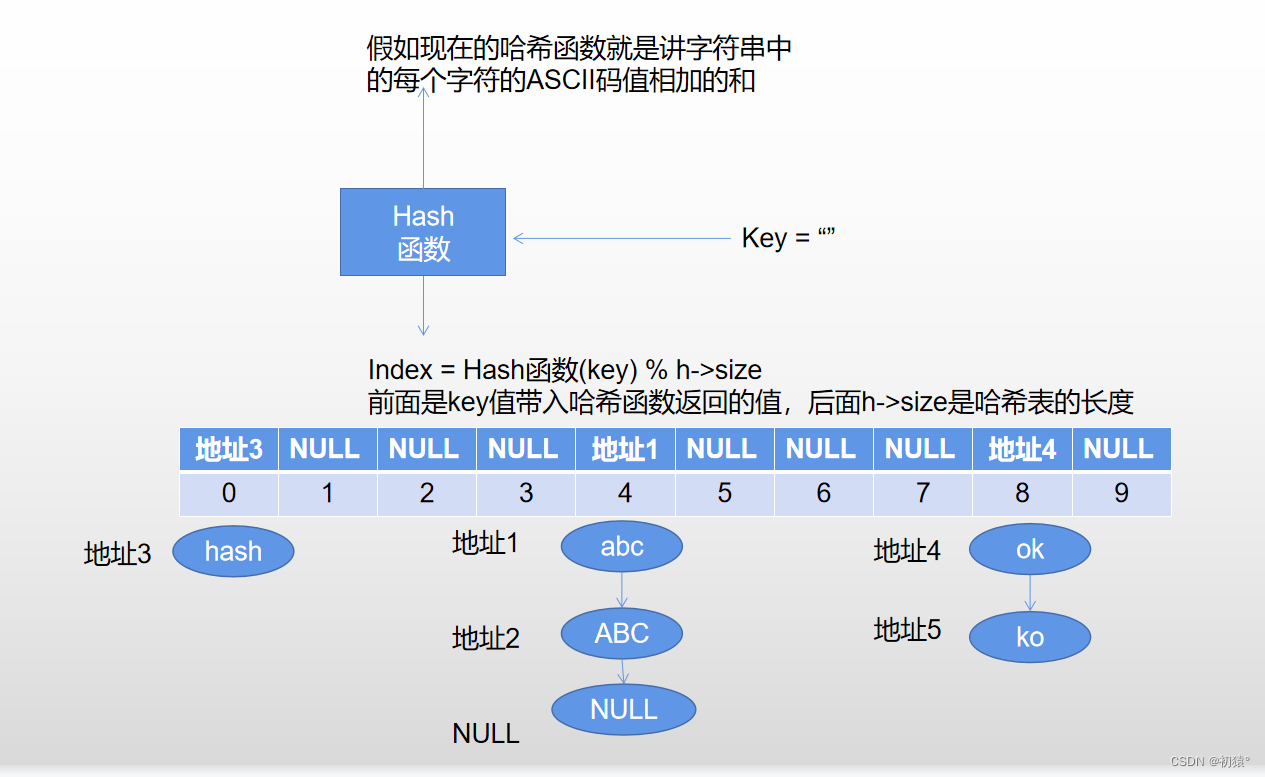
现在我添加了几个元素进这个哈希表中如图:
现在在这个哈希表中查找Key = good,
在哈希表中查询,该位置的地址为空,那么就说明在哈希表中没有该元素,返回0;
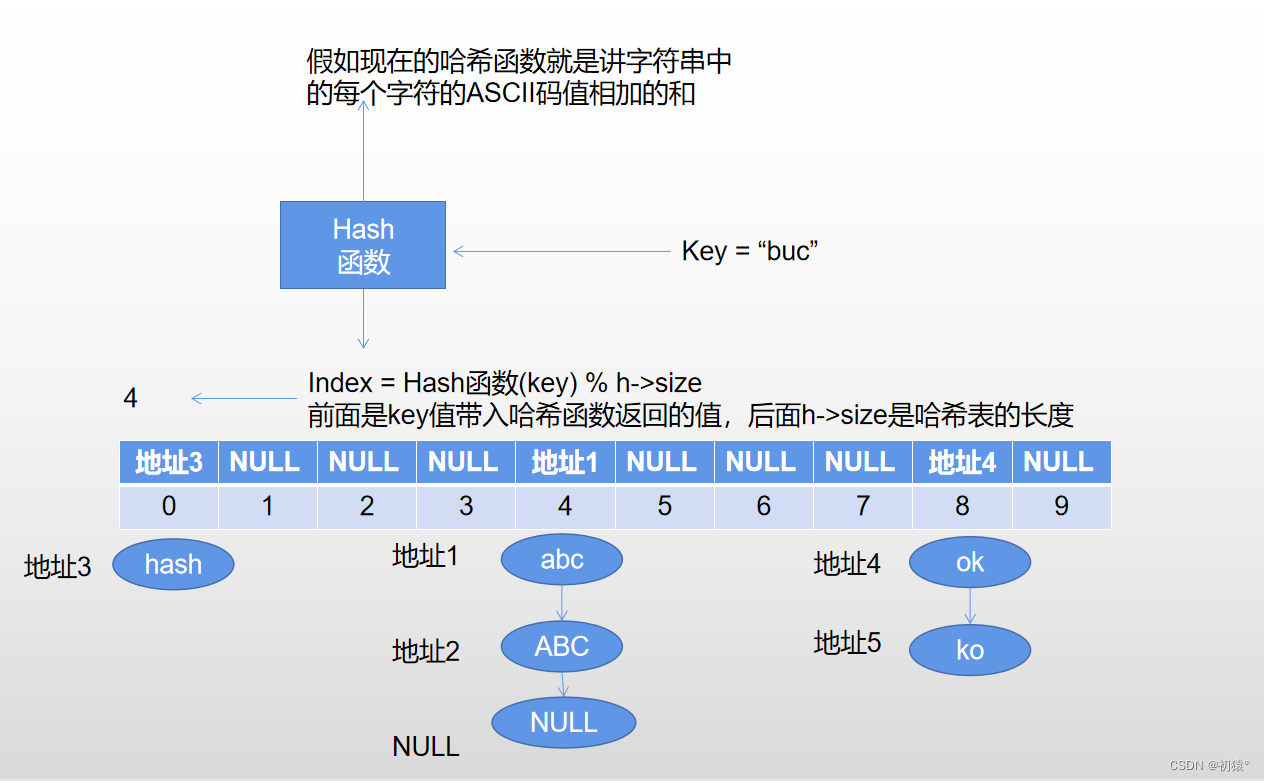
现在查询Key = buc
索引为4,对应地址不为空,那么就,创建一个指针进行对链表遍历,进行对链表中每个结点中的对应的Key值进行对比,最后发现没有,遍历完链表,现在指针应该指向空,一样返回0;
现在查询Key = ABC;
索引为4,对应地址不为空,那么就,创建一个指针进行对链表遍历,进行对链表中每个结点中的对应的Key值进行对比,然后指针指到地址2时匹配成功,最后返回该指针是否为空,为空就返回0,不为空返回1,那么现在返回的就是1,查找成功;
ok集中查询情况了解了,来看一下代码片段是如何实现的:
int Hashfunchtion(char *key) {//哈希函数int seed = 18, hash = 0;for (int i = 0; key[i]; i++) hash = hash * seed + key[i];//这里可能会变为负数return hash & 0x7fffffff;//0x7fffffff这是16进制你转换为二进制就是除了符号位都是1//正数与上它不变,负数与上就变为整数 }int search(Hash *h, char *key) {//查找key是否在哈希表中int ind = Hashfunchtion(key) % h->size; //先获取key值对应索引Node *p = h->data[ind];while (p && strcmp(p->key, key)) p = p->next;//比较当前索引的结点链表中的key,因为这里key是字符串需要用到strcmp函数进行对比return p != NULL;//如果p==NULL,返回0说明没有找到,如果p不为空那说明找到 }最终代码:
#include <stdio.h> #include <string.h> #include <stdlib.h>typedef struct Node {//结点char *key;//这里就是存储的key值,可以是任何类型,字符串,数值,字符等等struct Node *next;//链表,肯定需要记录下一个结点的地址嘛 } Node;typedef struct Hash{int size;//哈希表的长度Node **data;//数据域,这里用到了链表,也就是链式地址法,俗称拉链法//假如哈希冲突了,不同的key值,找到了同一个位置,然后就直接接到这个链表的后面,然后进行对比该条链表的结点的key值,如果找到了说明存在key值,如果没找到就说不不纯在key值 } Hash;Hash *getNewHash(int n) {Hash *h = (Hash *)malloc(sizeof(Hash)); h->size = n << 1;//为了防止以外开两倍h->data = (Node **)calloc(sizeof(Node *), h->size);return h; }int Hashfunchtion(char *key) {//哈希函数int seed = 18, hash = 0;for (int