人工智能大模型加速数据库存储模型发展 行列混合存储下的破局

数据存储模型
专栏内容:
- postgresql内核源码分析
- 手写数据库toadb
- 并发编程
- toadb开源库
个人主页:我的主页
座右铭:天行健,君子以自强不息;地势坤,君子以厚德载物.
概述
在数据库的发展过程中,关系型数据库是一个里程碑式的阶段,现在关系型数据仍然占据着重要地位。
在关系型数据中,每张表都是一个关系,每行数据就是关系的一条记录,在存储时每行数据存储在连续的位置,行与行也是连续存放;
这样方便一次能拿到一整条记录。
处理业务类型
随着互联网的兴起,存储容量的提升和计算能力的飞越,我们的生活中不断增加了越来越多的被智能设备,产生了无尽的信息。
这样的信息规模已经超越了某一单体的能力限制,它们被不断分类,对于数据库处理模型,常常分为:
- 在线事务处理模型(OLTP), 主要以事务一致性,关系型数据为主;
- 在线分析处理模型(OLAP), 主要以分析统计为主,更多的是从大量数据中提取某几个维度的数据;
但是这样的划分,还远远不能满足信息爆炸带来的需求,它不是非黑即白的界线明晰的分类,还有大量同时存在OLTP和OLAP的特点的数据和业务,此时就需要一种混合性数据库存储模型。
数据存储模型原理
是什么
通过SQL插入的数据,在数据库中实际也是要存到磁盘上的,此时还要考虑我们写入的效率,读取的效率,如何产生的IO次数更少,那以什么格式组织这些数据,才能达到这样的目标呢?
我们使用的文件系统,都是以块为单位进行读写物理存储设备,常用的块大小有2k, 4k等;那么数据库为了提升性能,也选择以块为单位来组织数据,每次按块进行读写数据文件。
每个数据块内又分为:块头信息域,数据域的起始偏移,数据域,在数据域中按逻辑表的行进行连续存储。当然行数据,又分为定长或变长两种不同的组织方式;定长,就是每种数据类型固定了长度,这样一行数据的长度也是确定的;变长类型,就是像字符,文本等长度是可变的,那么存储时需要记录长度。
它们最大的区别在于更新时,定长是可以直接覆盖更新的,而变长就需要追加更新。
为什么存储模型这么重要
因为我们的存储到数据库中的数据都是持久化到磁盘中,当我们查询时,再从磁盘中读出,
虽然我们数据库和操作系统层面都已经做了缓存,当数据量大时还是会产生大量的磁盘IO,而且数据库大多数情况下都是随机访问,缓存并不保证全部命中。相较与内存速度来讲,磁盘速度是极底的,但是内存往往是有限的,所以存储模型至关重要,通过将随机写转换为顺序写,少的IO就可以精确找到数据,减少遍历,这些都可以做到减少IO次数,提升性能。
数据存储模型类型
NSM模型
故名思义,就是按行数据排列的数组形式, 数据的物理结构和他们的逻辑结构是一样的,也就是我们常说的行存储模型,这也是大多数关系型数据库采用的存储模型。
物理存储结构
磁盘是由一个一个数据块组成的,因此连续的数据也分在了连续的数据块。
每个数据块中又分块头信息,记录块中数据的起始偏移,每行数据分为 行的数据偏移item,从块头后面连续存储, 以及真正的行数据,它从块的末尾开始向头部方向连续存储,这是为了方便空闲空间的管理。表数据与物理存储结构对应 如下图所示 :
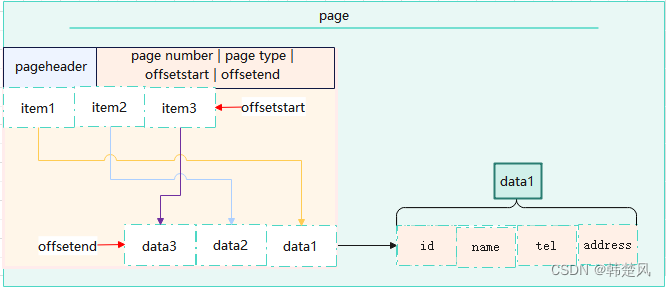
应用场景
- 它的优势在于对关联数据的查询非常快,比如根据身份证号就可以一次读出姓名,住址等一系列信息。
在此基础上对于复杂的嵌套join就非常有优势,因为它的各列数据都在一起。
不适合场景
- 对于只查找部分列属性数据的业务,就会增加IO的成本,它需要全行数据的读出。对于按3NF设计,还是一张大宽表,都避免不了缓存效率的降低。
DSM模型
分解的存储模型,也就是将一行中的各字段存储到不同的数据单元中,当需要某列数据时,只从磁盘加载部分数据,如果需要整行数据,那就加载全量数据,然后进行行组装。
可以是每一列都分别存储,也可以根据业务需要不规则的划分,比如有三列经常会相时查询,那这三列可以一起存储,剩余的列分别存储。
物理存储结构
常见的格式有:
- PAX
- RCFile(record columnar file)
- Apache ORC
- Parquet (An Open Columnar Storage for Hadoop)
它们中更多偏向分析型列式存储,可以处理大量的时序,流式数据,也有一些偏向于行列的混合型,每种格式都有成熟的产品应用。
应用场景
它们的场景更多偏向分析型,如hdoop系列的,使用ORC, Parquet。
混合型数据存储模型
为了综合以上NSM和DSM各自的优势,互补长短,目前一些数据库已经采用了一些混合的存储模型。
常见混合模型实践
- 数据冗余型
在存储数据时,干脆两种格式同时进行存储,一种按行进行存储,一种按列分别存储,这样避免了转换带的复杂度,用空间来换取性能;在优化引擎中可以选择更适合的路径;
- 数据转换型
因为行存必须带来IO的放大,也以实际存储采用列式存储,在使用时进行组装成逻辑行数据;这种模型的难点在于,如何准确的找到逻辑行中的各字段,大多都采用PAX中提到的分组的方式。
难点
在大数据处理中,已经不局限于关系型数据,更多的是非关系型,如文本,json数据,如何将它们转换成列数据,可以快速查找,这将是混合型存储模型面临的一项挑战。
最近兴起的向量数据量,向量与大模型维度是对应的,底层数据库存储就需要将各类型数据进行分别存储。
结尾
非常感谢大家的支持,在浏览的同时别忘了留下您宝贵的评论,如果觉得值得鼓励,请点赞,收藏,我会更加努力!
作者邮箱:study@senllang.onaliyun.com
如有错误或者疏漏欢迎指出,互相学习。
注:未经同意,不得转载!