【业务功能篇81】微服务SpringCloud-ElasticSearch-Kibanan-docke安装-入门实战

ElasticSearch
一、ElasticSearch概述
1.ElasticSearch介绍
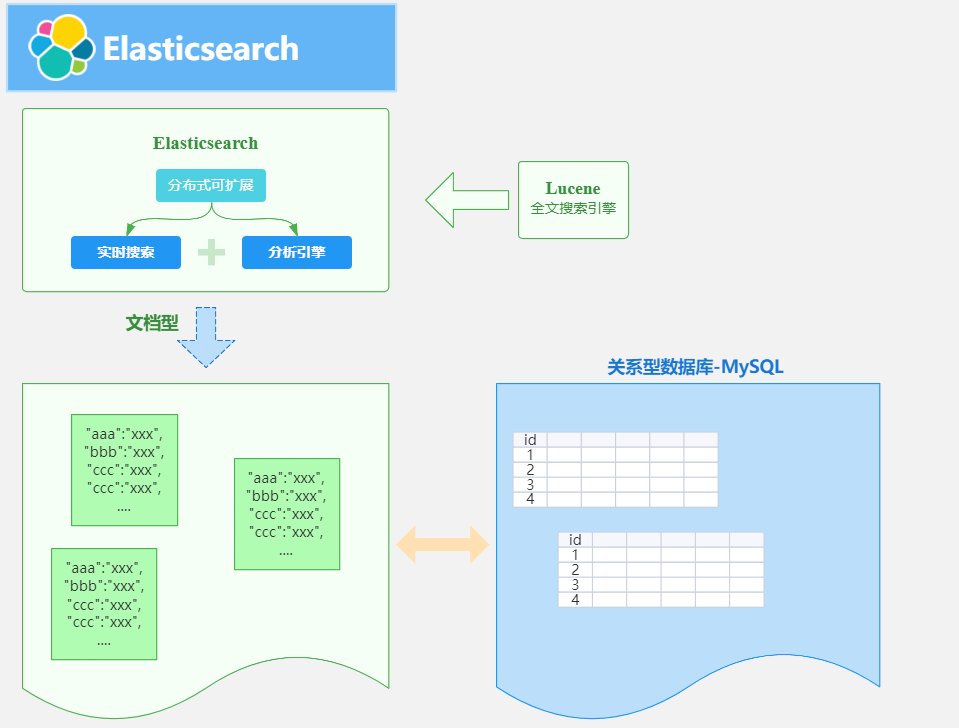
ES 是一个开源的高扩展的分布式全文搜索引擎,是整个Elastic Stack技术栈的核心。它可以近乎实时的存储,检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。
ElasticSearch的底层是开源库Lucene,但是你没办法直接用Lucene,必须自己写代码去调用它的接口,Elastic是Lucene的封装,提供了REST API的操作接口,开箱即用。天然的跨平台。
全文检索是我们在实际项目开发中最常见的需求了,而ElasticSearch是目前全文检索引擎的首选,它可以快速的存储,搜索和分析海量的数据,维基百科,GitHub,Stack Overflow都采用了ElasticSearch。
官方网站:https://www.elastic.co/cn/elasticsearch/
中文社区:https://elasticsearch.cn/explore/
2.ElasticSearch用途
- 搜索的数据对象是大量的非结构化的文本数据。
- 文件记录达到数十万或数百万个甚至更多。
- 支持大量基于交互式文本的查询。
- 需求非常灵活的全文搜索查询。
- 对高度相关的搜索结果的有特殊需求,但是没有可用的关系数据库可以满足。
- 对不同记录类型,非文本数据操作或安全事务处理的需求相对较少的情况。
3. ElasticSearch基本概念
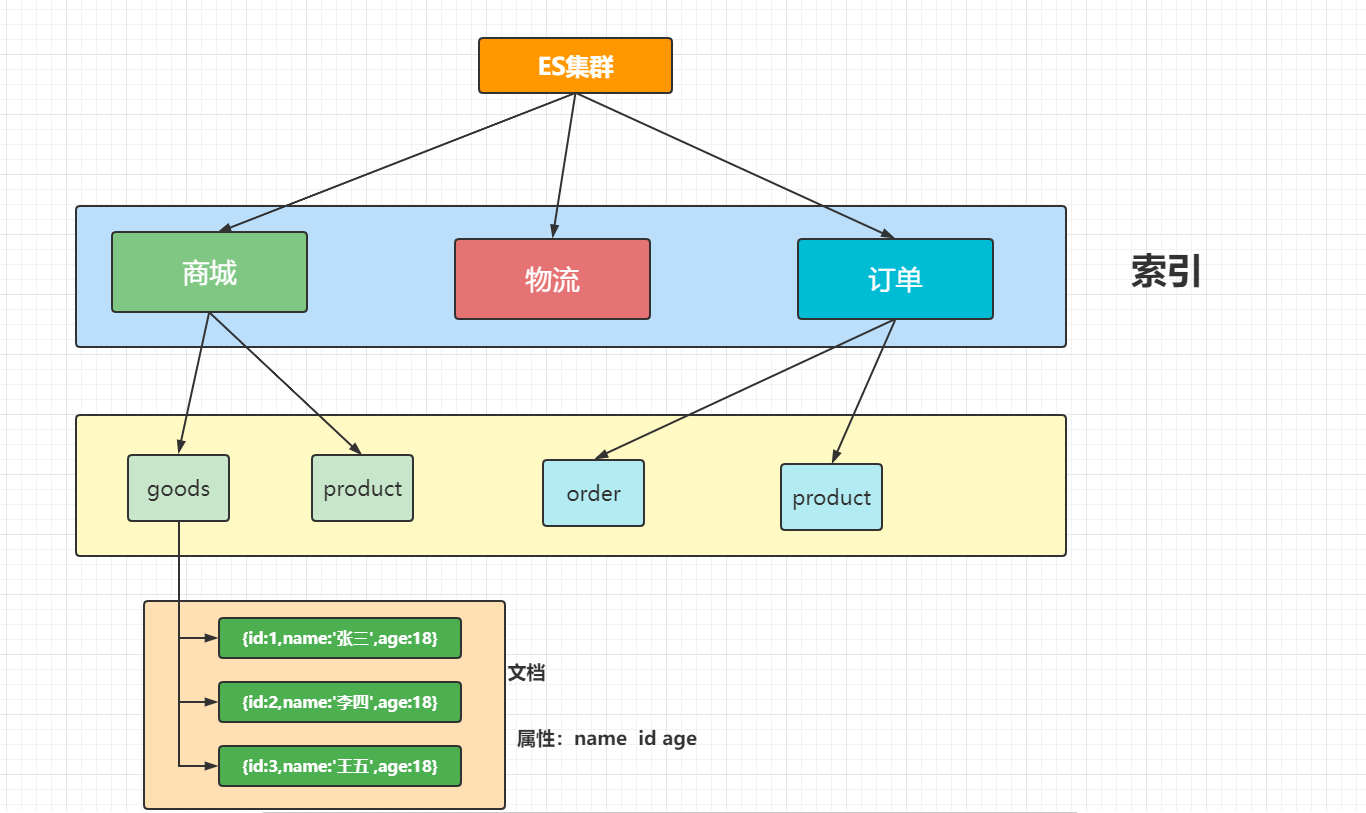
3.1 索引
索引(indices)在这儿很容易和MySQL数据库中的索引产生混淆,其实是和MySQL数据库中的Databases数据库的概念是一致的。
3.2 类型
类型(Type),对应的其实就是数据库中的 Table(数据表),类型是模拟mysql中的table概念,一个索引库下可以有不同类型的索引,比如商品索引,订单索引,其数据格式不同。
3.3 文档
文档(Document),对应的就是具体数据行(Row)
3.4 字段
字段(field)相对于数据表中的列,也就是文档中的属性。
4. 倒排索引
Elasticsearch是通过Lucene的倒排索引技术实现比关系型数据库更快的过滤。特别是它对多条件的过滤支持非常好.
