crawlab通过docker单节点部署简单爬虫
crawlab
单节点docker安装
此处介绍的是单节点的方式,多节点的情况可以把爬虫上传到一个节点中,之后会同步到其它节点上
version: '3.3'
services:master:image: crawlabteam/crawlabcontainer_name: crawlab_masterrestart: alwaysenvironment:CRAWLAB_NODE_MASTER: Y # Y: 主节点CRAWLAB_MONGO_HOST: mongo # mongo host address. 在 Docker-Compose 网络中,直接引用 service 名称CRAWLAB_MONGO_PORT: 27017 # mongo port CRAWLAB_MONGO_DB: crawlab # mongo database CRAWLAB_MONGO_USERNAME: username # mongo usernameCRAWLAB_MONGO_PASSWORD: password # mongo password CRAWLAB_MONGO_AUTHSOURCE: admin # mongo auth source volumes:- "./master:/data" # 持久化 crawlab 数据,master是win中的相对目录ports:- "8080:8080" # 开放 api 端口depends_on:- mongomongo:image: mongo:4.2restart: alwaysenvironment:MONGO_INITDB_ROOT_USERNAME: username # mongo usernameMONGO_INITDB_ROOT_PASSWORD: password # mongo passwordvolumes:- "/opt/crawlab/mongo/data/db:/data/db" # 持久化 mongo 数据ports:- "27017:27017" # 开放 mongo 端口到宿主机
docker-compose up -d运行,访问localhost:8080,用户密码均为admin
上传爬虫
此处上传一个爬取图片的简单爬虫,上传requirements.txt或者package.json文件,crawlab会自动扫描并安装依赖,但是如果存在多版本依赖的话,还没尝试,希望大神知道的留言告知。
爬虫是一个下载美女图片的爬虫,进入到crawlab的终端中,执行pip3 list 可以看到安装的包,其中常见的如requests、parsel都已经安装了
// ceshi.py
import requests
import parsel
import os
os.mkdir('/data/aa')
for page in range(1, 2):print(f'-------正在爬取第{page}页----------')sub_url = ''if page == 1 else '_' + str(page)url = f'https://pic.netbian.com/4kmeinv/index{sub_url}.html'if not os.path.exists('/data/aa/' + f'第{page}页'):os.mkdir('/data/aa/' + f'第{page}页')response = requests.get(url=url)response.encoding = 'gbk'data_html = response.textselector = parsel.Selector(data_html)a_href_list = selector.css('#main > div.slist > ul > li > a::attr(href)').getall() # 获取每个图片的urlfor a_href in a_href_list:a_href = 'https://pic.netbian.com' + a_hrefresponse_1 = requests.get(a_href)selector_1 = parsel.Selector(response_1.text) # 每个图片的网页链接img = selector_1.css('#main > div > div > div > a > img::attr(src)').getall()[0] # 照片的urldownload_url = 'https://pic.netbian.com/' + imgtitle = img.split('/')[-1]download = requests.get(download_url).contentwith open(f'/data/aa/第{page}页/{title}', mode='wb')as f:f.write(download)print(title, '下载完成')print(f'第{page}页全部下载完成')
图片下载到data目录下,而data又通过docker映射到了本机的master目录中
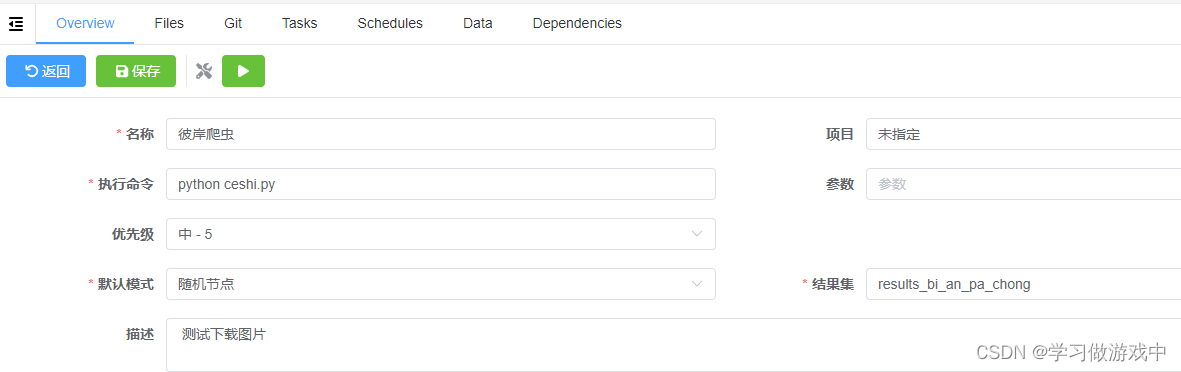
填写如下
总结
简单的用了下,感觉crawlab很好用,能把多个爬虫方便的管理起来,还有cron的功能,当作脚本管理也很不错