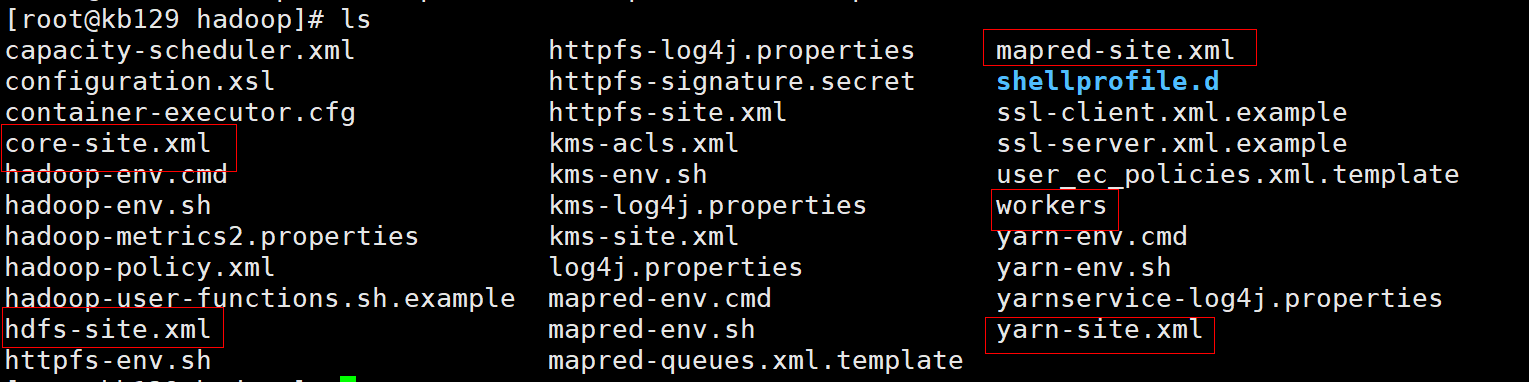
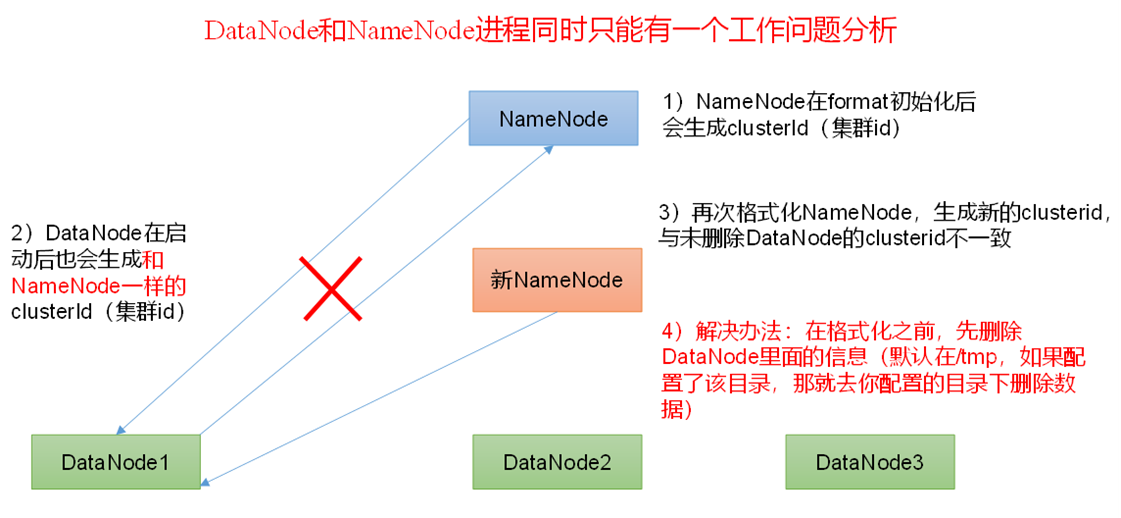
| 2.3 配置单机Hadoop (1)配置core-site.xml <configuration><!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://kb129:9000</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/opt/soft/hadoop313/data</value></property><!-- 配置HDFS网页登录使用的静态用户为root --><property><name>hadoop.http.staticuser.user</name><value>root</value></property><property><name>io.file.buffer.size</name><value>131072</value></property><property><name>hadoop.proxyuser.root.hosts</name><value>*</value></property><property><name>hadoop.proxyuser.root.groups</name><value>*</value></property></configuration>
(2)配置hdfs-site.xml 1)编辑hadoop-enc.sh 

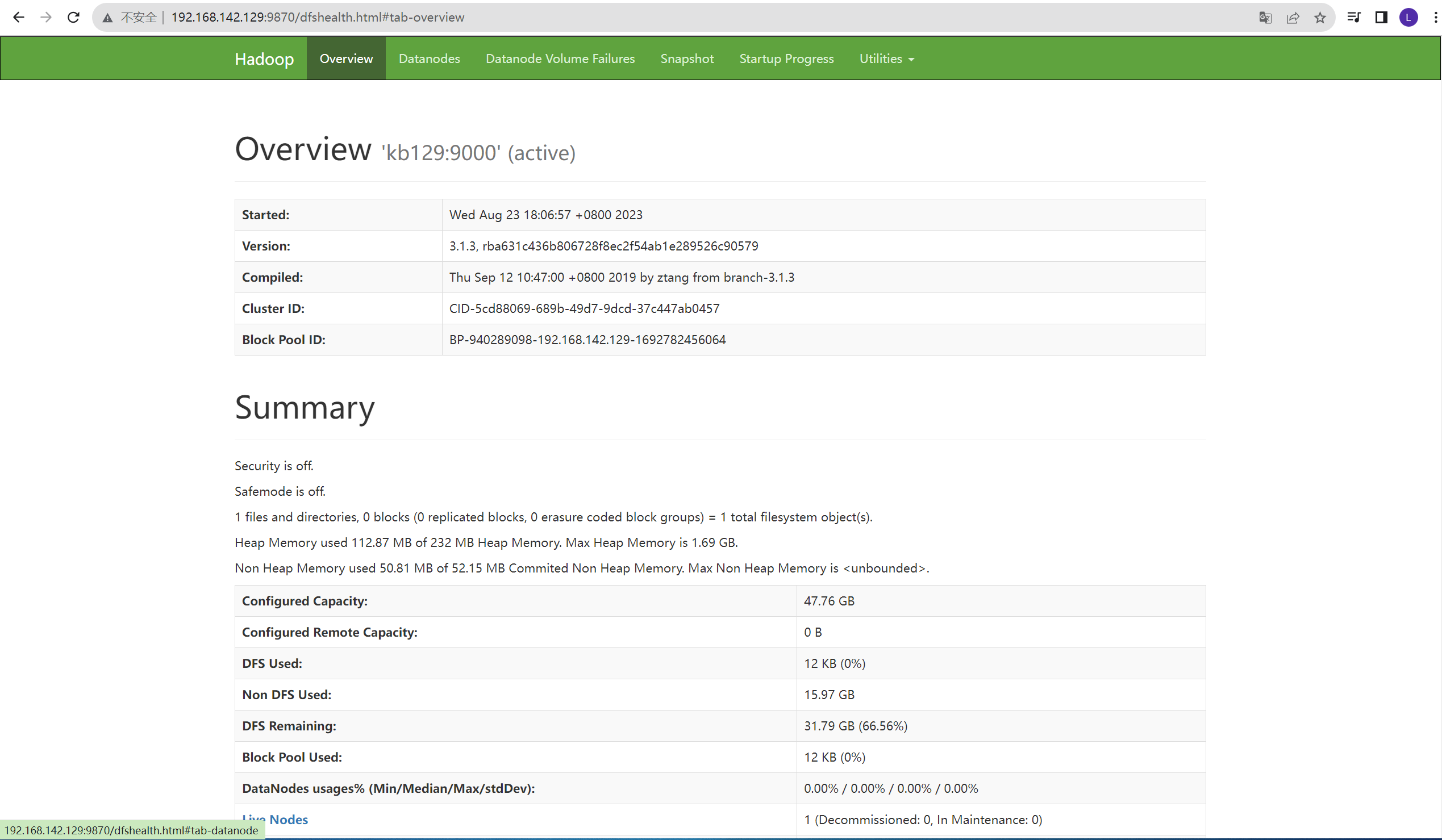
2)开始配置hdfs-site.xml 