倒排索引是搜索引擎的核心。搜索引擎的主要目标是在查找发生搜索条件的文档时提供快速搜索。ES中的倒排索引其实就是 lucene 的倒排索引,区别于传统的正向索引,倒排索引会再存储数据时将关键词和数据进行关联,保存到倒排表中,然后查询时,将查询内容进行分词后在倒排表中进行查询,最后匹配数据即可。
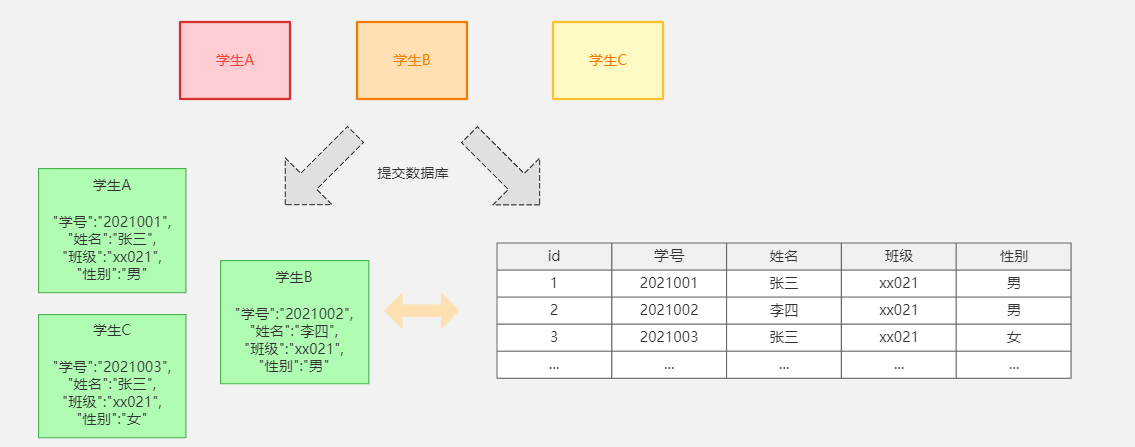
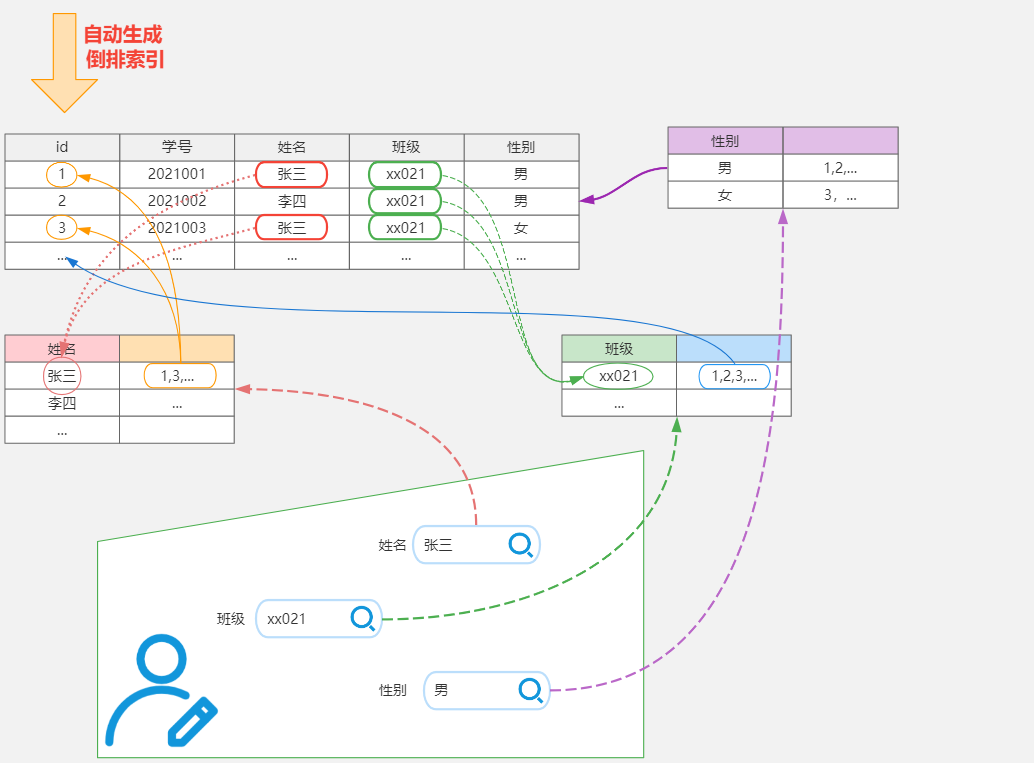
具体拆解的案例
| 词 | 记录 |
|---|---|
| 红海 | 1,2,3,4,5 |
| 行动 | 1,2,3 |
| 探索 | 2,5 |
| 特别 | 3,5 |
| 记录篇 | 4 |
| 特工 | 5 |
保存的对应的记录为
1-红海行动
2-探索红海行动
3-红海特别行动
4-红海记录篇
5-特工红海特别探索
分词:将整句分拆为单词
检索信息:
- 红海特工行动?
- 红海行动?
二、ElasticSearch相关安装
1.Elasticsearch安装
ElasticSearch安装就相当于安装MySQL数据库。
下载对应的镜像文件
docker pull elasticsearch:7.4.2
创建需要挂载的目录
mkdir -p /mydata/elasticsearch/config
mkdir -p /mydata/elasticsearch/data
