【目标检测】目标检测 相关学习笔记
目标检测算法
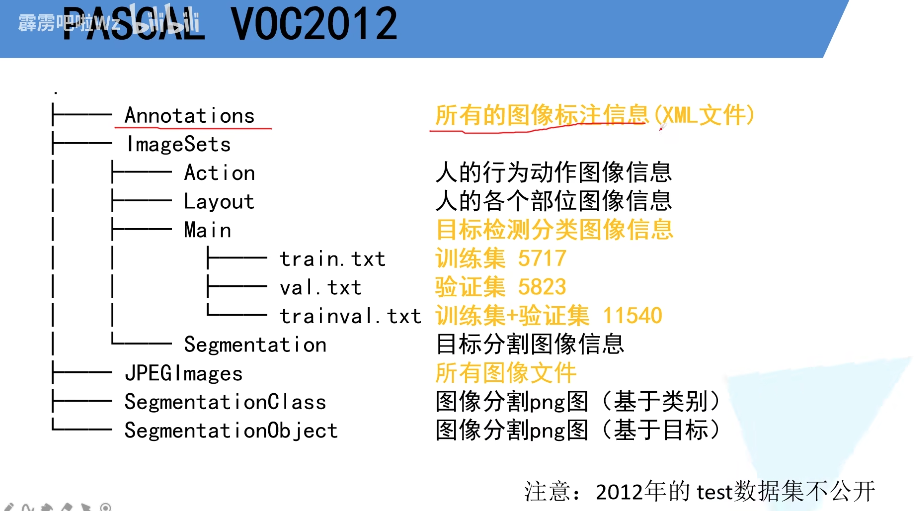
PASCALVOC2012数据集
挑战赛主要分为 图像分类 目标检测 目标分割 动作识别
数据集分为四个大类 交通(飞机 船 公交车 摩托车) 住房(杯子 椅子 餐桌 沙发) 动物(鸟 猫 奶牛 狗 马 羊) 其他(人)
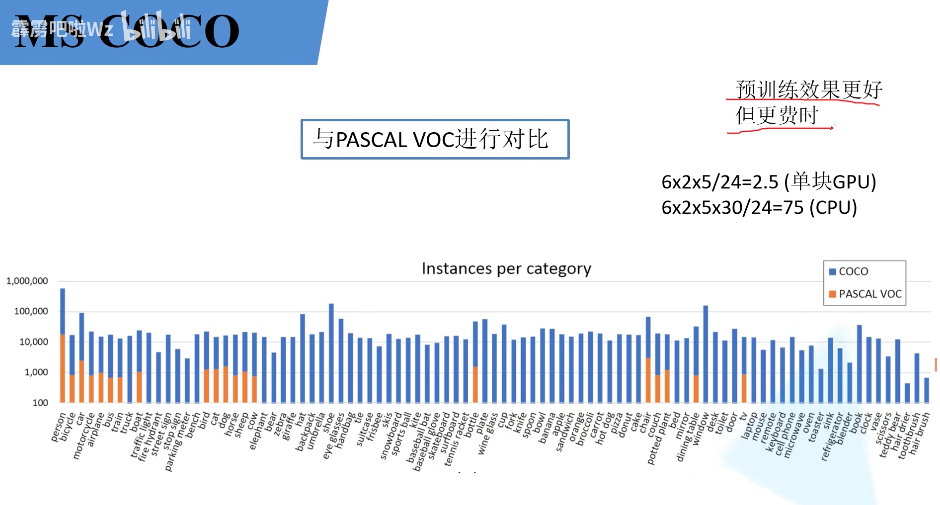
MS COCO数据集

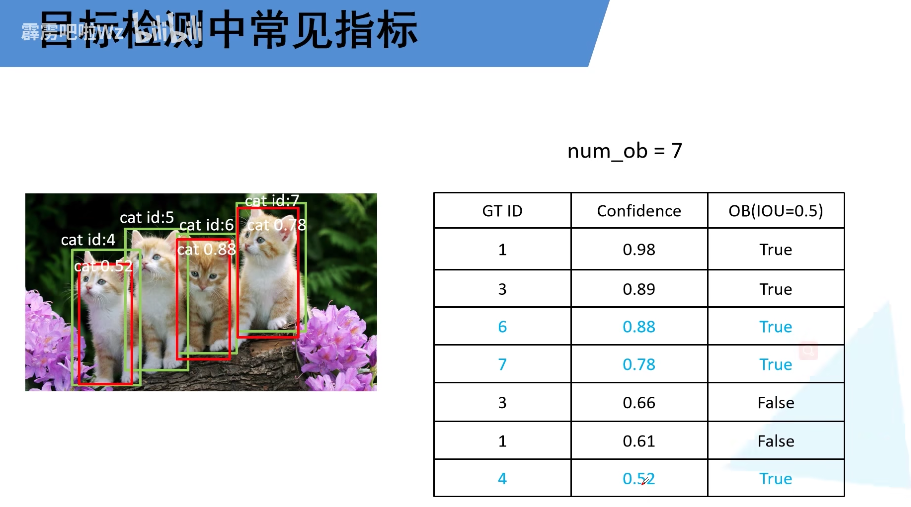
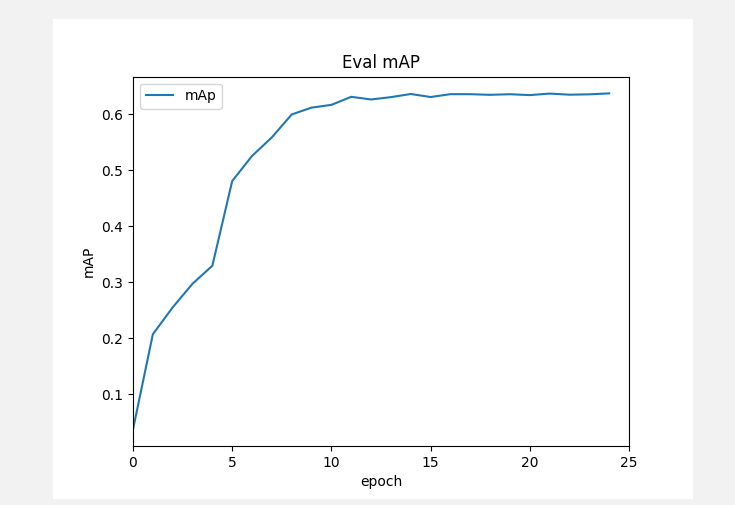
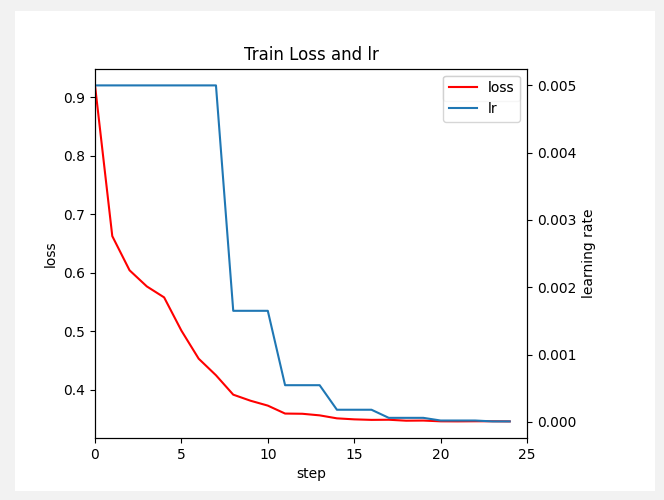
mAP

目标检测前言

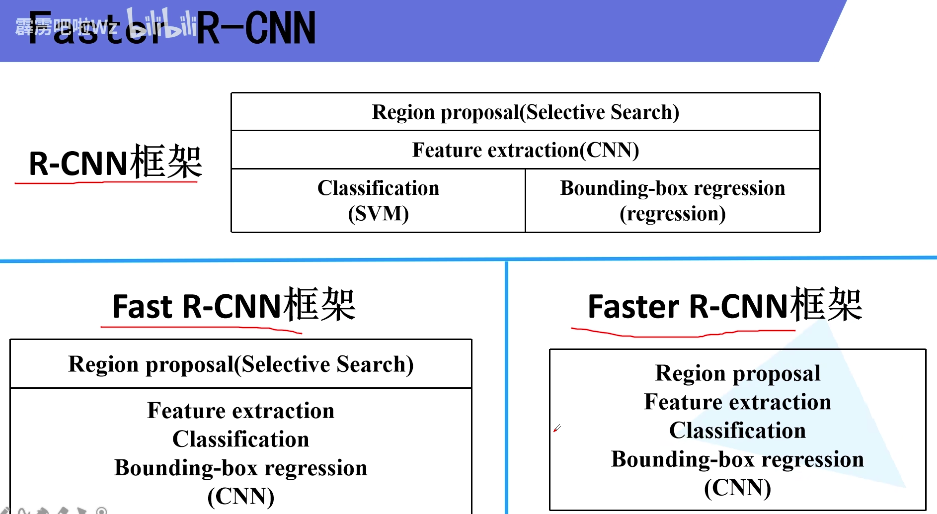
1. RCNN
1.框定候选区
2.对每一个候选区域,使用深度网络提取特征
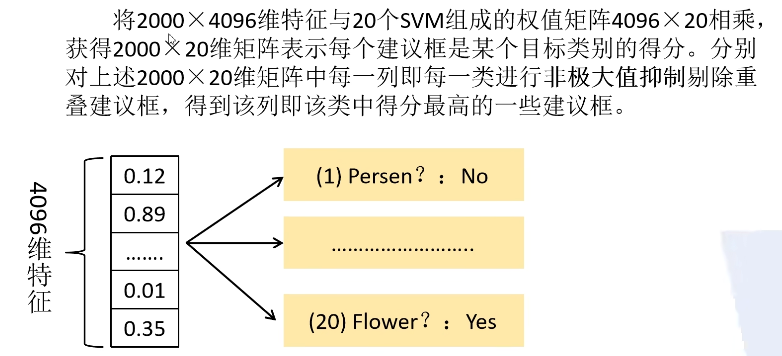
3.将特征送入每一类的SVM分类器,判定类别
4.使用回归器精细修正候选框位置
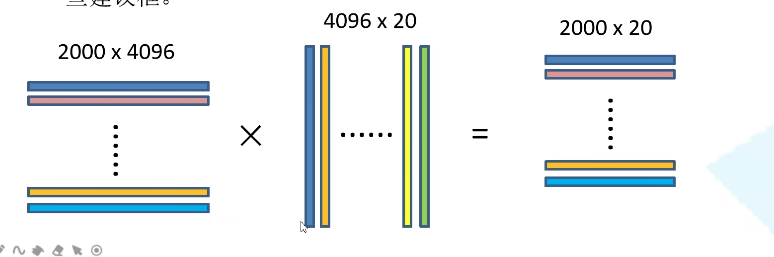