<configuration><property><name>dfs.replication</name><value>1</value></property><property><name>dfs.namenode.name.dir</name><value>/opt/soft/hadoop313/data/dfs/name</value></property><property><name>dfs.datanode.data.dir</name><value>/opt/soft/hadoop313/data/dfs/data</value></property><property><name>dfs.permissions.enabled</name><value>false</value></property></configuration>
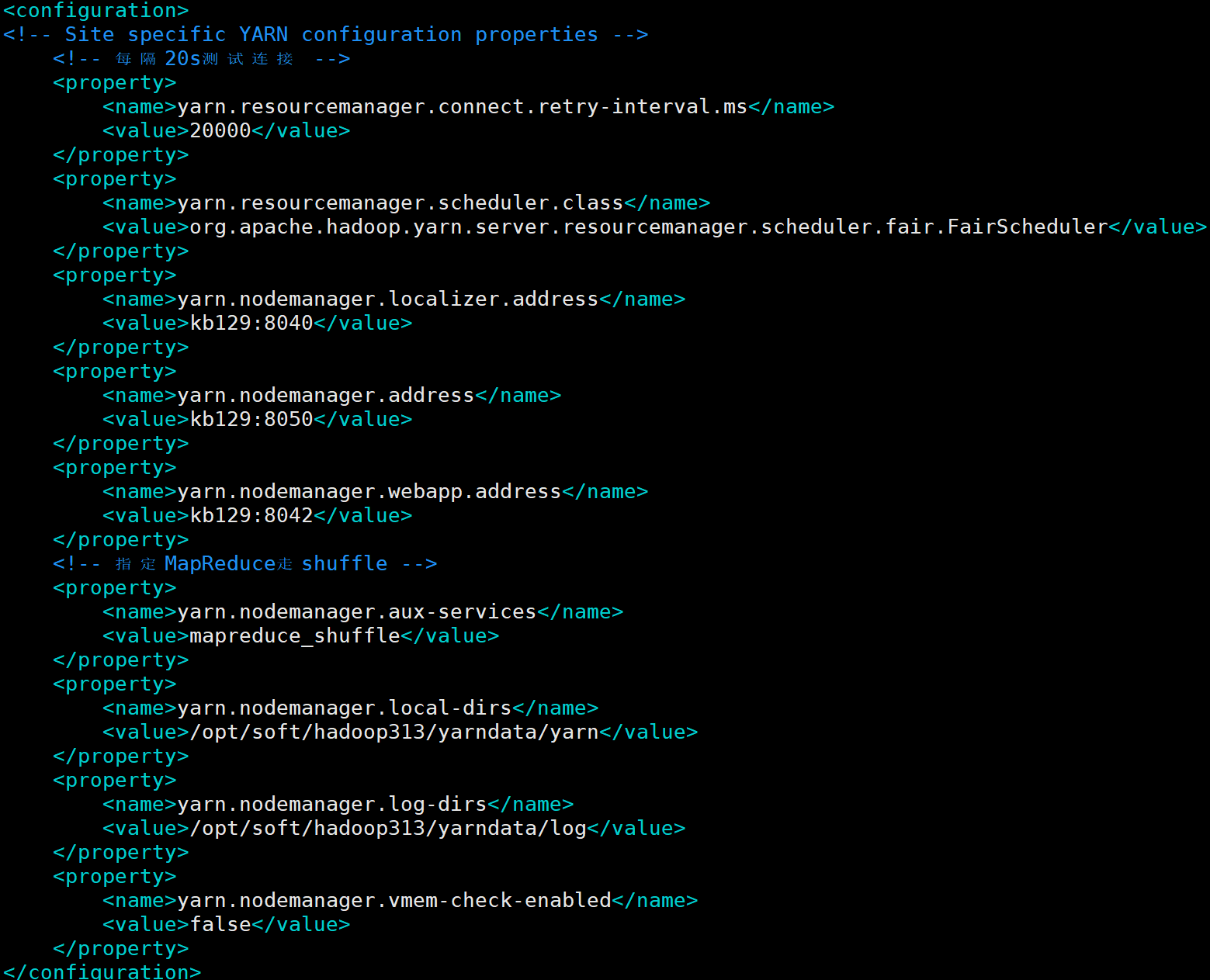
 (3)配置yarn-site.xml <configuration><!-- Site specific YARN configuration properties --><!-- 每隔20s测试连接 --><property><name>yarn.resourcemanager.connect.retry-interval.ms</name><value>20000</value></property><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value></property><property><name>yarn.nodemanager.localizer.address</name><value>kb129:8040</value></property