echo “http.host : 0.0.0.0” >> /mydata/elasticsearch/config/elasticsearch.yml
安装ElasticSearch容器
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 -e “discovery.type=single-node” -e ES_JAVA_OPTS=“-Xms64m -Xmx128m” -v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml -v /mydata/elasticsearch/data:/usr/share/elasticsearch/data -v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins -d elasticsearch:7.4.2
启动异常:
elasticsearch.yml配置文件的 : 两边需要添加空格
还有就是访问的文件权限问题:
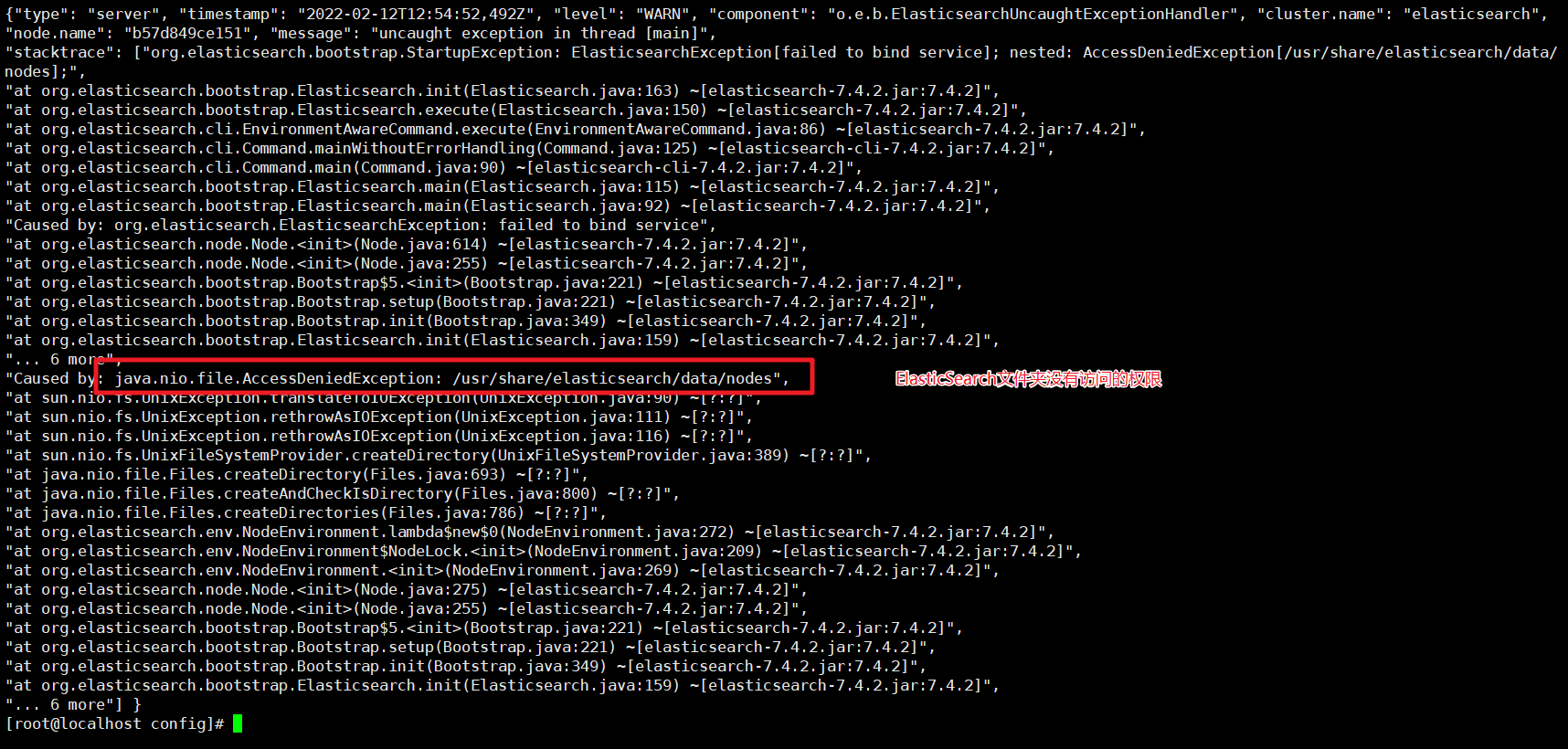
没有权限我们就添加权限就可以了
chmod -R 777 /mydata/elasticsearch/
然后我们就可以启动容器了
docker start 容器编号

然后测试访问:http://192.168.56.100:9200
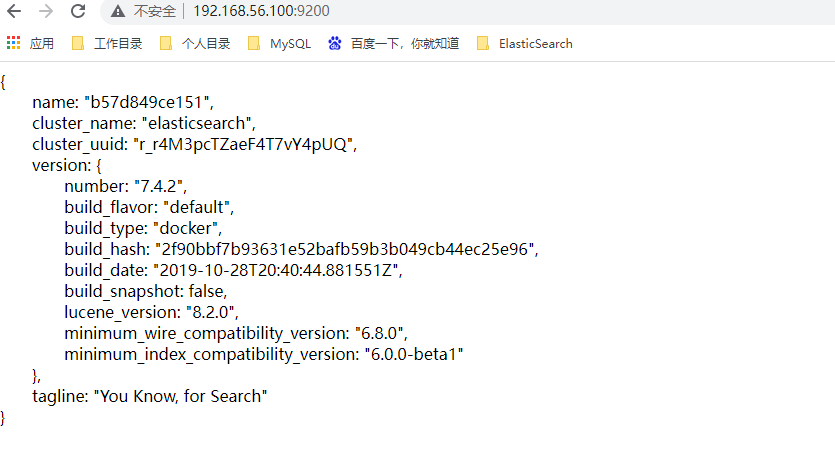