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3LsnYSGV-1692175490949)(/Users/hudie/Library/Application%20Support/typora-user-images/image-20230323093521225.png)]


RCNN存在的问题
1.速度慢
2.空间大

2.FasterRCNN

3 Faster R-CNN
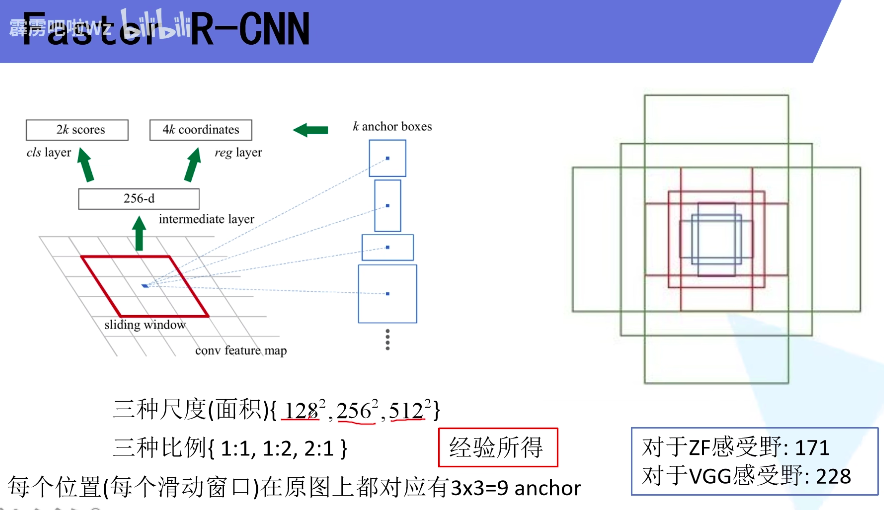
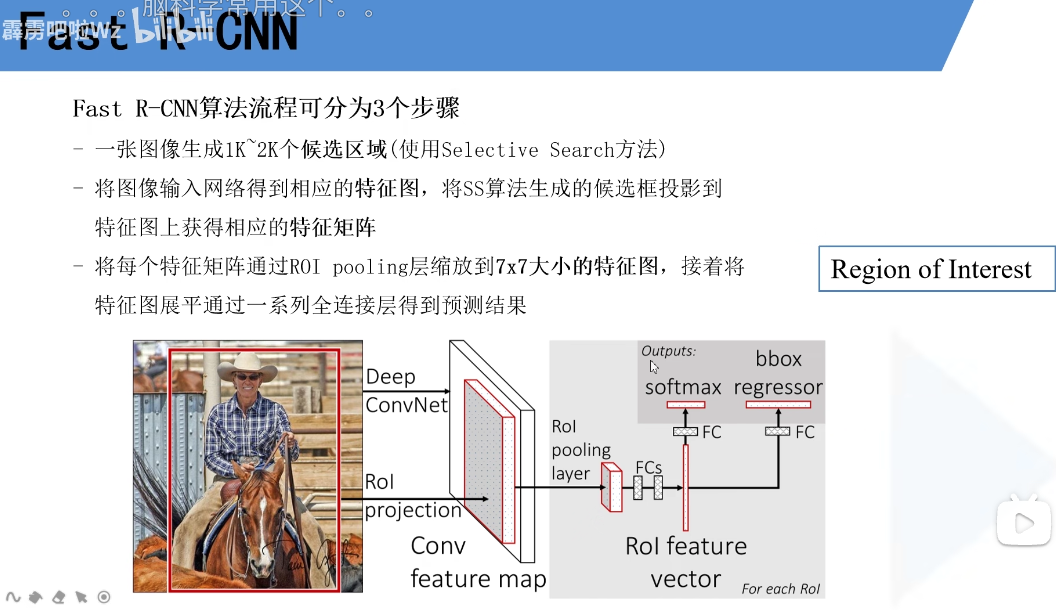
Faster RCNN检测部分主要可以分为四个模块:
(1)conv layers。即特征提取网络,用于提取特征。通过一组conv+relu+pooling层来提取图像的feature maps,用于后续的RPN层和取proposal。
(2)RPN(Region Proposal Network)。即区域候选网络,该网络替代了之前RCNN版本的Selective Search,用于生成候选框。这里任务有两部分,一个是分类:判断所有预设anchor是属于positive还是negative(即anchor内是否有目标,二分类);还有一个bounding box regression:修正anchors得到较为准确的proposals。因此,RPN网络相当于提前做了一部分检测,即判断是否有目标(具体什么类别这里不判),以及修正anchor使框的更准一些。