><property><name>yarn.nodemanager.address</name><value>kb129:8050</value></property><property><name>yarn.nodemanager.webapp.address</name><value>kb129:8042</value></property><!-- 指定MapReduce走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><property><name>yarn.nodemanager.local-dirs</name><value>/opt/soft/hadoop313/yarndata/yarn</value></property><property><name>yarn.nodemanager.log-dirs</name><value>/opt/soft/hadoop313/yarndata/log</value></property><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property></configuration>
(4)配置workers更改workers内容为kb129(主机名) 
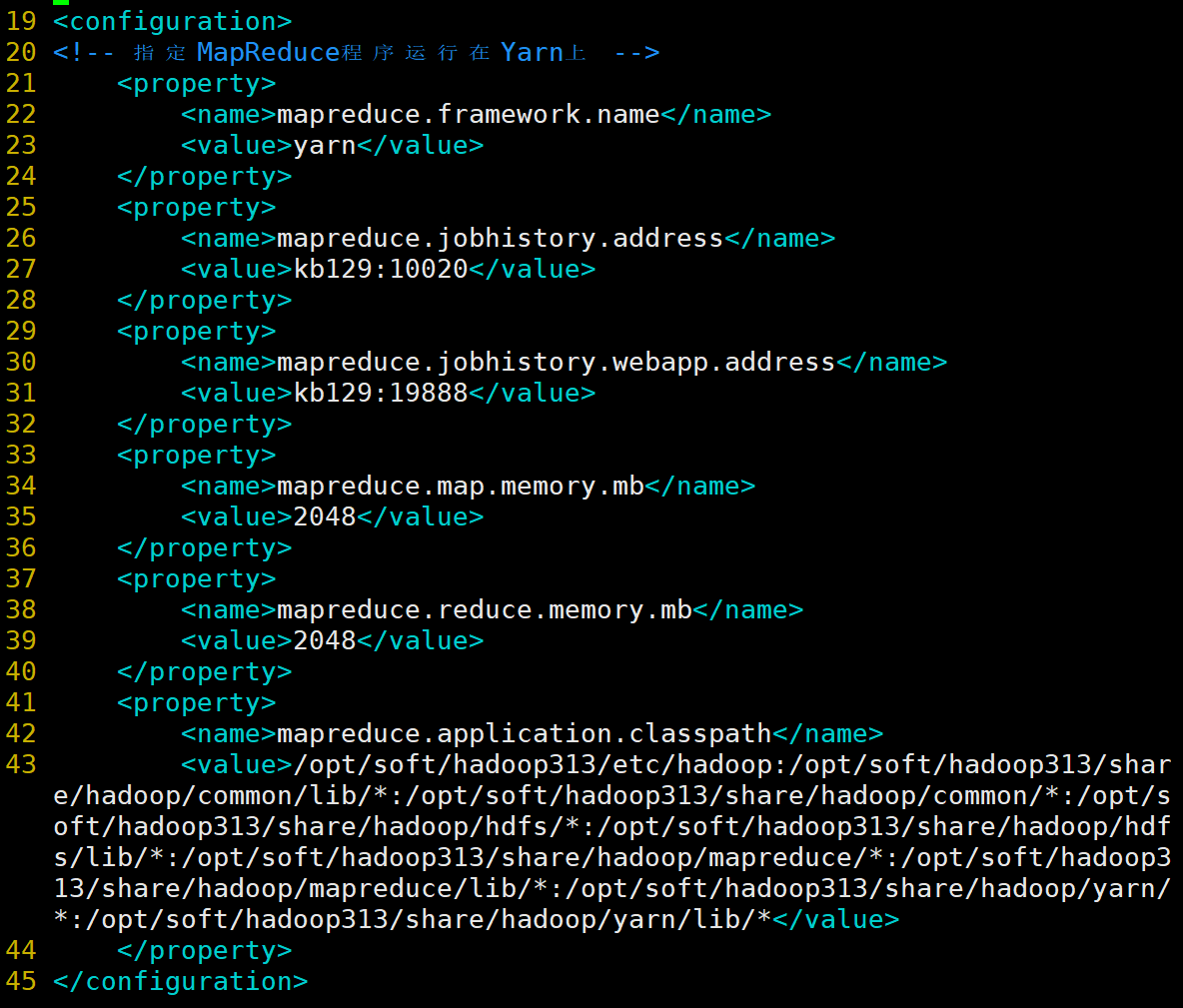
(5)配置mapred-site.xml <configuration><!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property><property><name>mapreduce.jobhistory.address</name><value>kb129:10020</value></property><property><name>mapreduce.jobhistory.webapp.address</name><value>kb129:19888</value></property><property><name>mapreduce.map.memory.mb</name><value>2048</value></property><property><name>mapreduce.reduce.memory.mb</name><value>2048</value></property><property><name>mapreduce.application.classpath</name><value>/opt/soft/hadoop313/etc/hadoop:/opt/soft/hadoop313/share/hadoop/common/lib/*:/opt/soft/hadoop313/share/hadoop/common/*:/opt/soft/hadoop313/share/hadoop/hdfs/*:/opt/soft/hadoop313/share/hadoop/hdfs/lib/*:/opt/soft/hadoop313/share/hadoop/mapreduce/*:/opt/soft/hadoop313/share/hadoop/mapreduce/lib/*:/opt/soft/hadoop313/share/hadoop/yarn/*:/opt/soft/hadoop313/share/hadoop/yarn/lib/*</value></property></configuration>
|