深度学习1:通过模型评价指标优化训练
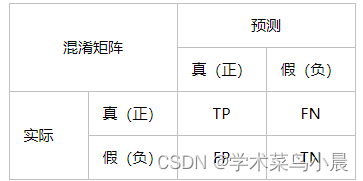
P(Positive)表示预测为正样本,N(negative)表示预测为负样本,T(True)表示预测正确,F(False)表示预测错误。
TP:正样本预测正确的数量(正确检测)
FP:负样本预测正确数量(误检测)
TN:负样本预测错误数量
FN:正样本预测错误的数量(漏检测)
1.准确率:正确样本占总样本的比例
Accuracy=(TP+TN)/(TP+TN+FP+FN)
2.精确率:正样本预测正确占正样本的比例
precision=(TP)/(TP+FP)
精确度低,召回率高的解决办法:
模型把大量背景(负样本)错判成目标(正样本 )。
主要原因不外乎数据本身有问题:1、图片上目标没有标全,有大量没标注的 ,这样会导致模型其实学到了目标物特征,但是真值是负样本(没有标注);2、图片上目标标的太仔细,把非常小像素的目标(特征跟背景相差不大)都标了,这样也会导致模型错把背景当成目标 。
3.召回率:正样本预测正确占实际正样本的比例
R=(TP)/(TP+FN)
为了找到所有正样本。
召回率低,精确度高的解决办法:
对错误的标注样本进行修正。
4.平均精度AP
AP就是Precision-recall 曲线下面的面积。
5.map
当我们把所有类别的AP都计算出来后,再对它们求平均值,即可得到mAP。