(3)RoI Pooling。即兴趣域池化(SPP net中的空间金字塔池化),用于收集RPN生成的proposals(每个框的坐标),并从(1)中的feature maps中提取出来(从对应位置扣出来),生成proposals feature maps送入后续全连接层继续做分类(具体是哪一类别)和回归。
(4)Classification and Regression。利用proposals feature maps计算出具体类别,同时再做一次bounding box regression获得检测框最终的精确位置
FPN 结构讲解
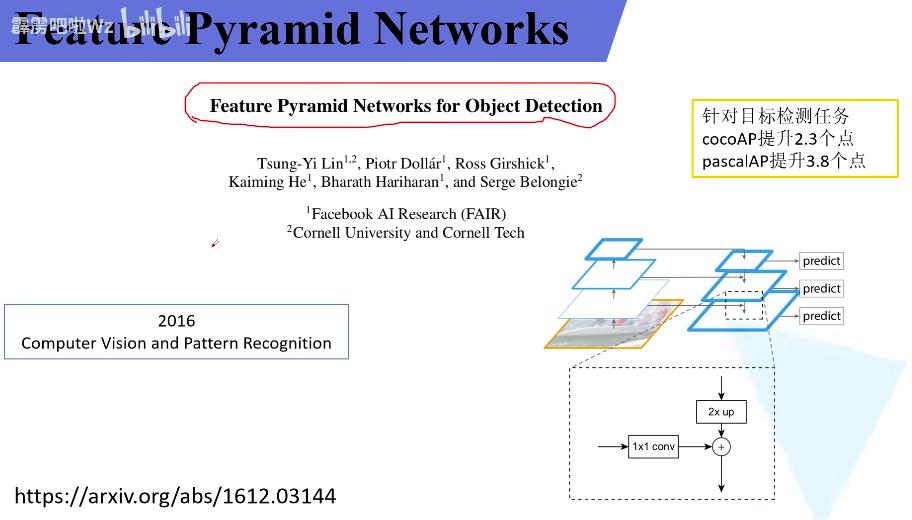
Region Proposal Network,直接翻译是“区域生成网络”,通俗讲是“筛选出可能会有目标的框”。其本质是基于滑窗的无类别object检测器,输入是任意尺度的图像,输出是一系列矩形候选区域
Faster R-CNN由两个模块组成,第一个模块是用来产生区域推荐的RPN,第二个模块是使用推荐区域的Fast R-CNN检测器。
传统检测方法提取候选区域都非常耗时,如OpenCV adaboost使用滑动窗口+图像金字塔,或R-CNN使用SS(Selective Search)。而Faster RCNN直接使用RPN生成检测框,能极大提升检测框的生成速度,而RPN是用一个全卷积网络来实现的,可以与检测网络共享整幅图像的卷积特征,从而产生几乎无代价的区域推荐
