百日筑基篇——python爬虫学习(一)
百日筑基篇——python爬虫学习(一)
文章目录
- 前言
- 一、python爬虫介绍
- 二、URL管理器
- 三、所需基础模块的介绍
- 1. requests
- 2. BeautifulSoup
- 1. HTML介绍
- 2. 网页解析器
- 四、实操
- 1. 代码展示
- 2. 代码解释
- 1. 将大文件划分为小的文件(根据AA的ID数量划分)
- 2. 获得结果页面的url
- 3. 获取结果页面,提取出所需信息
- 4. 文件合并操作
- 总结
前言
随着学习的深入,有关从各种不同的数据库中以及互联网上的海量信息,如何有选择性的爬取我们所需的数据以方便我们的数据分析工作,爬虫的学习是必要的。
一、python爬虫介绍
Python爬虫是指使用Python编程语言编写的程序,通过模拟浏览器行为从网页中提取数据的过程
主要用途包括:
-
数据采集:通过爬虫可以从互联网上收集大量的数据,如新闻、论坛帖子、商品信息等。
-
数据分析:爬虫可以获取特定网站或多个网站的数据,进行统计和分析。
-
自动化测试:爬虫可以模拟用户行为,自动化地访问网站,并检查网站的功能、性能等。
-
内容聚合:通过爬虫可以自动化地从多个网站上获取信息,并将其聚合成为一个平台,方便用户浏览。
二、URL管理器
是指对爬取URL进行管理,防止重复和循环爬取,方便新增URL和取出URL。
class UrlManager():"""url管理器"""def __init__(self):self.new_urls = set()self.old_urls = set()def add_newurl(self,url):if url is None or len(url) == 0:returnif url in self.new_urls or url in self.old_urls:returnself.new_urls.add(url)def add_newurls(self,urls):if urls is None or len(urls) == 0:returnfor url in urls:self.add_newurl(url)def get_url(self):if self.has_newurl():url = self.new_urls.pop()self.old_urls.add(url)return urlelse:return Nonedef has_newurl(self):return len(self.new_urls) > 0该类中创建了两个集合:new_urls和 old_urls ,分别表示新增url和已爬取完的url的存储集合。
定义了四个方法,
- add_newurl(self, url): 添加新的URL到new_urls集合中。如果URL为空或已经存在于new_urls或old_urls中,则不添加。