i = 0; key[i]; i++) hash = hash * seed + key[i];//这里可能会变为负数return hash & 0x7fffffff;//0x7fffffff这是16进制你转换为二进制就是除了符号位都是1//正数与上它不变,负数与上就变为整数 }Node *getNewNode(char *key, Node *head) {Node *p = (Node *)malloc(sizeof(Node));p->key = strdup(key);p->next = head;//这里用到的是头插法,从头部直接插入,接上后面的结点,如果是第一次插入这个位置,那么head就是NULL;return p; }int insert(Hash *h, char *key) {//插入元素int ind = Hashfunchtion(key) % h->size;//先将key带入哈希函数转为整数,然后模上哈希表的长度,使他的值不会超出哈希表的范围,最后获得索引h->data[ind] = getNewNode(key, h->data[ind]);return 1; }int search(Hash *h, char *key) {//查找key是否在哈希表中int ind = Hashfunchtion(key) % h->size; //先获取key值对应索引Node *p = h->data[ind];while (p && strcmp(p->key, key)) p = p->next;//比较当前索引的结点链表中的key,因为这里key是字符串需要用到strcmp函数进行对比return p != NULL;//如果p==NULL,返回0说明没有找到,如果p不为空那说明找到 }void clearNode(Node *root) {if (!root) return ;Node *p = root, *q;while (p) {q = p->next;free(p->key);free(p);p = q;}free(q);return ; }void clearHash(Hash *h) {if (!h) return ;for (int i = 0; i < h->size; i++) clearNode(h->data[i]);free(h->data);free(h);return ; }int main() {int op;char key[105] = {0};Hash *h = getNewHash(100);while (~scanf("%d%s", &op, key)) {switch (op) {case 0: {printf("insert %s from Hash is success\n", key);insert(h, key);} break;case 1: {printf("search %s from Hash is %d\n", key, search(h, key)); } break;default:{clearHash(h);return 0;}}}return 0; }


这里我只是实现了一种放冲突方法,其实还有很多优秀的防冲突方法,比如这个链表存地址的方法,如果一个位置冲突多了,链表的长度也变长了,查找效率也变低了,然后在c++中的hashmap中转换为一个红黑树的结构,这样插入和查找效率稳定在O(logn);