非极大值抑制
Non-Maximum Suppression的翻译是非“极大值”抑制,而不是非“最大值”抑制。这就说明了这个算法的用处:找到局部极大值,并筛除(抑制)邻域内其余的值
SSD
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CMCbTRvH-1692175490951)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230425093635171.png)]
经典算法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RJm3pHfV-1692175490951)(https://cdn.staticaly.com/gh/hudiework/img@main/image-20230425154244293.png)]
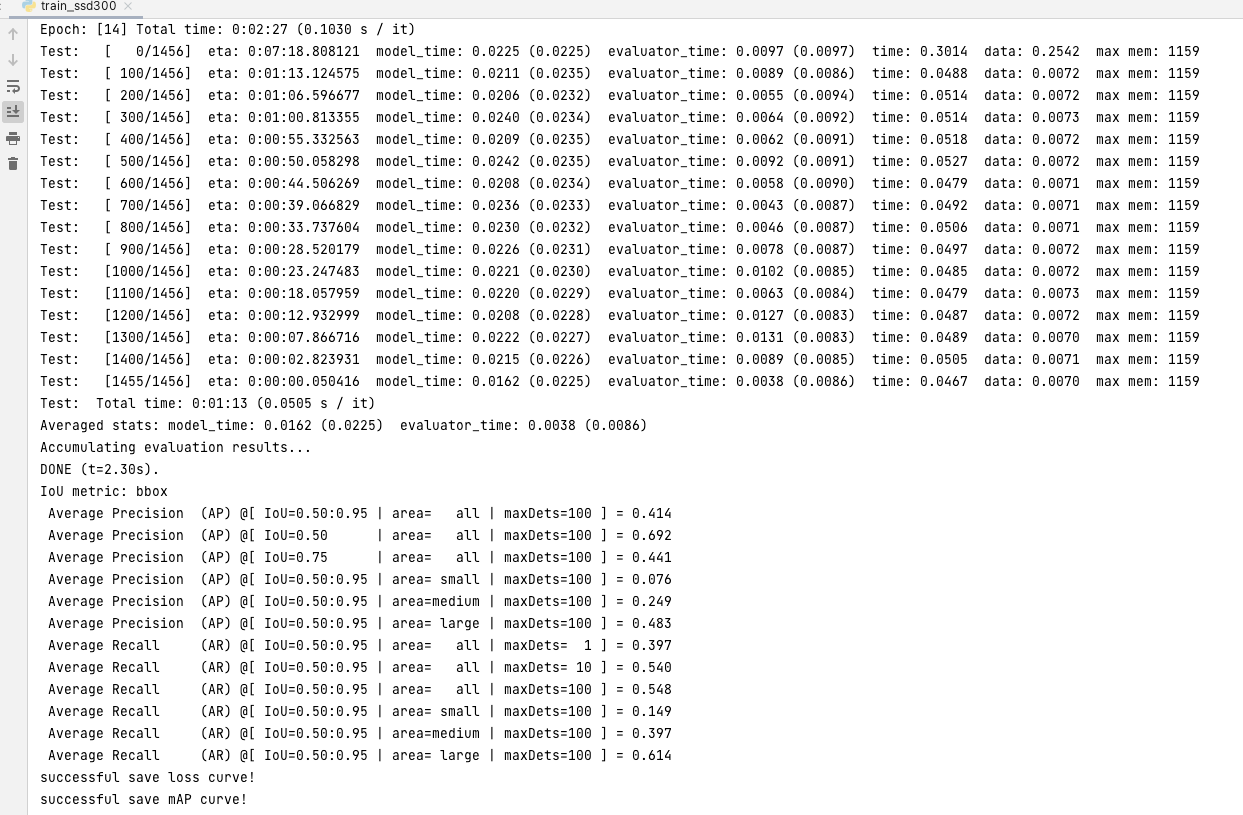
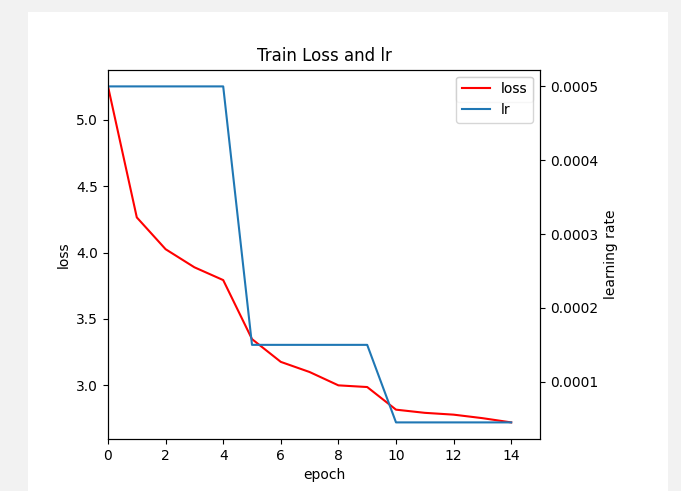
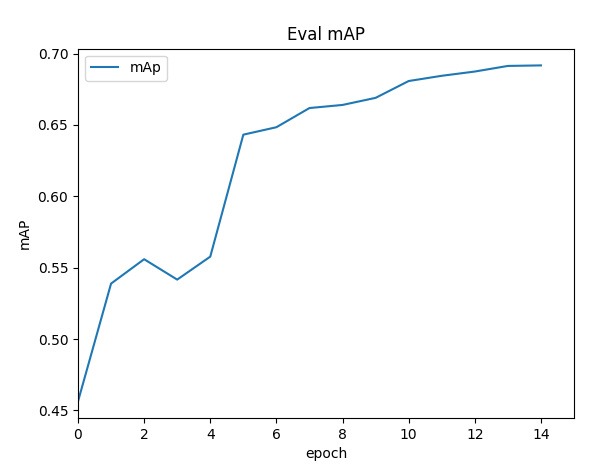