看到这个效果表示安装成功!
2.Kibana安装
Kibana的安装就相当于安装MySQL的客户端SQLYog。
下载镜像文件
docker pull kibana:7.4.2
启动容器的命令
docker run --name kibana -e ELASTICSEARCH_HOSTS=http://192.168.56.100:9200 -p 5601:5601 -d kibana:7.4.2
测试访问:http://192.168.56.100:5601
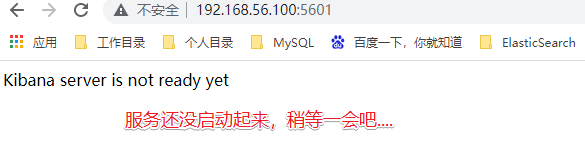
如果查看日志:docker logs 容器编号
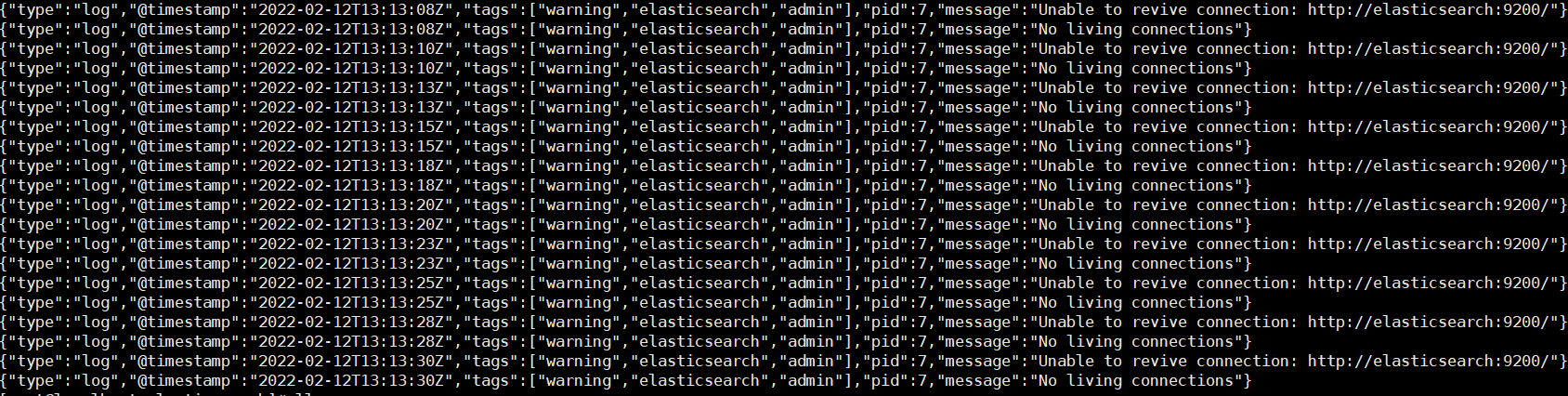
那么我们就手动的进入容器中修改ElasticSearch的服务地址
docker exec -it 容器编号 /bin/bash
进入config目录
cd config
修改kibana.yml文件中的ElasticSearch的服务地址
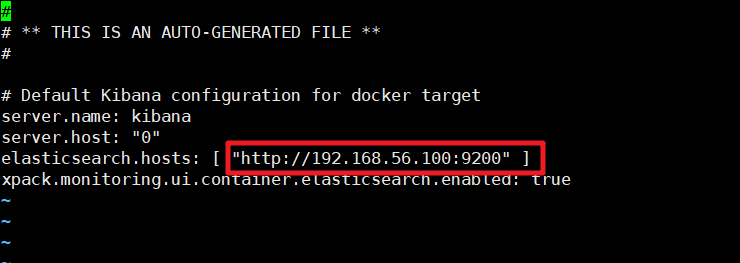
然后我们重启Kibana服务

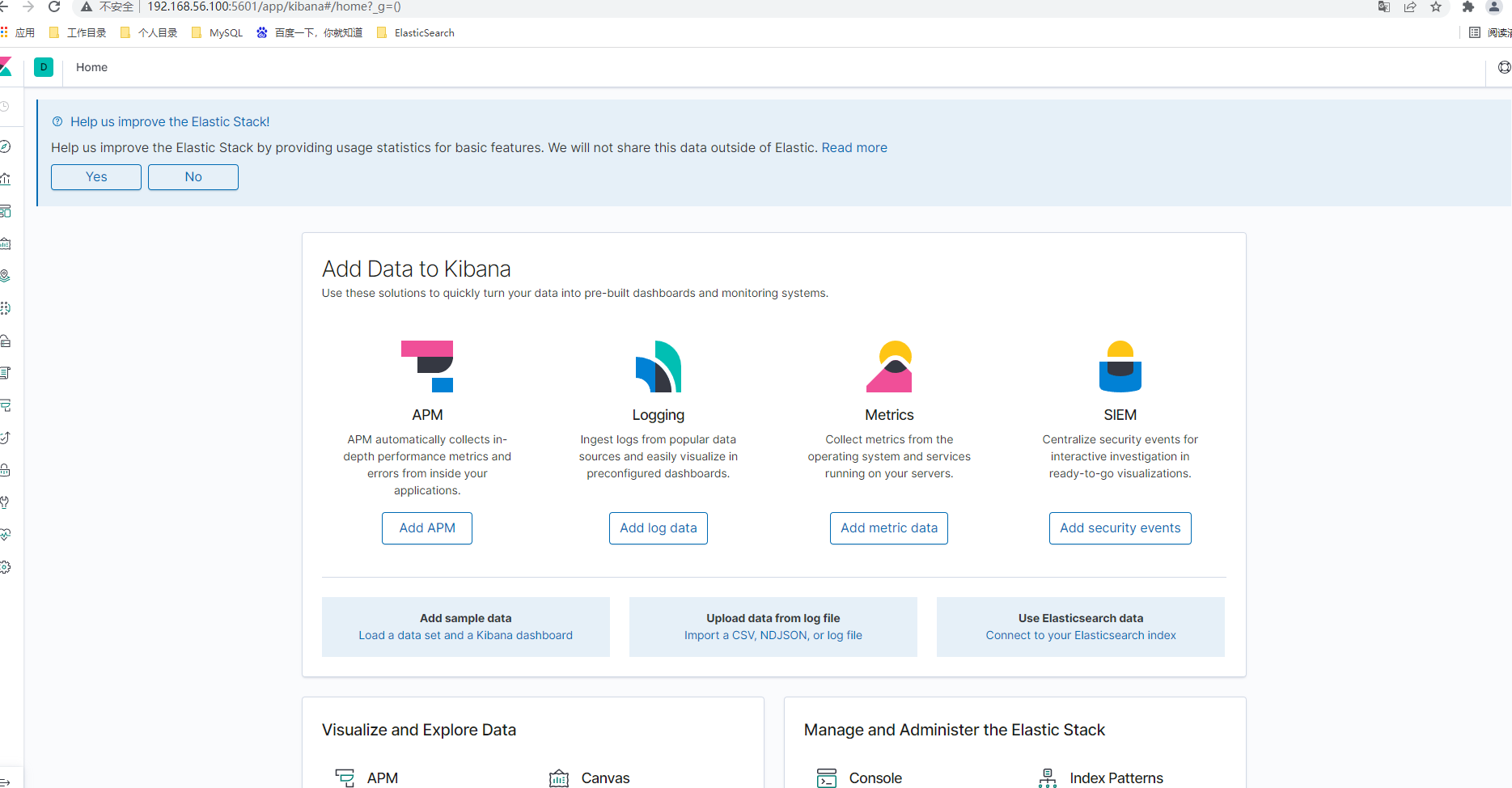
看到如下界面表示安装启动成功
三、ElasticSearch入门
1._cat
| _cat接口 | 说明 |
|---|---|
| GET /_cat/nodes | 查看所有节点 |
