第6步---MySQL的控制流语句和窗口函数
第6步---MySQL的控制流语句和窗口函数
1.IF关键字
-- ==================控制流语句=================
SELECT IF('5>3','大于','小于');-- 会单独生成一列的
SELECT *,IF(score >90 , '优秀', '一般') '等级' FROM stu_score;-- IFNULL(expr1,expr2)
SELECT id,name ,IFNULL(salary,0),dept_id FROM emp4;-- ISNULL() 判断某个值是不是null
-- 0 表示不是null
SELECT ISNULL(11);
SELECT ISNULL(NULL);-- NULLIF(expr1,expr2)-- 一样的返回null
SELECT NULLIF(12,12);-- 不一样返回第一个的值
SELECT NULLIF(12,1)2.CASE关键字
语法格式:
会依次判断下面的值要是相等的话就会进行输出的
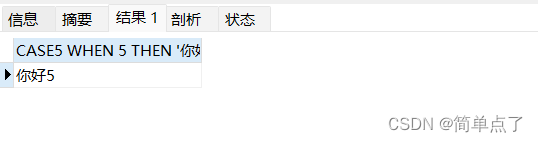
SELECT
CASE5 WHEN 5 THEN '你好5' WHEN 4 THEN '你好4' ELSE 'hi'
END ;
-- 设置显示的别名
SELECT
CASE5 WHEN 5 THEN '你好5' WHEN 4 THEN '你好4' ELSE 'hi'
END as info;

-- 创建一个新的数据库orders
CREATE TABLE `orders` (`id` int(11) NOT NULL AUTO_INCREMENT,`price` double DEFAULT NULL,`pay_type` int(11) DEFAULT NULL,PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;插入下面的语句
INSERT INTO `sys_test`.`orders` (`id`, `price`, `pay_type`) VALUES (1, 1200, 1);
INSERT INTO `sys_test`.`orders` (`id`, `price`, `pay_type`) VALUES (2, 1000, 2);
INSERT INTO `sys_test`.`orders` (`id`, `price`, `pay_type`) VALUES (3, 200, 3);
INSERT INTO `sys_test`.`orders` (`id`, `price`, `pay_type`) VALUES (4, 3000, 1);
INSERT INTO `sys_test`.`orders` (`id`, `price`, `pay_type`) VALUES (5, 1500, 2);
后面的支付方式采用的都是不同的编号进行设置的支付的方式
1:微信支付2:支付宝支付3:银行卡支付4:其他
-- 查看订单的支付的方式
SELECT id,price, pay_type,
CASE pay_typeWHEN 1 THEN '支付宝'WHEN 2 THEN '微信'WHEN 3 THEN '银联'ELSE'未知支付方式'
END as '支付方式'FROM orders;
3.窗口函数

比原先的聚合函数更加强大不仅可以看见原始的数据还可以看见转换之后的数据。
具有开窗聚合函数的作用。
window FUNCTION (expr ) over(PRIMARY KEY
ORDER BY
...
)
-- 序号函数
SELECT * FROM emp4;-- 对每个部门员工按照薪资进行排序
SELECT id,name ,salary,dept_id ,ROW_NUMBER() over(PARTITION by dept_id ORDER BY salary DESC ) AS rn1,
RANK() over(PARTITION by dept_id ORDER BY salary DESC ) AS rn2,
DENSE_RANK() over(PARTITION by dept_id ORDER BY salary DESC ) AS rn3
FROM emp4;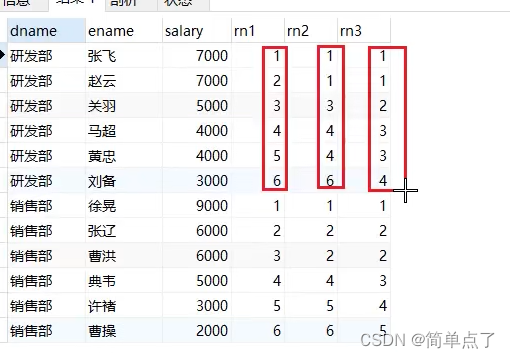
都能实现相同的效果,区别在于后面的参数的值设置的时候是不是相同的值。
-- 分组求topN
SELECT * FROM (
SELECT id,name ,salary,dept_id ,
DENSE_RANK() over(PARTITION by dept_id ORDER BY salary DESC ) AS rn3
FROM emp4) t
WHERE t.rn3<=3 ;
4.分布函数
cume_dist和percent_rank
用途:分组内小于 等于当前rank值得行数/分组内得总行数。
场景:查询小于当前薪资得比例
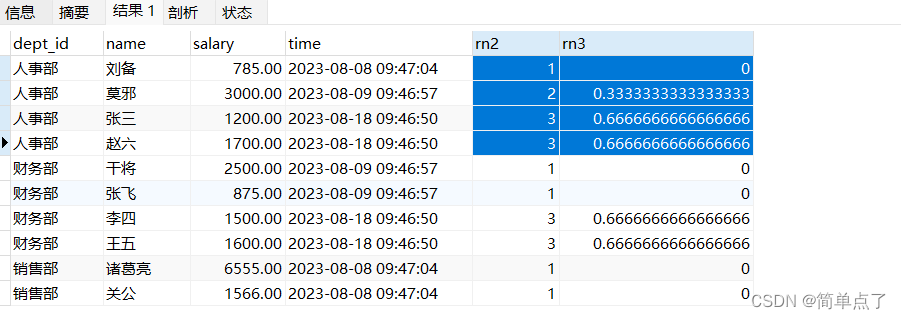
-- 薪资比例
SELECT dept_id,name ,salary,time ,
CUME_DIST() over(PARTITION by dept_id ORDER BY time) AS rn3
FROM emp4;