- add_newurls(self, urls): 批量添加URL到new_urls集合中。如果URL为空,则不添加。
- get_url(self): 从new_urls中获取一个未爬取的URL,将其移动到old_urls集合中,并返回该URL。如果new_urls为空,则返回None。
- has_newurl(self): 判断是否还有未爬取的URL。返回new_urls集合的长度是否大于0。
三、所需基础模块的介绍
1. requests
用于发送HTTP请求,并获取网页内容。
import requests
requests.post(url=,params=,data=,headers=,timeout=,verify=,allow_redirects=,cookies=)
#里面的参数依次代表请求的URL、查询参数、请求数据、请求头、超时时间、SSL证书验证、重定向处理和Cookies。url = "https://wolfpsort.hgc.jp/results/pLAcbca22a5a0ccf7d913a9fc0fb140c3f4.html"r = requests.post(url)
#查看状态码,200为请求成功
print(r.status_code)#查看当前编码,以及改变编码
print(r.encoding)
r.encoding = "utf-8"
print(r.encoding)#查看返回的网页内容
print(r.text)#查看返回的http的请求头
print(r.headers)#查看实际返回的URL
print(r.url)#以字节的方式返回内容
print(r.content)#查看服务端写入本地的cookies数据
print(r.cookies)2. BeautifulSoup
用于解析HTML或XML等文档,提取所需的数据。
1. HTML介绍
HTML指的是超文本标记语言,一种用于创建网页结构的标记语言。它由一系列的元素(标签)组成,通过标签来描述网页中的内容和结构。
HTML标签:
是由< >包围的关键词,标签通常成对出现,且标签对中的第一个标签是开始标签,第二个则是结束标签,如下图所示:
在HTML语言中,标签中一般伴随着属性,比如:”id、class、herf等"
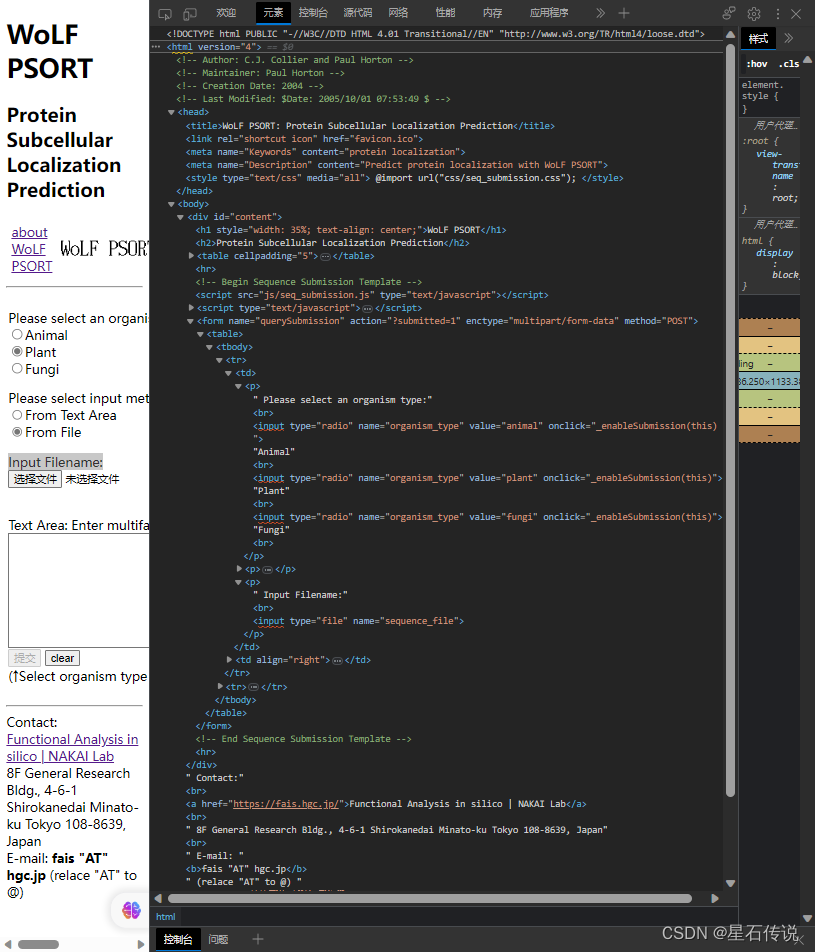
2. 网页解析器
导入 BeautifulSoup 模块
解析的一般步骤是:
- 得到HTML网页的文本
- 创建BeautifulSoup对象
- 搜索节点 (使用find_all或 find,前者返回满足条件的所有节点,后者返回第一个)
- 访问节点 (名称、属性、文字等)
示例代码如下:
base_url = "https://wolfpsort.hgc.jp/"from bs4 import BeautifulSoupwith open("D:\python\PycharmProjects\pythonProject1\pachou\linshi.html", "r", encoding="utf-8") as f:html_doc = f.read()soup = BeautifulSoup(html_doc, # HTML文档字符串"html.parser", # 解析器
)#可以分区
div_node = soup.find("div",id ="content")
links= div_node.find_all("a")# links = soup.find_all("a")
for link in links:print(link.name,base_url+link["href"],link.get_text())imgs = soup.find_all("img")
for img in imgs:print(base_url+img["src"])
这是一个基于wolfpsort网页的页面内容的爬取,根据该网页的HTML文本,可以通过标签以及属性的设置,来获得我们所需的指定的节点,再获取节点中的内容,如"herf"等
四、实操
1. 代码展示
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
import requests
import os
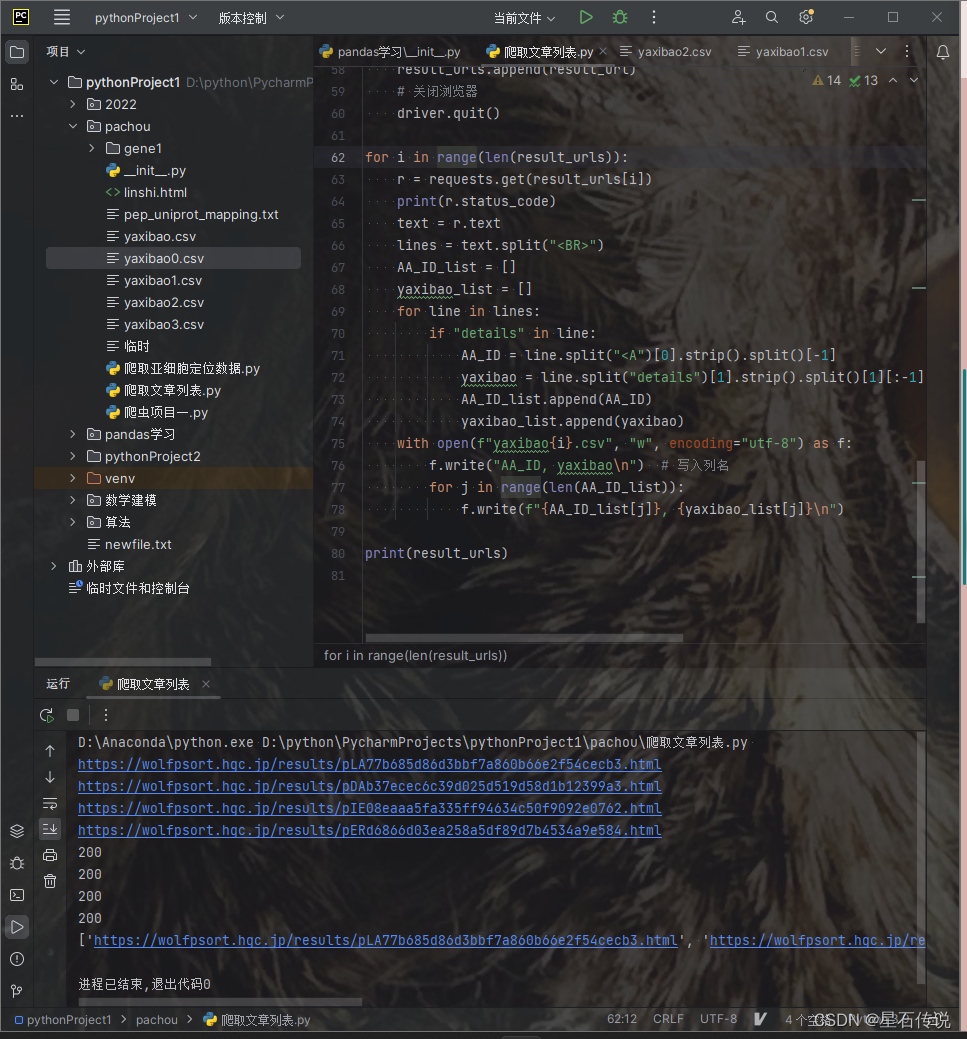
import pandas as pddef split_gene_file(source_file, output_folder, ids_per_file):os.makedirs(output_folder, exist_ok=True)current_file = Nonecount = 0with open(source_file, "r") as f:for line in f:if line.startswith(">"):count += 1if count % ids_per_file == 1:if current_file:current_file.close()output_file = f"{output_folder}/gene_file_{count // ids_per_file + 1}.csv"current_file = open(output_file, "w", encoding='utf-8')current_file.write(line)else:current_file.write(line)if current_file:current_file.close()split_gene_file("D:\yuceji\Lindera_aggregata.gene.pep", "gene1", 500)files = os.listdir("D:\python\PycharmProjects\pythonProject1\pachou\gene1")result_urls = []for i in range(0, 4): #可自行设置所需文件数# 设置WebDriver路径,启动浏览器driver = webdriver.Edge()# 打开网页url = "https://wolfpsort.hgc.jp/"driver.get(url)time.sleep(5)wuzhong_type = driver.find_element(By.XPATH, '//*[@id="content"]/form/table/tbody/tr[1]/td[1]/p[1]/input[2]')wuzhong_type.click()wenjian_type = driver.find_element(By.XPATH, '//*[@id="content"]/form/table/tbody/tr[1]/td[1]/p[2]/input[2]')wenjian_type.click()input_element = driver.find_element(By.XPATH, '//*[@id="content"]/form/table/tbody/tr[1]/td[1]/p[3]/input')input_element.send_keys(f"D:\python\PycharmProjects\pythonProject1\pachou\gene1\gene_file_{i + 1}.csv")time.sleep(10)# 提交表单submit_button = driver.find_element(By.XPATH, '//*[@id="content"]/form/table/tbody/tr[2]/td/p/input[1]')submit_button.click()time.sleep(30)with open("result_urls","a",encoding="utf-8") as f:# 获取结果页面的URLresult_url = driver.current_urlf.write(result_url+ "\n")# 输出结果页面的URLprint(result_url)result_urls.append(result_url)# 关闭浏览器driver.quit()for i in range(len(result_urls)):r = requests.get(result_urls[i])print(r.status_code)text = r.textlines = text.split("<BR>")AA_ID_list = []yaxibao_list = []for line in lines:if "details" in