实际上训练结果 faster 和ssd 训练结果 差不多 如果训练集比较小的话 那么 faster rcnn 比ssd训练结果要好一点 ssd 检测速度要比rcnn块很多 单gpu可以检测50-60张 fpn+ssd = RetinaNet 检测精度差不多 == fpn+ faster rcnn 但是检测速度快很多
SSD: 训练结果
YOLO


yolov1
YoloV1 对于群体性的小目标 适应性效果更差 小的值并且目标比较密集的话 yolov1 是不能做的 主要的就是 定位不准确 直接定位 而不是相对于 anchor进行回归预测
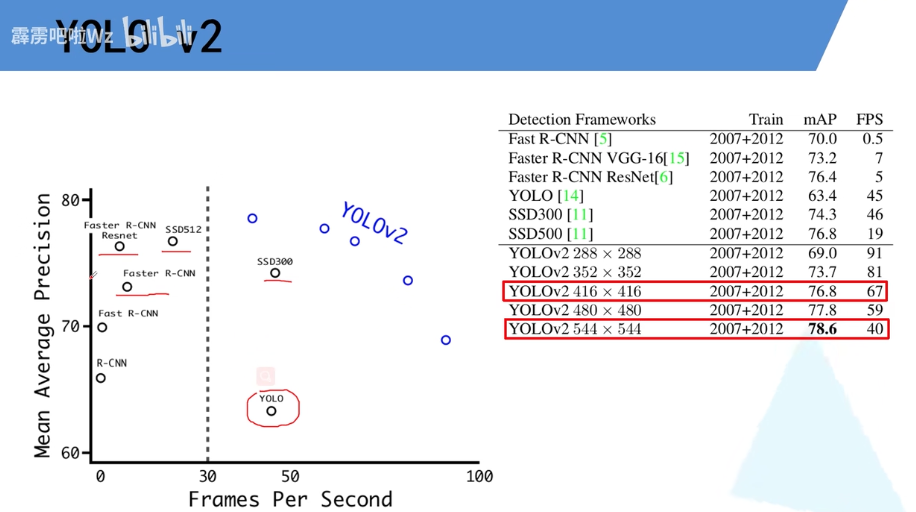
Yolov2




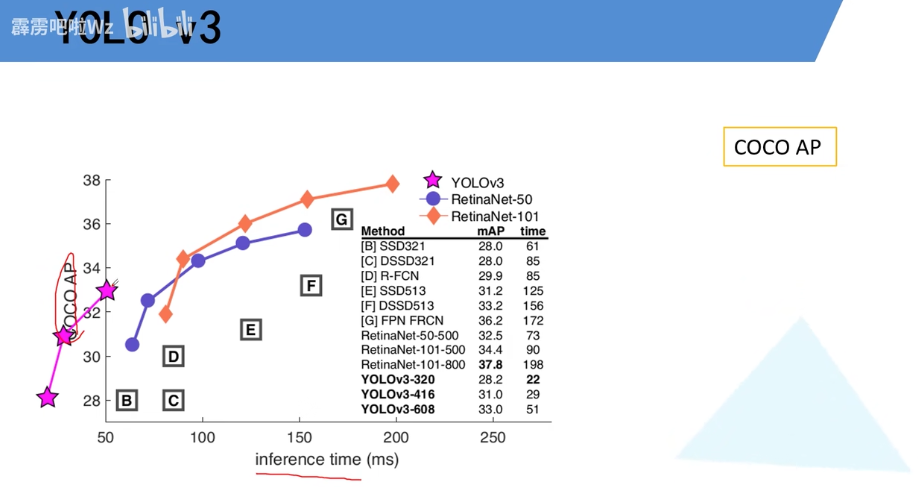
YOLOV3

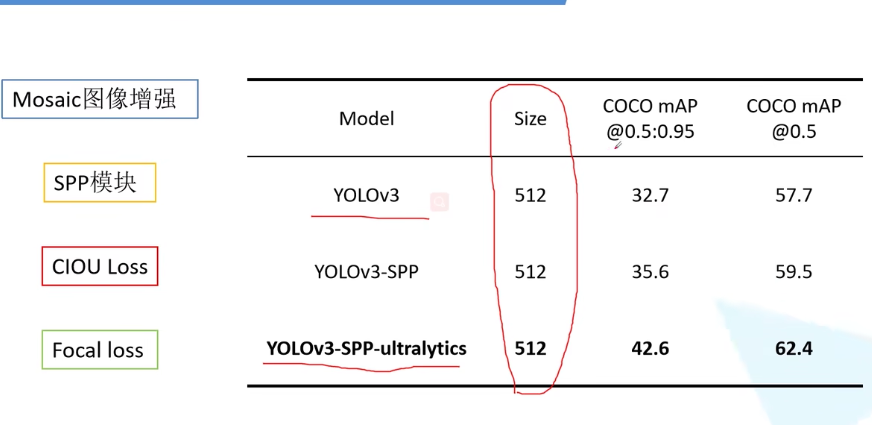
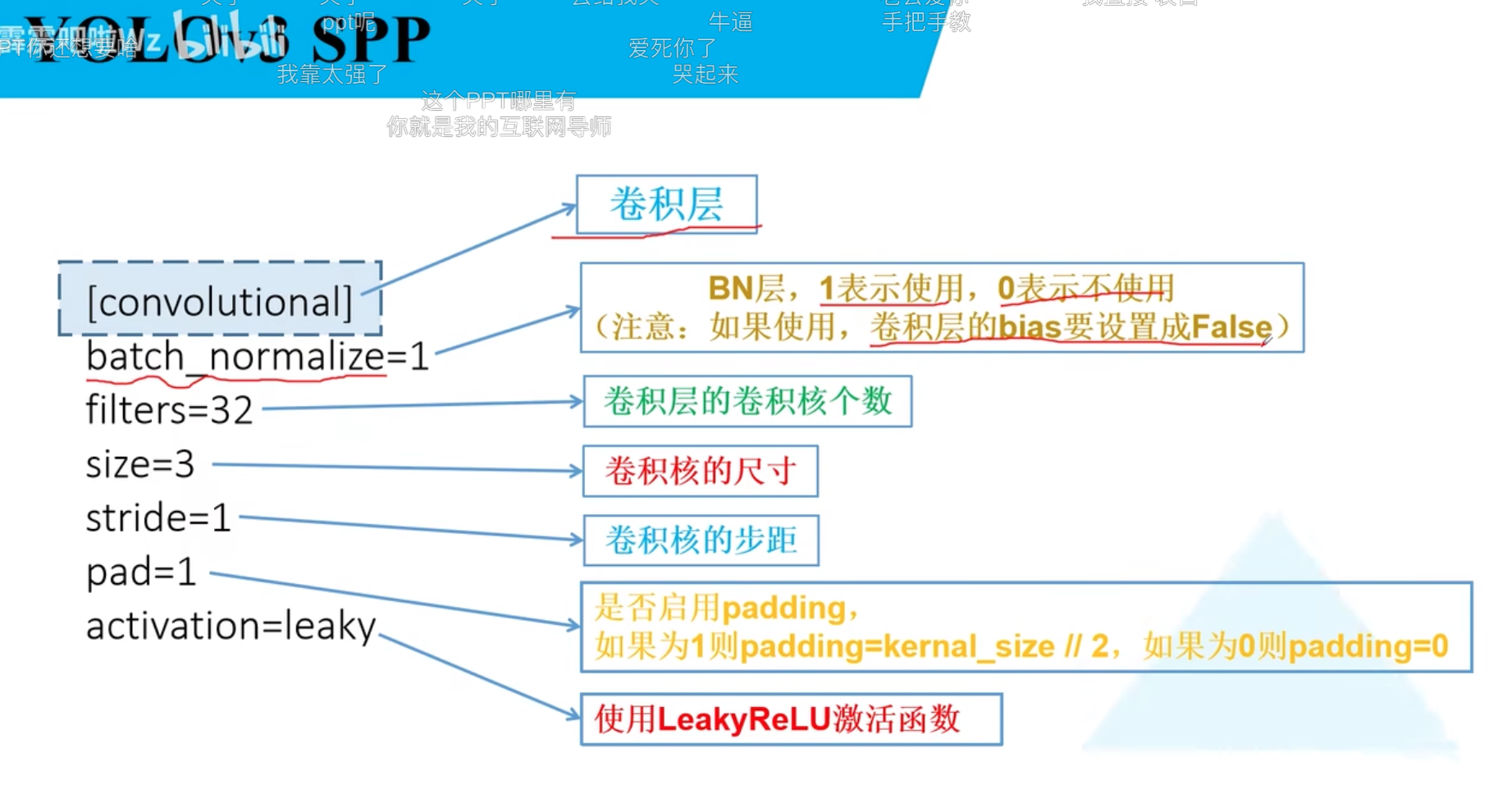
yoloV3spp

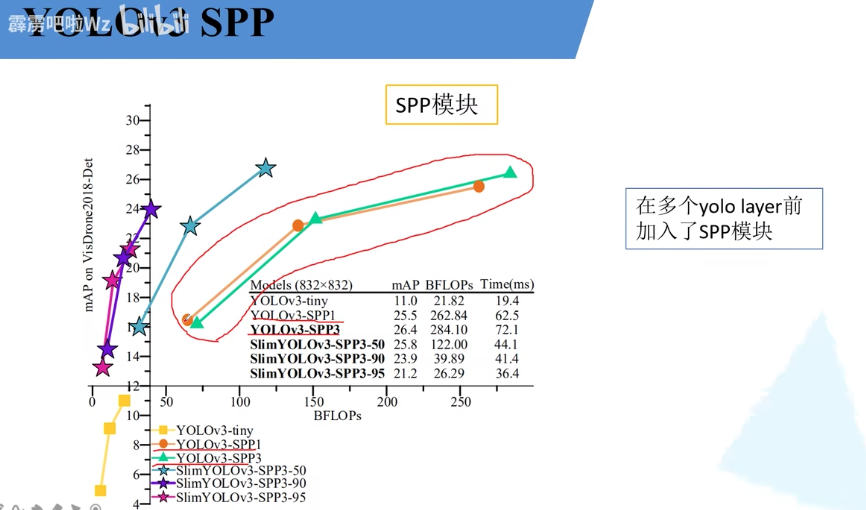


yoloV3SPP训练:
第一步 先将pascal数据集转换成yolo专用的数据格式

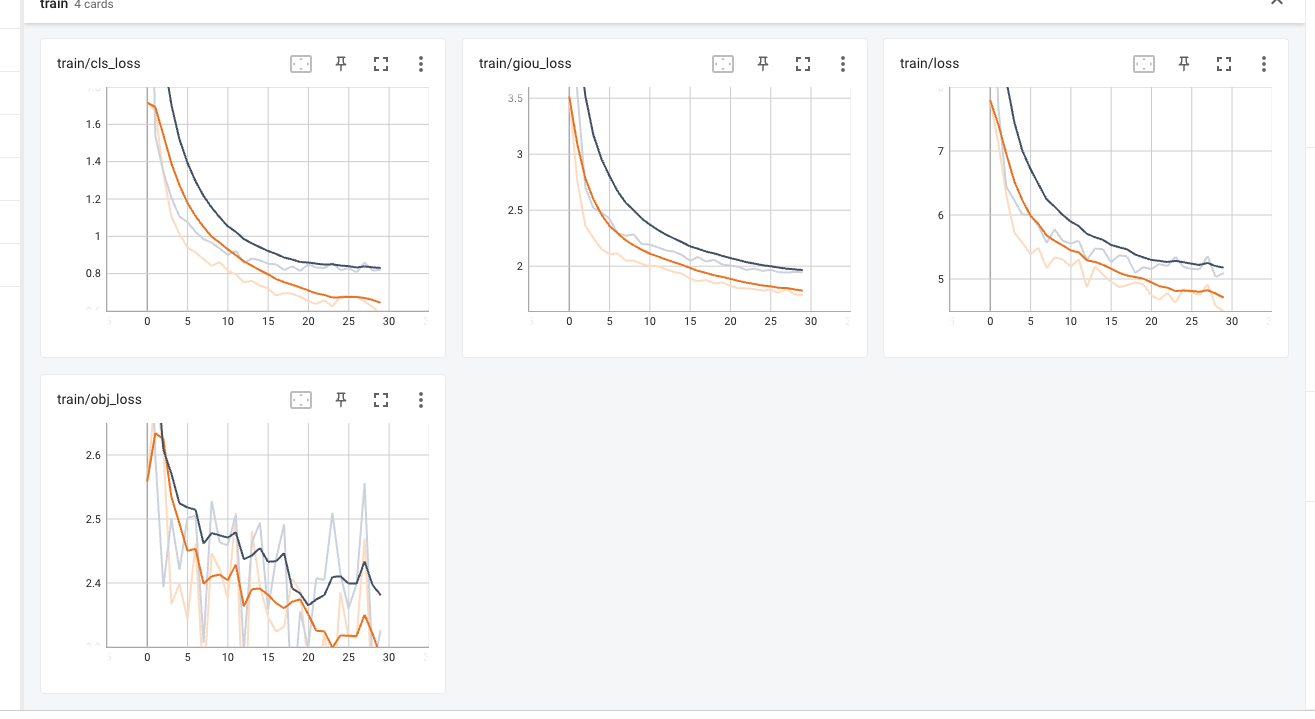
分割之后的数据集显示、

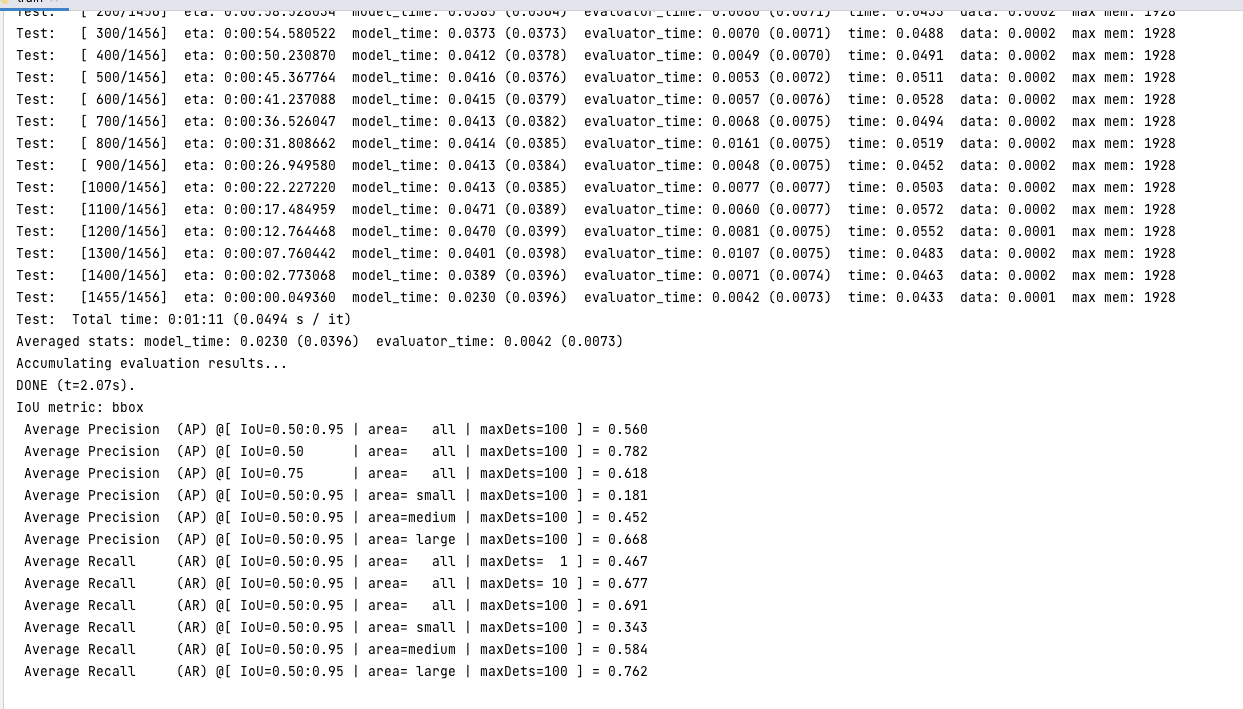
YoloV4