| GET /_cat/health | 查看ES健康状况 |
| GET /_cat/master | 查看主节点 |
| GET /_cat/indices | 查看所有索引信息 |
/_cat/indices?v 查看所有的索引信息
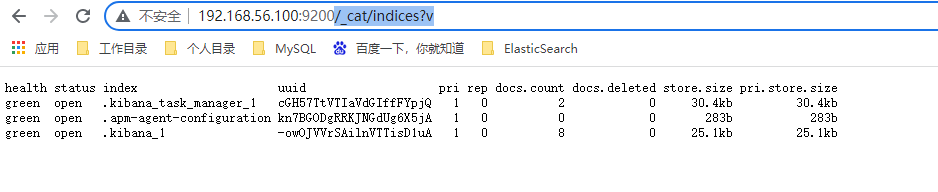
es 中会默认提供上面的几个索引,表头的含义为:
| 字段名 | 含义说明 |
|---|---|
| health | green(集群完整) yellow(单点正常、集群不完整) red(单点不正常) |
| status | 是否能使用 |
| index | 索引名 |
| uuid | 索引统一编号 |
| pri | 主节点几个 |
| rep | 从节点几个 |
| docs.count | 文档数 |
| docs.deleted | 文档被删了多少 |
| store.size | 整体占空间大小 |
| pri.store.size | 主节点占 |
2.索引操作
索引就相当于我们讲的关系型数据库MySQL中的 database
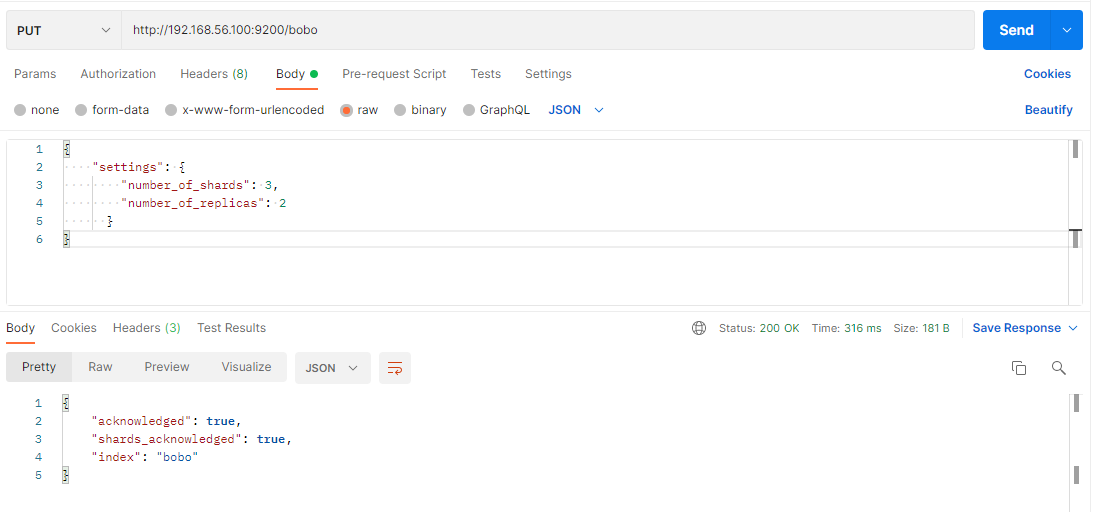
2.1 创建索引
PUT /索引名
参数可选:指定分片及副本,默认分片为3,副本为2。
{"settings": {"number_of_shards": 3,"number_of_replicas": 2}
}