计算的是小于自己得薪资得人数得比例的关系。
PERCENT_RANK函数
这个函数的用处不是很大
SELECT dept_id,name ,salary,time ,
rank() over(PARTITION by dept_id ORDER BY time) AS rn2,
PERCENT_RANK() over(PARTITION by dept_id ORDER BY time) AS rn3
FROM emp4;
5.前后函数
-- 前后函数
SELECT dept_id,name ,salary,time ,
LAG(time ,1,'2023-08-18') over(PARTITION by dept_id ORDER BY time) AS rn2,
LAG(time ,2) over(PARTITION by dept_id ORDER BY time) AS rn3
FROM emp4;-- 前后函数
SELECT dept_id,name ,salary,time ,
lead(time ,1,'2023-08-18') over(PARTITION by dept_id ORDER BY time) AS rn2,
lead(time ,2) over(PARTITION by dept_id ORDER BY time) AS rn3
FROM emp4;
6.头尾函数
-- 到目前为止 按照日期进行排序找到第一个入职的和最后一个入职的员工的薪资
-- 到目前为止 按照日期进行排序找到第一个入职的和最后一个入职的员工的薪资
SELECT dept_id,name ,salary,time ,
FIRST_VALUE(salary)over(PARTITION by dept_id ORDER BY time) AS rn2,
LAST_VALUE(salary) over(PARTITION by dept_id ORDER BY time) AS rn3
FROM emp4;
7.开窗聚合函数
-- 按照入职时间排序并求工资的和
SELECT dept_id,name ,salary,time ,
sum(salary) over(PARTITION by dept_id ORDER BY time ) AS rn3
FROM emp4;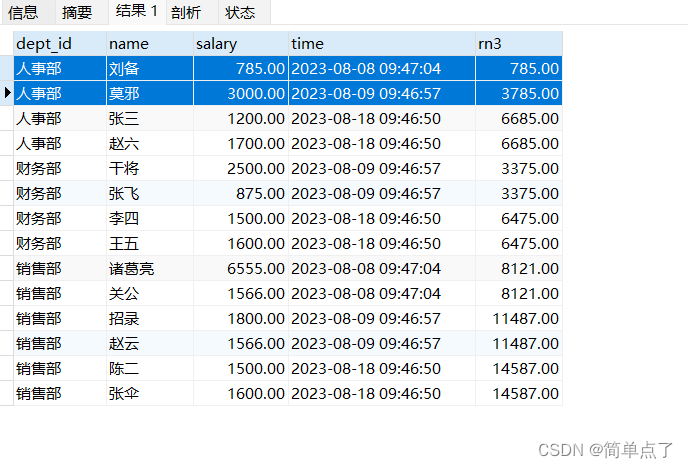
-- 按照入职时间排序并求工资的和
-- 从开始加到当前行 rows BETWEEN unbounded preceding and current row
SELECT dept_id,name ,salary,time ,
sum(salary) over(PARTITION by dept_id ORDER BY time rows BETWEEN unbounded preceding and current row ) AS rn3
FROM emp4;-- 往上3行加到当前行
SELECT dept_id,name ,salary,time ,
sum(salary) over(PARTITION by dept_id ORDER BY time rows BETWEEN 3 preceding and current row ) AS rn3
FROM emp4;-- 往上3行往后加一行
SELECT dept_id,name ,salary,time ,
sum(salary) over(PARTITION by dept_id ORDER BY time rows BETWEEN 3 preceding and 1 following ) AS rn3
FROM emp4;
上面的开窗聚合函数可以实现复杂的聚合的操作。
8.NTH_VALUE窗口函数
-- 截至到当前排名是多少的
SELECT dept_id,name ,salary,time ,
NTH_VALUE(salary,2) over(PARTITION by dept_id ORDER BY time) AS rn2,
NTH_VALUE(salary,1)over(PARTITION by dept_id ORDER BY time) AS rn3
FROM emp4;-- 按照入职时间分成3组
SELECT dept_id,name ,salary,time ,
ntile(3)over(PARTITION by dept_id ORDER BY time) AS rn3
FROM emp4;-- 按照入职时间分成3组 取出第一组员工
SELECT * FROM(
SELECT dept_id,name ,salary,time ,
ntile(3)over(PARTITION by dept_id ORDER BY time) AS rn3
FROM emp4
) t WHERE t.rn3=1;