line:AA_ID = line.split("<A")[0].strip().split()[-1]yaxibao = line.split("details")[1].strip().split()[1][:-1]AA_ID_list.append(AA_ID)yaxibao_list.append(yaxibao)with open(fr"D:\python\PycharmProjects\pythonProject1\pachou\result_dir\yaxibao{i}.csv", "w", encoding="utf-8") as f:f.write("AA_ID, yaxibao\n") # 写入列名for j in range(len(AA_ID_list)):f.write(f"{AA_ID_list[j]}, {yaxibao_list[j]}\n")print(result_urls)# 再将所有的结果文件合并为一个大文件
result_csv = r"D:\python\PycharmProjects\pythonProject1\pachou\result_dir"
# 获取结果文件列表
result_files = os.listdir(result_csv)[:-1]
print(result_files)
# 创建一个空的DataFrame用于存储合并后的结果
merged_data = pd.DataFrame()
# 遍历每个结果文件
for file in result_files:# 读取结果文件df = pd.read_csv(result_csv + "\\" + file)#print(df)# 将结果文件的数据添加到合并后的DataFrame中merged_data = pd.concat([merged_data, df])
#print(merged_data)
# 保存合并后的结果到一个大文件
merged_data.to_csv("merged_results.csv", index=False)我运行了这个代码,遍历前面四个文件,发现都很好的得到了结果页面的URL。说明这个代码是可行的。
2. 代码解释
这个代码差不多可以分为四个部分:
- 将大文件划分为小的文件
- 使用selenium库进行模拟用户行为,以获得结果页面的url
- 使用requests模块,通过上一步获得的url,发送请求,获取结果页面,并提取出所需信息
- 文件合并操作,使用pandas库中的concat方法,将前面得到的众多小文件的结果整合到一个大文件中。
1. 将大文件划分为小的文件(根据AA的ID数量划分)
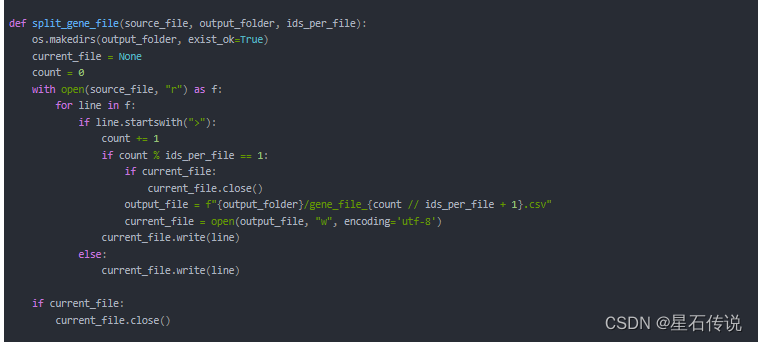
- 定义一个split_gene_file()函数,其中"ids_per_file"参数表示指定每个文件中的ID数