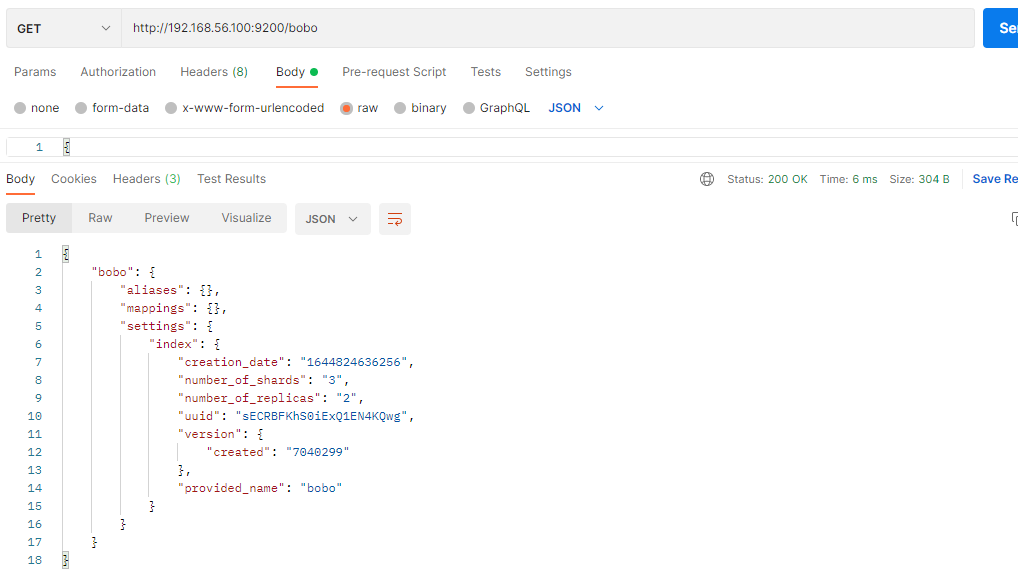
2.2 查看索引信息
GET /索引名
或者,我们可以使用*来查询所有索引具体信息
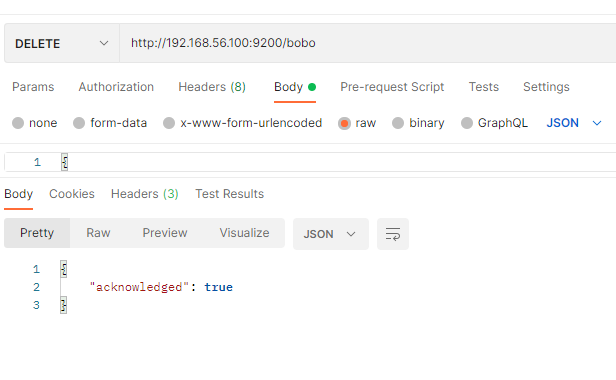
2.3 删除索引
DELETE /索引名称
3.文档操作
文档相当于数据库中的表结构中的Row记录
3.1 创建文档
PUT /索引名称/类型名/编号
数据
{"name":"bobo"
}
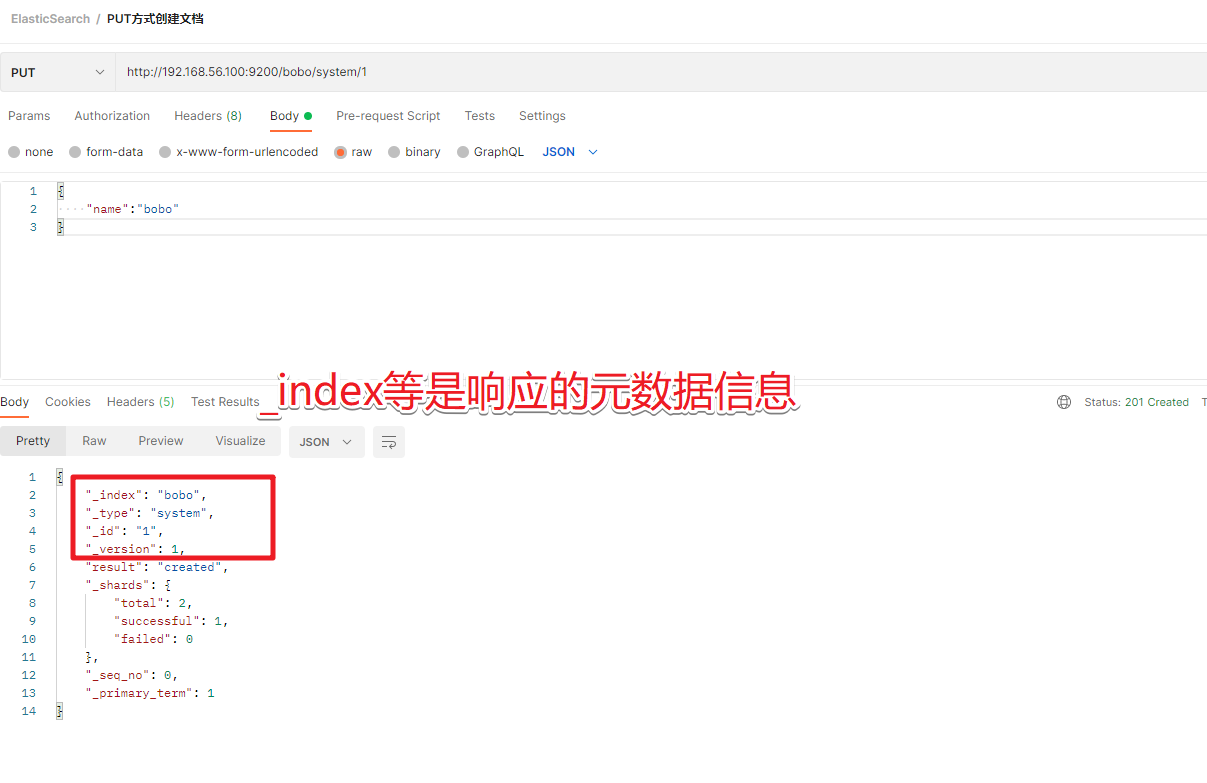
| 提交方式 | 描述 |
|---|---|
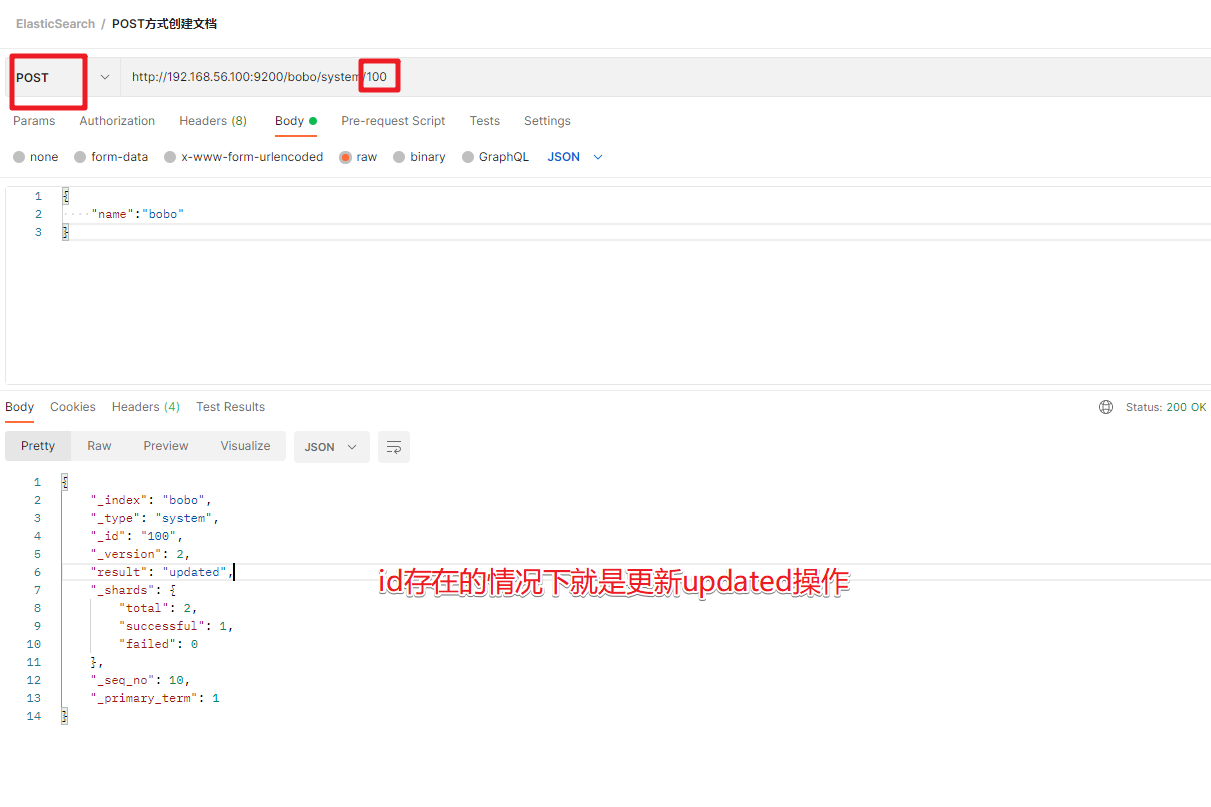
| PUT | 提交的id如果不存在就是新增操作,如果存在就是更新操作,id不能为空 |
| POST | 如果不提供id会自动生成一个id,如果id存在就更新,如果id不存在就新增 |
POST /索引名称/类型名/编号
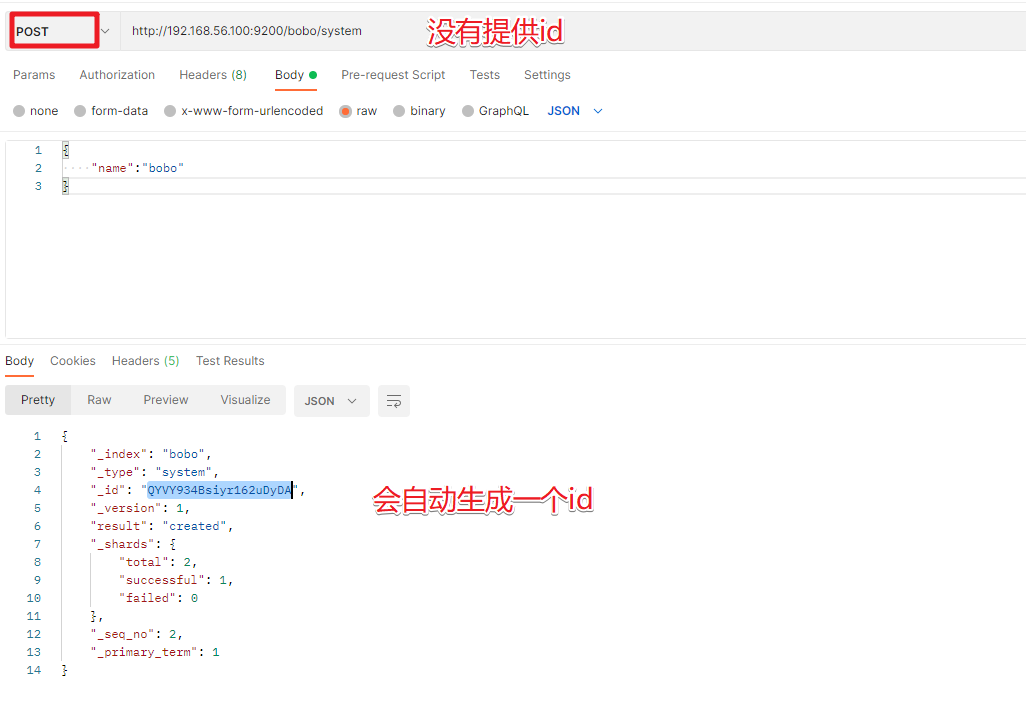
3.2 查询文档
GET /索引/类型/id
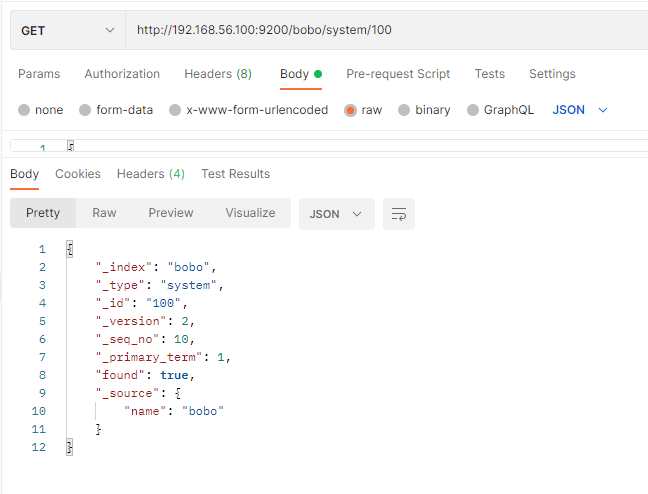
返回字段的含义
| 字段 | 含义 |
|---|---|
| _index | 索引名称 |
| _type | 类型名称 |
| _id | 记录id |
| _version | 版本号 |
