linux--fork()详解
fork()
参考链接:链接
进程控制原语包括:进程的建立、进程的撤销、进程的等待和进程的唤醒。
fork,在英语用译为叉子,形状像Y,反过来就如下图:
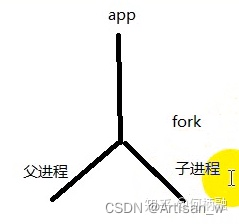
就是本来只有一个进行app,然后它调用了fork()函数,然后就产生了子进程,原来的进程叫父进程。这个子进程也是进程,但凡是进程,都有自己的虚拟地址空间。虚拟地址空间是从0到4G的大小,其中3-4G是属于内核的。创建完子进程后,父进程继续运行app(即原来的进程)的代码,刚创建出来的子进程拥有和父进程完全一样的代码段,数据段,也就是说完完全全拷贝了一份父进程,和父进程完全一样。即clone父进程0-3G的内容,而3-4G的kernel只需要重新映射一下到物理地址的kernel即可。但是操作系统要如何区分这两个进程呢?答案就是进程ID,即pid。pid是存储在PCB当中的类似身份证的东西。子进程会clone父进程的PCB到子进程,但是PCB里的pid会从操作系统中获取,得到新的pid。PCB存储在3-4G的内核中。 如下图:
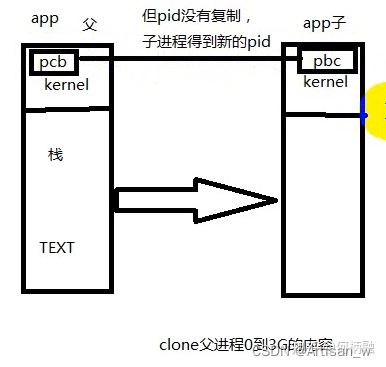
fork()完以后,父进程和子进程由于有着同样的数据段和代码段,栈,PCB也大部分相同,所以两个进程就会干着同样的事情,这样对我们没有意义,所以需要识别哪个是父进程,哪个是子进程,然后让父进程接着干原来的事,子进程去干新的事情。
然后我们通过代码来观察:
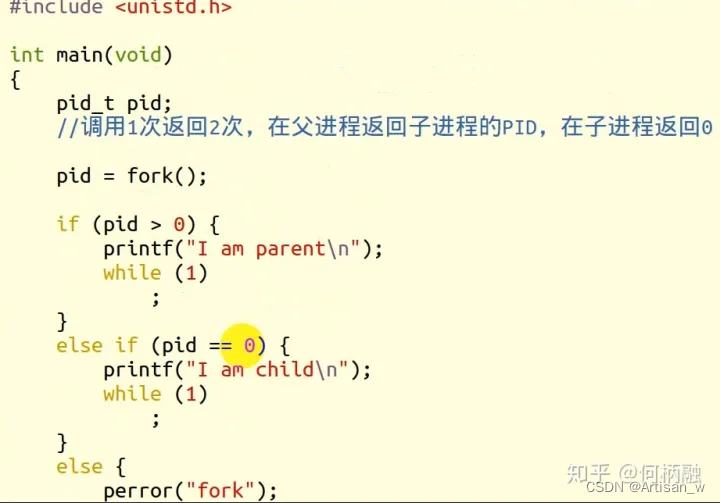
这段代码在linux中运行,fork函数有两次返回,即调用一次,返回两次。在父进程返回子进程的pid,在子进程返回0,如果返回负数则表明fork失败。所以,我们根据返回值来判断当前进程是父进程还是子进程。
结果就是:

然后ps aux显示目前正在运行的进程:

pid为4296的是父进程,4297的是子进程。
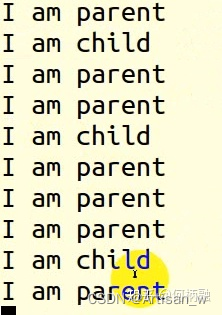
解释:这段程序本身就是一个进程,然后它创建了一个子进程,它本身变为一个父进程。但是两个进程运行的都是同一段程序代码。当父进程运行时,fork返回大于0的数,那么我们就输出相应字符。而子进程运行时,fork返回0,那么我们再输出另外的字符。所以就有了上面的现象。
然后修改一下程序:

也就是让父进程休眠1s,一直打印,子进程休眠3s,一直打印。
然后输出如下:
明显是父进程打印得比较快。很符合所学知识,
然后kill 掉子进程,即 kill pid,然后就可以发现子进程没有输出了,也可以确认pid大1的是子进程。
也就是说,我们只能通过fork的返回值来判断当前进程是父进程还是子进程。
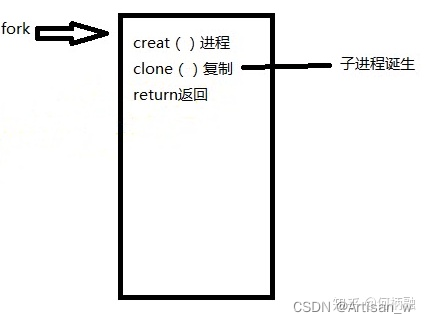
其实,fork底层是调用了内核的函数来实现fork的功能的,即先create()先创建进程,此时进程内容为空,然后clone()复制父进程的内容到子进程中,此时子进程就诞生了,接着父进程就return返回了。而子进程诞生后,是直接运行return返回的,然后接着执行后面的程序,这里注意:子进程是不会执行前面父进程已经执行过的程序了得,因为PCB中记录了当前进程运行到哪里,而子进程又是完全拷贝过来的,所以PCB的程序计数器也是和父进程相同的,所以是从fork()后面的程序继续执行。此时就按照前面的规则进行判断返回。如下图所示:
然后接下来介绍两个进程相关的函数,getpid()和getppid()
getpid()返回的是当前进程的pid,getppid()返回的是当前进程的父进程的pid。那前面说的父进程的父进程是啥呢?是shell。因为我们是子啊shell中 ./ 运行程序才创建起刚才的父进程的,所以shell是该父进程的父进程。

然后大家注意,如果此时在fork()前有变量n,那么创建子进程后,父进程和子进程的n不是同一个n,但是虚拟地址是一样的,因为也是完全拷贝父进程的,而进程间的虚拟地址都是独立的,对应的实际物理地址肯定是不同的,当你在两个进程中改变这个变量时,也可以发现这两个是不一样的,对进程线程有一定了解的都应该很好了解。
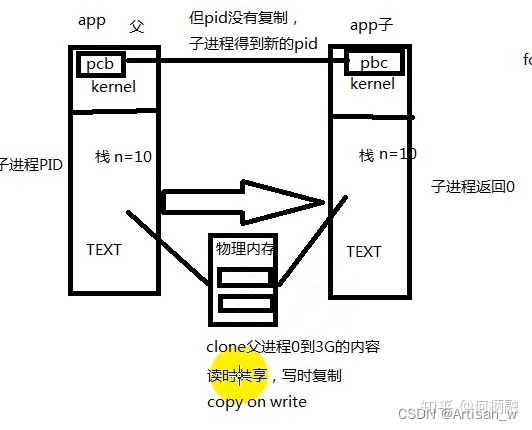
fork()的时候,父进程的虚拟地址映射着物理内存的实际的物理地址,clone()的时候,并不是在物理地址中直接再复制一份和父进程一样的物理内存块,而是子进程的虚拟地址也直接映射到同一物理内存块中,这就是读时共享。那这样的话不是就共享变量了吗?不就和前面说的矛盾了吗? 关键:当你操作这个物理内存块时(比如修改变量的值),再复制该部分的实际物理内存到子进程中,并不是全部复制。这就是写时复制。所以,当你在后面的程序中操作遍历n时,就会另辟内存块给子进程,表示这两者的独立。这就是读时共享,写时复制。
优点:可以减少实际物理内存的开销,也减少了完全复制一份内存块时cpu等资源的开销。同时减少使用的时间。所以linux引入了copy on write的机制。

程序功能就是:父进程不断地创建子进程,子进程经过30s后就结束进程。然后就看这引起的后果:
进程不断创建,ps aux和输出都非常巨大,这样由于pcb和变量的不断产生,内存消耗会很大,然后关键是cpu还要分配时间片给每个进程中的线程(此进程为一进程对应1线程),然后系统就会变得很卡,以至于其它不相关的进程操作起来也非常卡顿,因为cpu要在海量的进程中切换到你比较费时。