【深度学习编译器系列】1. 为什么需要深度学习编译器?
本系列是自学深度学习编译器过程中的一些笔记和总结,参考文献在文末。
1. 概述
深度学习(DL)编译器的产生有两方面的因素:深度学习模型的广泛应用,以及深度学习芯片的层出不穷。
一方面,我们现在有非常多深度学习的应用,比如自动驾驶技术常常需要用到计算机视觉方面的模型,如行人检测,车道线识别等,智能家居设备常常需要用到自然语言处理(NLP)和语音识别方面的模型,甚至在生物学领域深度学习可以解决难倒了几代科学家的蛋白质折叠问题。
另一方面,这些应用要投入使用,面对的是非常多样的部署环境。比如自动驾驶相关的计算机视觉模型需要部署到车辆上,智能家居相关的自然语言处理模型需要部署到智能音箱上,另外一些应用还可能部署到手机上、数据中心的计算集群上等。而随着各种深度学习专用芯片的出现,如Google的TPU,Nvidia的Turing,Intel NNP,Amazon的Inferentia,阿里平头哥的含光,华为海思的NPU等等,部署环境变得更加的多样化。

那么如何使不同的深度学习应用在不同的部署环境(如不同的硬件、不同的操作系统、不同的容器执行环境、不同的运行时计算库、不同的加速器类型等)上获得最优的性能呢?这正是深度学习编译器研究的问题。
2. 什么是深度学习编译器
深度学习编译器的任务,是把输入的深度学习模型,转化成不同硬件上优化的代码进行输出。
这个过程和传统编译器所做的事情非常类似,因此取名“深度学习编译器”。
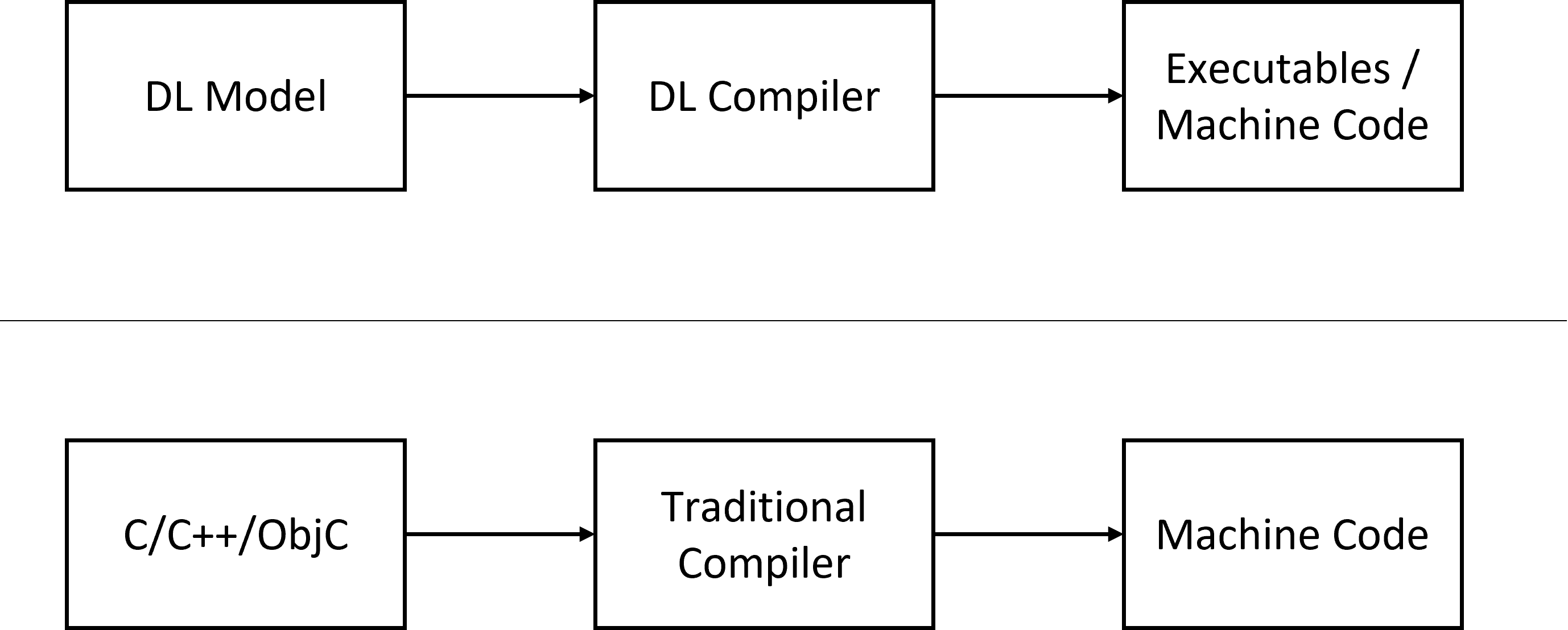
但深度学习编译器也有和传统编译器不同的地方。最大的不同在于输入不同,传统编译器输入的是高级语言,比如C/C++/ObjC,而深度学习编译器输入的是深度学习模型(一般以计算图的形式存在)。这样的输入使得深度学习的领域知识可以在编译的过程中被引入进来,从而更好地优化部署的代码。这也是为什么不直接用传统编译器来编译深度学习相关应用的原因。
参考文献:
- https://mlc.ai/zh/chapter_introduction/index.html
- https://www.bilibili.com/video/BV1pM41167KP/