| _seq_no | 并发控制字段,每次更新都会+1,用来实现乐观锁 |
| _primary_term | 同上,主分片重新分配,如重启,就会发生变化 |
| found | 找到结果 |
| _source | 真正的数据内容 |
乐观锁: ?if_seq_no=0&if_primary_term=1
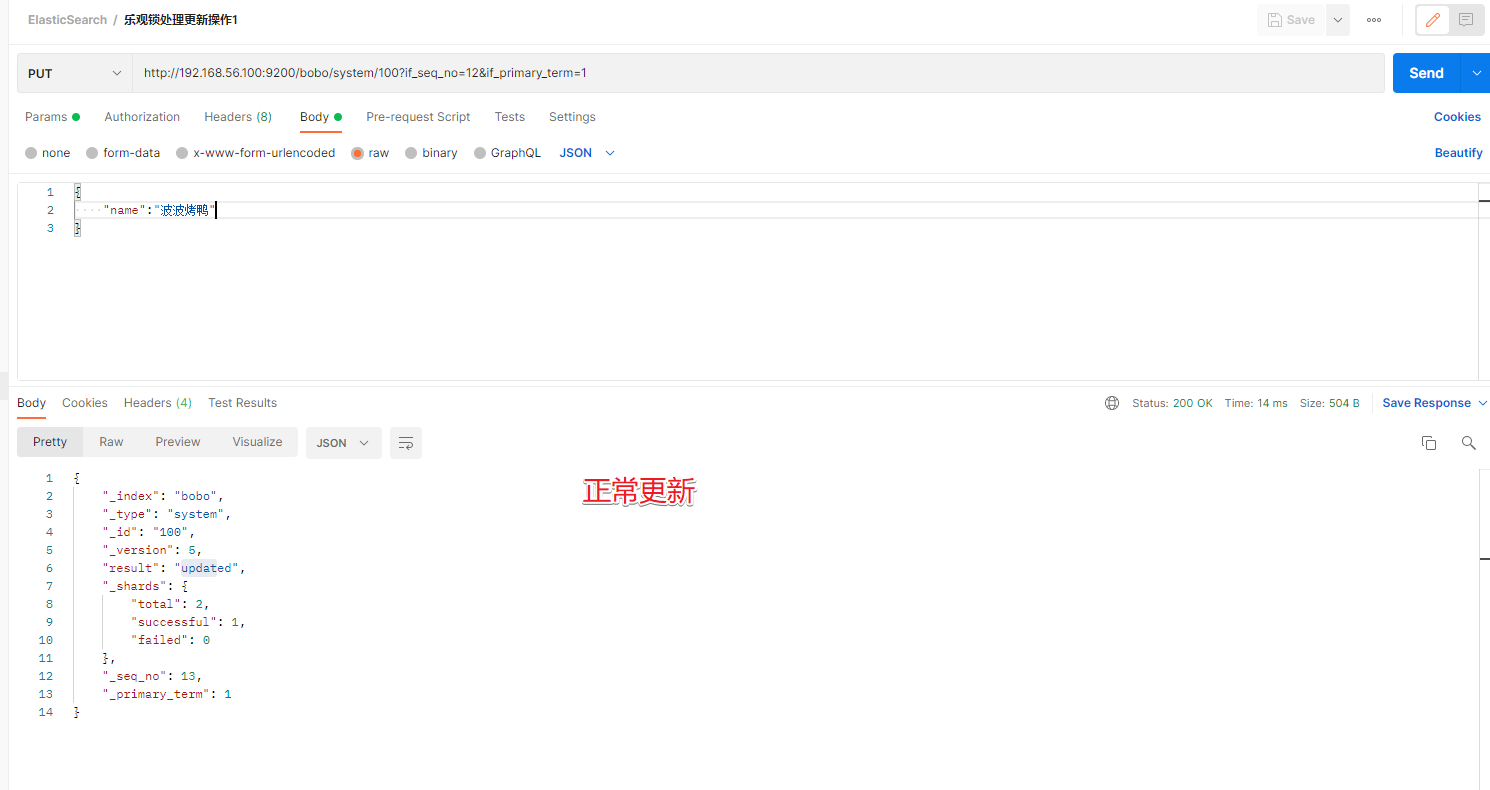
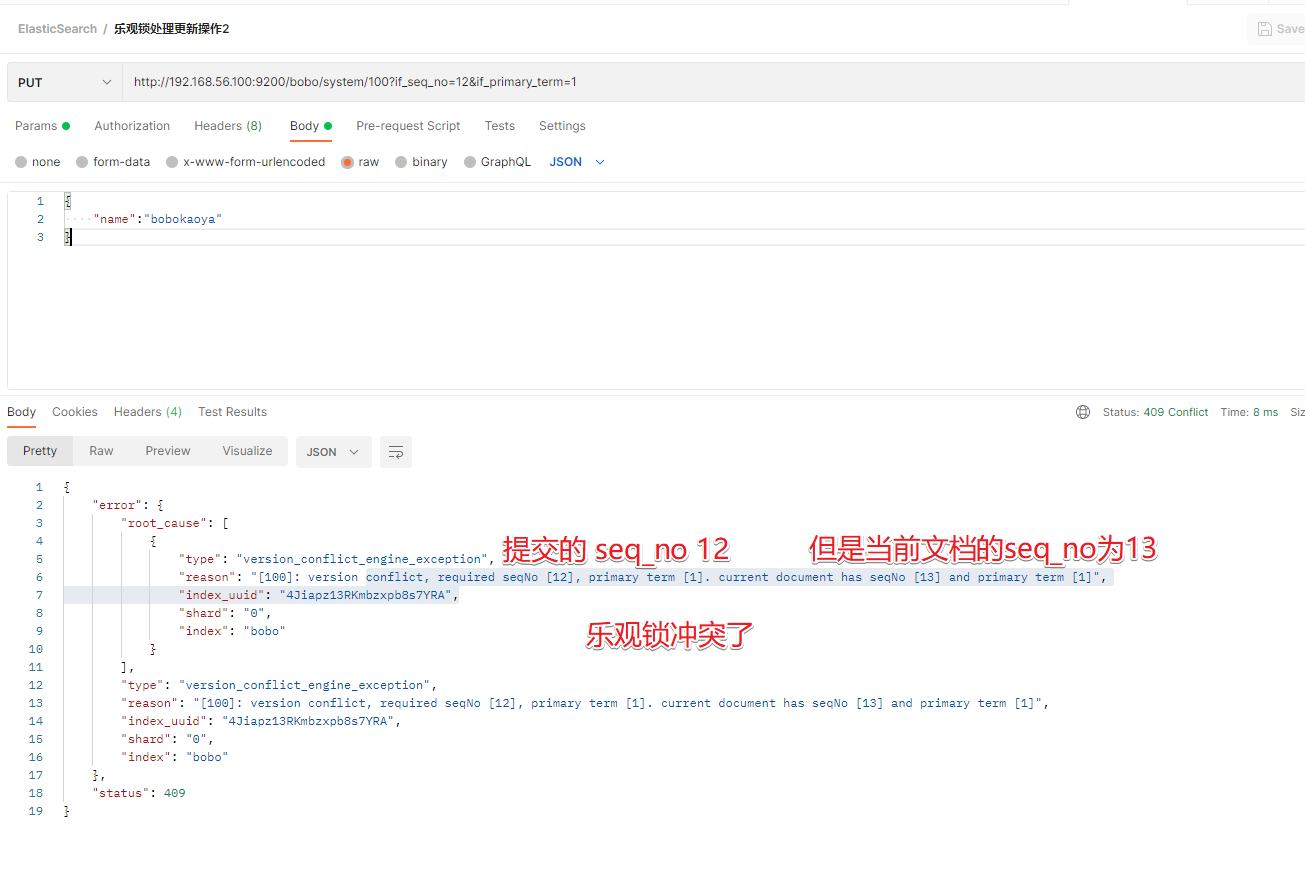
3.3 更新文档
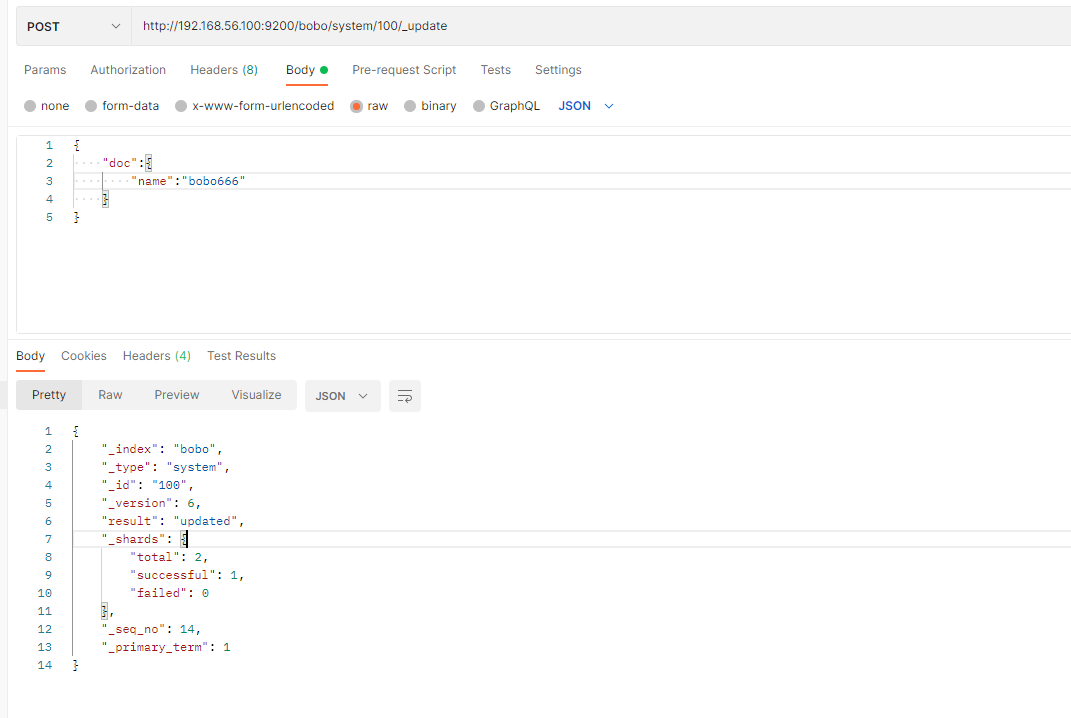
前面的POST和PUT添加数据的时候,如果id存在就会执行更新文档的操作,当然我们也可以通过POST方式提交,然后显示的跟上_update来实现更新
POST /索引/类型/id/_update
{"doc":{"name":"bobo666"}
}
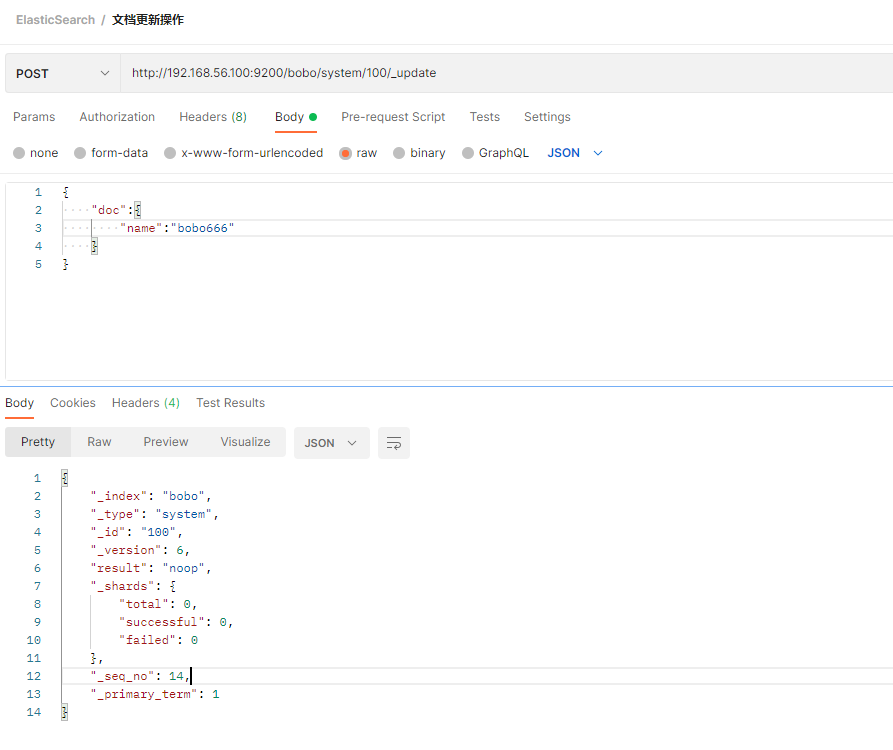
这种方式来更新,只是这种方式的更新如果数据没有变化则不会操作。
如果更新的数据和文档中的数据是一样的,那么POST方式提交是不会有任何操作的
3.4 删除文档
DELETE /索引/类型/id
DELETE /索引
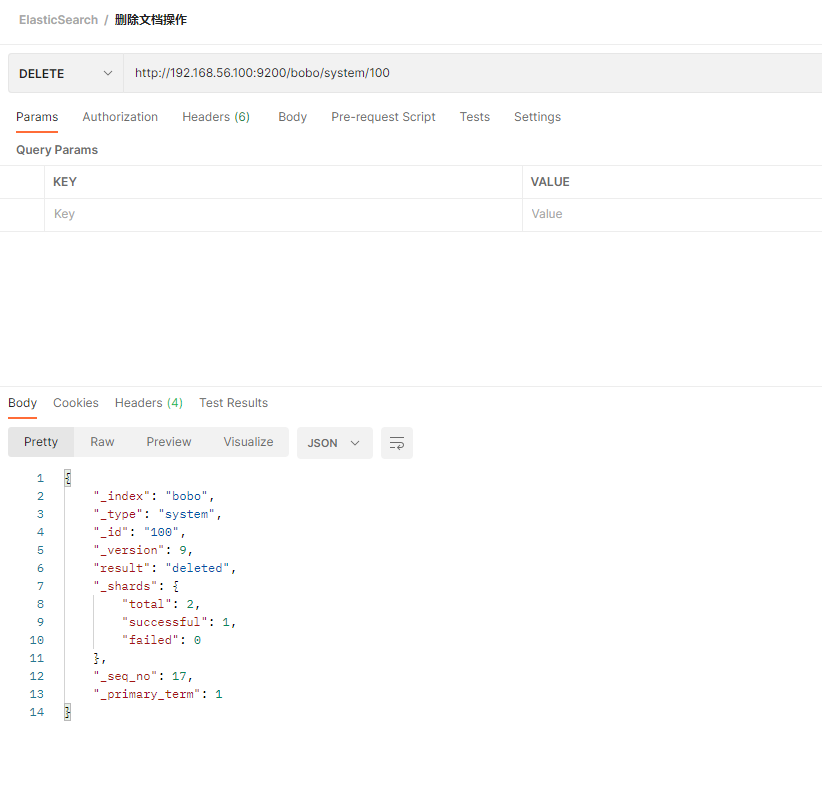
3.5 测试数据
_bulk批量操作,语法格式
{action:{metadata}}\n