YOLOv4是2020年Alexey Bochkovskiy等人发表在CVPR上的一篇文章,并不是Darknet的原始作者Joseph Redmon发表的,但这个工作已经被Joseph Redmon大佬认可了。之前我们有聊过YOLOv1~YOLOv3以及Ultralytics版的YOLOv3 SPP网络结构,如果不了解的可以参考之前的视频,YOLO系列网络详解。如果将YOLOv4和原始的YOLOv3相比效果确实有很大的提升,但和Ultralytics版的YOLOv3 SPP相比提升确实不大,但毕竟Ultralytics的YOLOv3 SPP以及YOLOv5都没有发表过正式的文章,所以不太好讲。所以今天还是先简单聊聊Alexey Bochkovskiy的YOLOv4。
https://blog.csdn.net/qq_37541097/article/details/123229946?spm=1001.2014.3001.5501
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gOAlg63O-1692175490953)(…/…/Library/Application%20Support/typora-user-images/image-20230509150732751.png)]
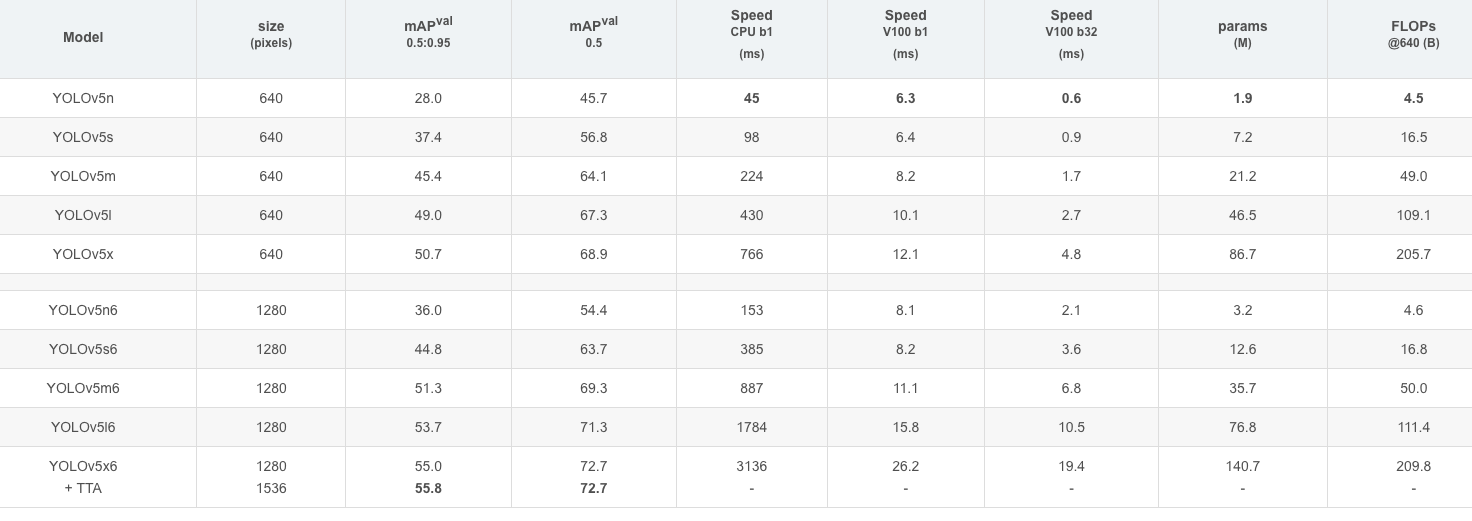
YoloV5