- 创建一个存储文件的文件夹
- 使用with语句打开源文件,并且遍历文件中的每一行,之后使用if语句判断当前行是否是有ID的行,如果不是,就直接将当前行写入当前文件(current_file);如果是,就将count(表示已读取到的ID数)的数加上1,然后再判断已读取的ID数量是否达到了自己指定的每个文件的ID数量,如果达到了,就表示需要创建一个新的输出文件output_file, 并将文件对象赋值给current_file变量,使用"w"模式表示以写入模式打开文件,并将当前行写入当前文件。
- 在处理完源文件后,检查是否存在当前正在写入的文件对象。如果是,则关闭该文件。
2. 获得结果页面的url
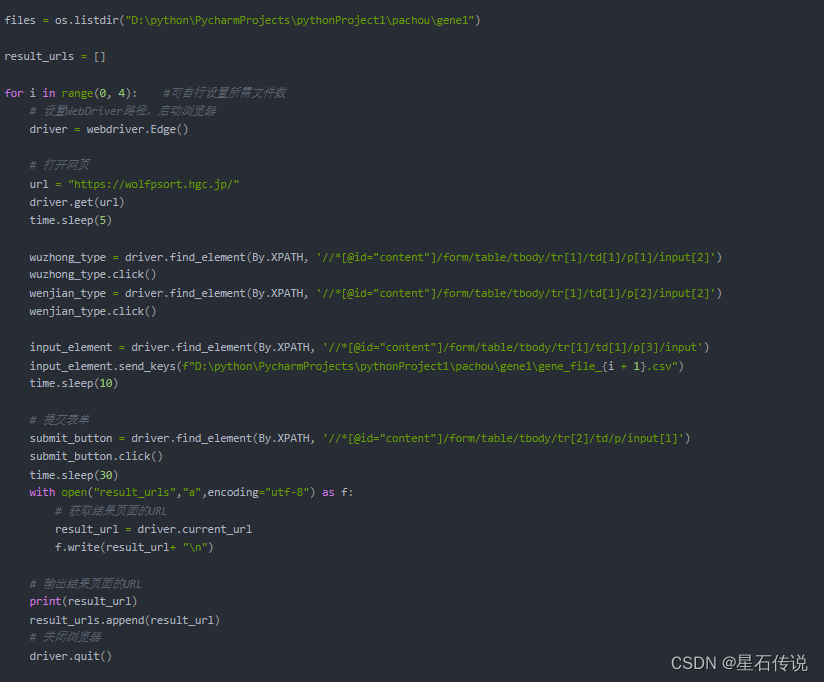
这是基于python的selenium库,
Selenium是一个用于Web自动化的工具,可以用于模拟用户在网页浏览器上的行为,包括点击、输入、提交表单等操作。
其中最主要的步骤还是查看官网页面的源代码,通过HTML文本的标签获取元素的定位。
例如:
我要查看”Please select an organism type:" ,可以右键单击,然后点击检查
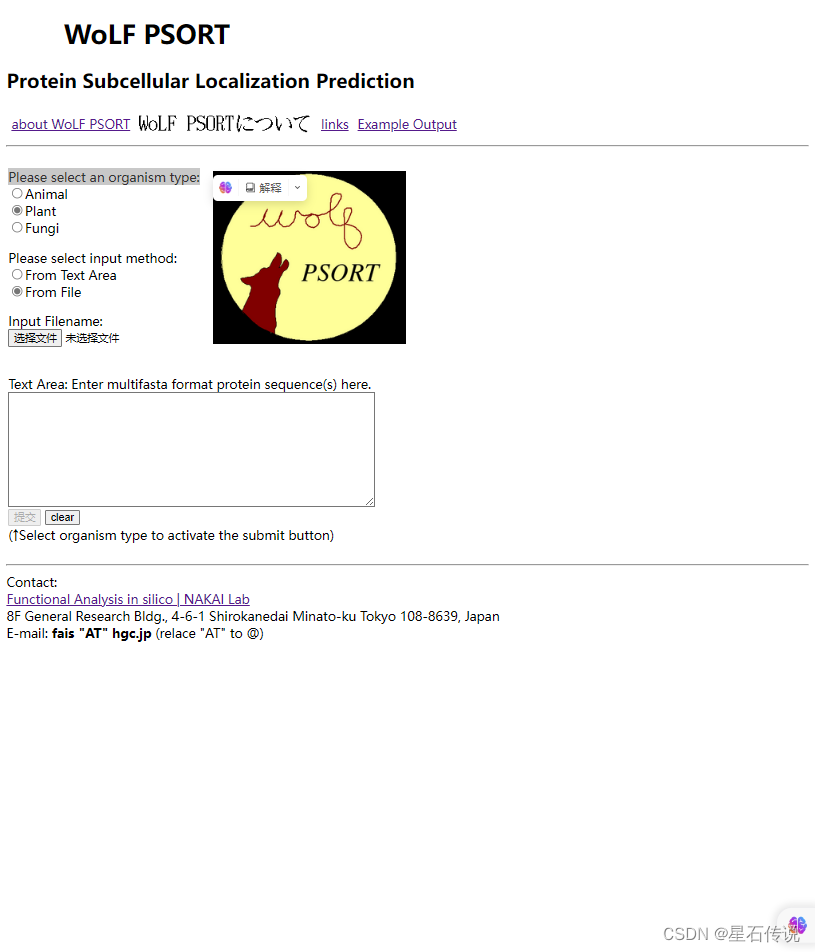
得到有关信息:
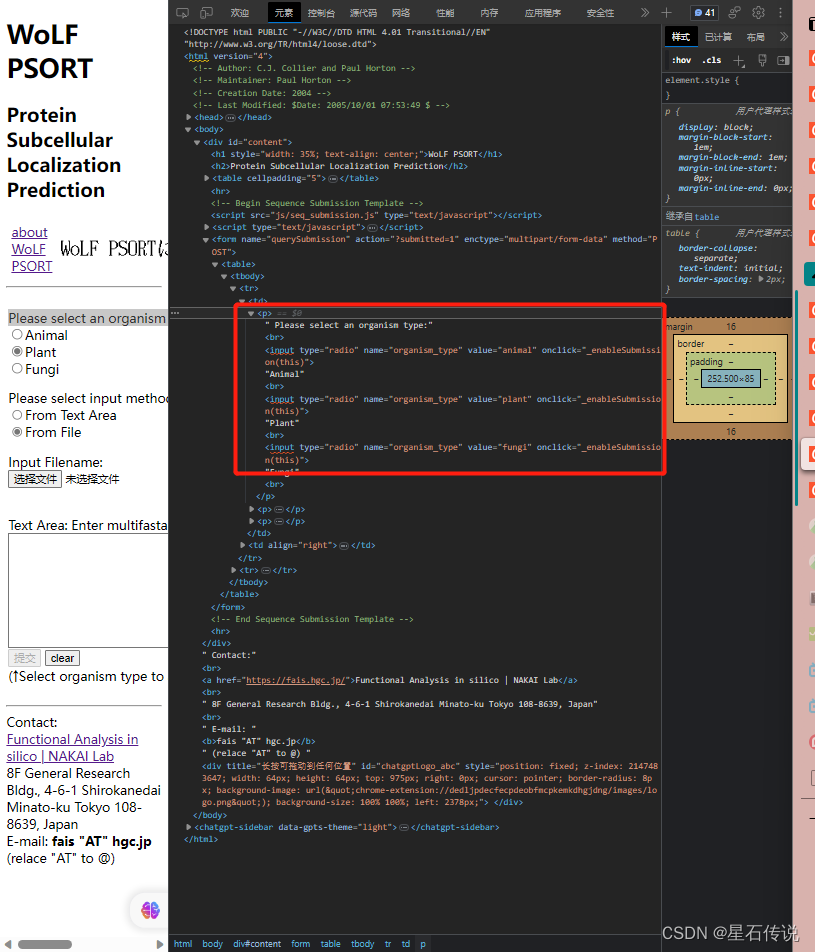
比如我在”Please select an organism type:“框中想选择"Plant”,那么我只要选择上图红框中表示输入是"plant"的框就行,然后再右键选择复制 “Xpath”
之后再将复制的Xpath粘贴到函数中,充当参数,如下所示:
wuzhong_type = driver.find_element(By.XPATH, '//*[@id="content"]/form/table/tbody/tr[1]/td[1]/p[1]/input[2]')
因为在这个定位元素函数中,我第一个参数填的是“By.XPATH”,故后面那个参数就便是元素的“Xpath”。
3. 获取结果页面,提取出所需信息
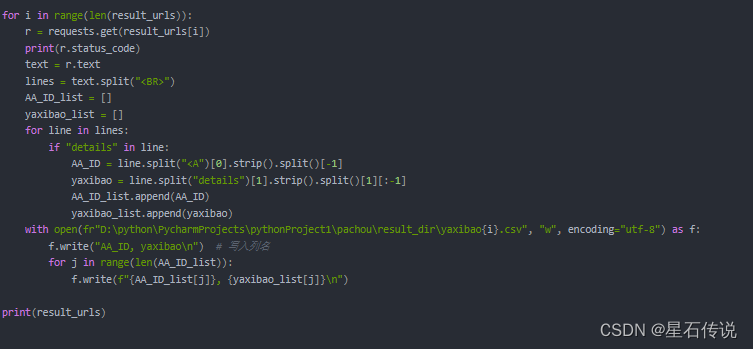
对前面得到的URL列表(result_urls)进行循环遍历,并将得到的结果保存于指定文件中
4. 文件合并操作

前面得到的结果文件是通过循环得到的,故会是众多小文件。若是欲将所有的结果信息合并于一个大文件中,可以使用pandas库中的concat方法,来合并文件,最后将循环完毕后的合并结果,保存为一个csv文件。
总结
本章主要简述了python爬虫的有关信息,并且进行了一个实操(这个爬虫是基于WoLF PSORT官网,爬取亚细胞定位结果的数据)。更多有关蛋白质亚细胞定位的信息,请看
亚细胞定位
零落成泥碾作尘,只有香如故。
–2023-8-13 筑基篇