机器学习-神经网络(西瓜书)
神经网络
5.1 神经元模型
在生物神经网络中,神经元之间相互连接,当一个神经元受到的外界刺激足够大时,就会产生兴奋(称为"激活"),并将剩余的"刺激"向相邻的神经元传导。
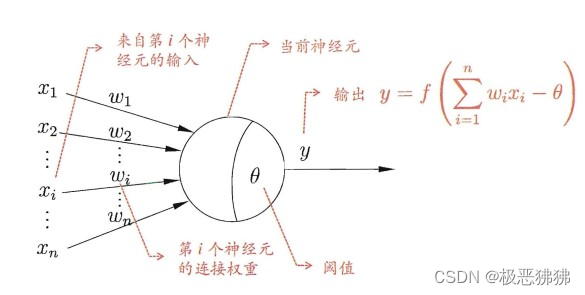
神经元模型
模型中 x i x_i xi表示各个神经元传来的刺激,刺激强度有大有小,所以 w i w_i wi表示不同刺激的权重,Θ表示阈值。一段刺激经过加权汇总再减去神经元的阈值后,经过激活函数 f f f处理,就是一个输出y,它如果不为0,那么y就会作用到其他神经元当中,就如同 x i x_i xi一样作为输入。
前面提到的激活函数 f f f一般表示为:
s i g m o i d ( x ) = 1 1 + e − x sigmoid(x) = \frac{1}{1+e^{-x}} sigmoid(x)=1+e−x1
5.2 感知机与多层网络
- 感知机能快速实现与,或,非逻辑运算,它由两层神经元组成,输入层接受信号好传递到输出层,并在输出层进行激活函数处理。
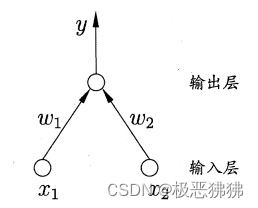
输出计算方法为:
y = f ( ∑ i w i x i − Θ ) y = f(\sum_{i}w_ix_i-Θ) y=f(i∑wixi−Θ)
以"与"运算为例( x 1 x_1 x1交 x 2 x_2 x2):令两个w值为1,Θ(阈值)为2,则有
y = f ( 1 × x 1 + 1 × x 2 − 2 ) y=f(1×x_1+1×x_2-2) y=f(1×x1+1×x2−2)
只在x均为1时,y才为1
- 常见的神经网络如下图所示的层级结构,每层神经元与下一层的互相连接,称为"多层前馈神经网络",神经网络学习到的内容,存在于前面提到的连接权 w i w_i wi和阈值 Θ Θ Θ里。
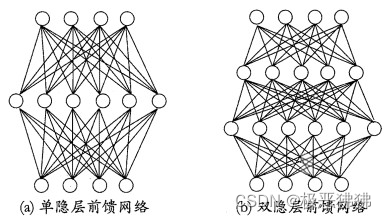
5.3 误差逆传播算法(简称BP)
多层网络的学习能力强于单层感知机,可以用BP算法进行训练,通过计算实际输出与期望输出之间的误差,再将这份误差反向传播到网络的每一层,从而调整网络中的权重,这个过程会迭代进行,直到训练效果达到预期。
累计误差表示为:
E = 1 m ∑ k = 1 m E k E=\frac{1}{m}\sum^m_{k=1}E_k E=m1k=1∑mEk
具体步骤的伪代码为:
1.初始化网络的权重和阈值
2.对于每个训练样本,进行前向传播计算:将输入样本传递给输入层计算隐藏层的输出,使用激活函数(前面提到的Sigmoid函数)将隐藏层的输出传递给输出层,再次使用激活函数
3.计算输出层的误差(期望输出与实际输出的差值)
4.反向传播误差:根据误差和激活函数的导数,计算输出层的梯度将输出层的梯度传播回隐藏层,再根据权重调整梯度更新隐藏层到输出层的权重把隐藏层的梯度传播回输入层,根据权重调整梯度更新输入层到隐藏层的权重
5.重复2-4步骤,直到达到预定的训练次数或者收敛了
6.使用训练好的网络进行预测
BP神经网络经常出现"过拟合"现象,表现为:训练误差持续降低,测试误差上升。解决的方法有两种:
- 第一种是"早停":把数据集分为训练集和验证集,前者就是做上述伪代码的工作,即计算梯度,更新权重等;验证集用来估计误差(如分类任务中的分类准确率),当出现训练误差减小但验证误差提升时,停止训练,同时返回具有最小验证集误差的权重和阈值。
- 第二种是"正则化",在误差目标函数中加入一个描述网络复杂度的部分,通过对模型的复杂度进行惩罚(如限制模型的参数或权重的大小)来防止过拟合
深度学习
深度学习模型通过"增加隐层"的数目,提高训练效率,降低过拟合的风险。
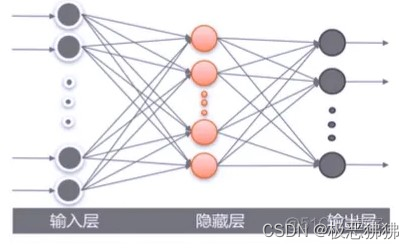
以第二章的手写体识别为例,网络输入是一个32×32的手写数字图像,输出是算法的识别结果,过程以伪代码的形式呈现。
对所有手写数字文本将加载的32×32矩阵转为一行1024的向量把文本对应的数字转化为one-hot向量(某个值为1,其余均为0)
构建神经网络:设置网络的隐藏层数,各隐藏层神经元个数,激活函数学习率,优化方法,最大迭代次数
做测试
隐藏层中的神经元能直接影响网络的学习能力,但是如果数量过多容易导致出现过拟合现象,选取合适参数的方法有
- 手动筛选:给定一个范围,如:比较50,100,500的效果,如果200的效果优于其他两者,那么就从50到100间再选择一个数值,但这个方法有点慢
- 正则化技术:以L1正则化(L1 Regularization)为例:L1正则化通过在损失函数中添加参数的绝对值之和,来惩罚模型中的大参数。这导致一些参数变为零,从而实现特征选择和稀疏性。L1正则化可以促使模型更加稀疏,即只有少数参数对模型的预测起作用,其他参数趋近于零。
实验:比较隐藏层不同神经元个数的多层感知机的实验效果
(学习率均为0.0001,迭代次数为2000)
clf = MLPClassifier(hidden_layer_sizes=(100,),activation='logistic', solver='adam',learning_rate_init=0.0001, max_iter=2000)
print(clf)
变量为神经元个数,分别是50,100,500,1000




实验分析:神经元个数从50逐渐升到500个的过程中,网络对目标特征的抓取能力逐渐提升,所以识别的正确率随之提高。但在个数跳到1000时正确率没有提高,可能是因为个数在达到1000之前,多层感知机就已经收敛了,个数继续增加相当于时过度训练数据,提高网络复杂度,这并不会带来增益。能测试的变量还有迭代次数和学习率。