https://blog.csdn.net/qq_37541097/article/details/123594351?spm=1001.2014.3001.5501
FCOS:
在之前讲的一些目标检测网络中,比如Faster RCNN系列、SSD、YOLOv2~v5(注意YOLOv1不包括在内)都是基于Anchor进行预测的。即先在原图上生成一堆密密麻麻的Anchor Boxes,然后网络基于这些Anchor去预测它们的类别、中心点偏移量以及宽高缩放因子得到网络预测输出的目标,最后通过NMS即可得到最终预测目标。那基于Anchor的网络存在哪些问题呢,在FCOS论文的Introduction中,作者总结了四点:
- 检测器的性能和Anchor的size以及aspect ratio相关,比如在RetinaNet中改变Anchor(论文中说这是个超参数
hyper-parameters)能够产生约4%的AP变化。换句话说,Anchor要设置的合适才行。- 一般Anchor的size和aspect ratio都是固定的,所以很难处理那些形状变化很大的目标(比如一本书横着放w远大于h,竖着放h远大于w,斜着放w可能等于h,很难设计出合适的Anchor)。而且迁移到其他任务中时,如果新的数据集目标和预训练数据集中的目标形状差异很大,一般需要重新设计Anchor。
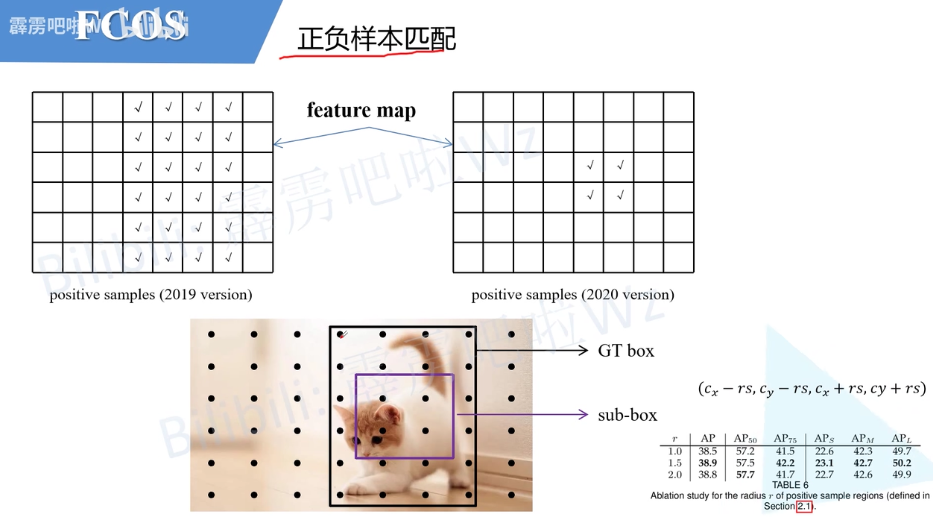
- 为了达到更高的召回率(查全率),一般需要在图片中生成非常密集的Anchor Boxes尽可能保证每个目标都会有Anchor Boxes和它相交。比如说在FPN(Feature Pyramid Network)中会生成超过18万个Anchor Boxes(以输入图片最小边长800为例),那么在训练时绝大部分的Anchor Boxes都会被分为负样本,这样会导致正负样本极度不均。下图是我随手画的样例,红色的矩形框都是负样本,黄色的矩形框是正样本。
- Anchor的引入使得网络在训练过程中更加的繁琐,因为匹配正负样本时需要计算每个Anchor Boxes和每个GT BBoxes之间的IoU。

YoloX
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FH5u3ZHP-1692175490954)(…/…/Library/Application%20Support/typora-user-images/image-20230509192721569.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xce3laRw-1692175490954)(…/…/Library/Application%20Support/typora-user-images/image-20230509193705340.png)]