{request body }\n
{action:{metadata}}\n
{request body }\n
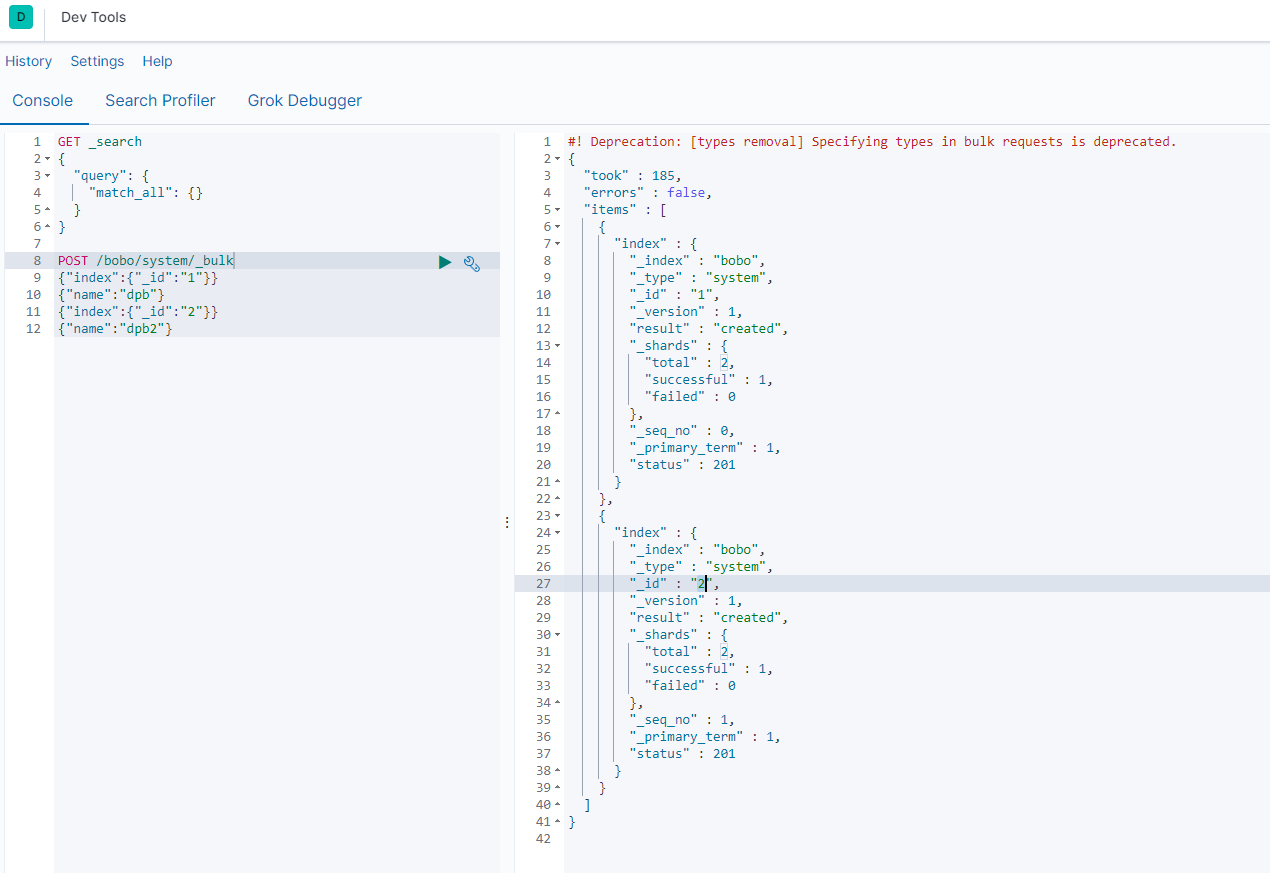
案例
POST /bobo/system/_bulk
{"index":{"_id":"1"}}
{"name":"dpb"}
{"index":{"_id":"2"}}
{"name":"dpb2"}
复杂点的案例:
POST /_bulk
{"delete":{"_index":"website","_type":"blog","_id":"123"}}
{"create":{"_index":"website","_type":"blog","_id":"123"}}
{"title":"My first bolg post ..."}
{"index":{"_index":"website","_type":"blog"}}
{"title":"My second blog post ..."}
{"update":{"_index":"website","_type":"blog","_id":"123"}}
{"doc":{"title":"My updated blog post ..."}}官方测试数据:https://github.com/elastic/elasticsearch/blob/master/docs/src/test/resources/accounts.json