DIDL4_前向传播与反向传播(模型参数的更新)
前向传播与反向传播
- 前向传播与反向传播的作用
- 前向传播及公式
- 前向传播范例
- 反向传播及公式
- 反向传播范例
- 小结
- 前向传播计算图
前向传播与反向传播的作用
在训练神经网络时,前向传播和反向传播相互依赖。
对于前向传播,我们沿着依赖的方向遍历计算图并计算其路径上的所有变量。
然后将这些用于反向传播,其中计算顺序与计算图的相反,用于计算w、b的梯度(即神经网络中的参数)。随后使用梯度下降算法来更新参数。
因此,在训练神经网络时,在初始化模型参数后, 我们交替使用前向传播和反向传播,利用反向传播给出的梯度来更新模型参数。
注意:
- 反向传播重复利用前向传播中存储的中间值,以避免重复计算。 带来的影响之一是我们需要保留中间值,直到反向传播完成。 这也是训练比单纯的预测需要更多的内存(显存)的原因之一。
- 这些中间值的大小与网络层的数量和批量的大小大致成正比。 因此,使用更大的批量来训练更深层次的网络更容易导致内存不足(out of memory)错误。
前向传播及公式
前向传播(forward propagation或forward pass) 指的是:按顺序(从输入层到输出层)计算和存储神经网络中每层的结果。
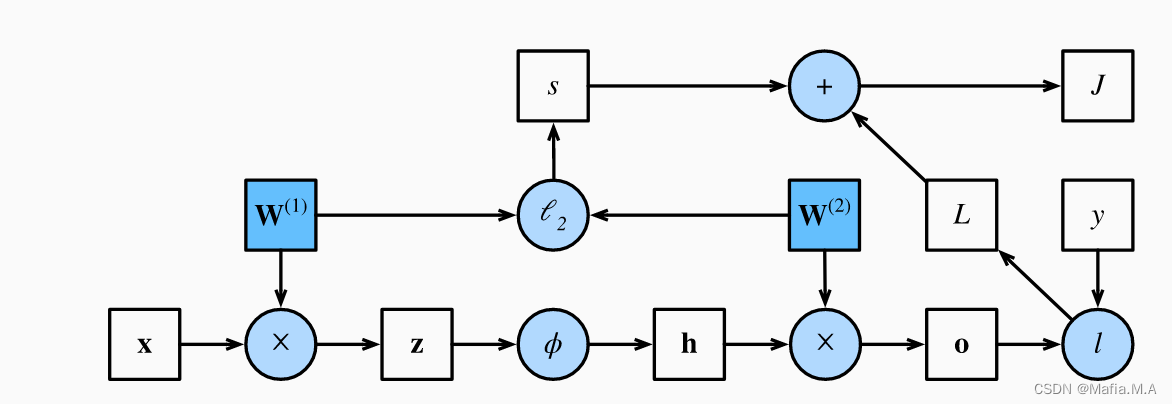
假设输入样本是 x∈Rd\mathbf{x}\in \mathbb{R}^dx∈Rd, 并且我们的隐藏层不包括偏置项。 这里的中间变量是:
z=W(1)x,\mathbf{z}= \mathbf{W}^{(1)} \mathbf{x},z=W(1)x,
其中W(1)∈Rh×d\mathbf{W}^{(1)} \in \mathbb{R}^{h \times d}W(1)∈Rh×d是隐藏层的权重参数。 将中间变量z∈Rh\mathbf{z}\in \mathbb{R}^hz∈Rh通过激活函数ϕ\phiϕ后, 我们得到长度为hhh的隐藏激活向量:
h=ϕ(z).\mathbf{h}= \phi (\mathbf{z}).h=ϕ(z).
隐藏变量h\mathbf{h}h也是一个中间变量。 假设输出层的参数只有权重W(2)∈Rq×h\mathbf{W}^{(2)} \in \mathbb{R}^{q \times h}W(2)∈Rq×h, 我们可以得到输出层变量,它是一个长度为qqq的向量:
o=W(2)h.\mathbf{o}= \mathbf{W}^{(2)} \mathbf{h}.o=W(2)h.
假设损失函数为lll,样本标签为yyy,我们可以计算单个数据样本的损失项
L=l(o,y).L = l(\mathbf{o}, y).L=l(o,y).
根据L2L_2L2正则化的定义,给定超参数λ\lambdaλ,正则化项为
s=λ2(∥W(1)∥F2+∥W(2)∥F2),s = \frac{\lambda}{2} \left(\|\mathbf{W}^{(1)}\|_F^2 + \|\mathbf{W}^{(2)}\|_F^2\right),s=2λ(∥W(1)∥F2+∥W(2)∥F2),
其中矩阵的Frobenius范数是将矩阵展平为向量后应用的L2L_2L2范数。 最后,模型在给定数据样本上的正则化损失为:
J=L+s.J = L + s.J=L+s.
前向传播范例
反向传播及公式
反向传播(backward propagation或backpropagation)指的是计算神经网络参数梯度的方法。也称“BP算法”
简言之,该方法根据微积分中的链式规则,按相反的顺序从输出层到输入层遍历网络。
该算法存储了计算某些参数梯度时所需的任何中间变量(偏导数)。
假设我们有函数Y=f(X)\mathsf{Y}=f(\mathsf{X})Y=f(X)和Z=g(Y)\mathsf{Z}=g(\mathsf{Y})Z=g(Y), 其中输入和输出X,Y,Z\mathsf{X}, \mathsf{Y}, \mathsf{Z}X,Y,Z是任意形状的张量。 利用链式法则,我们可以计算Z\mathsf{Z}Z关于X\mathsf{X}X的导数
∂Z∂X=prod(∂Z∂Y,∂Y∂X).\frac{\partial \mathsf{Z}}{\partial \mathsf{X}} = \text{prod}\left(\frac{\partial \mathsf{Z}}{\partial \mathsf{Y}}, \frac{\partial \mathsf{Y}}{\partial \mathsf{X}}\right).∂X∂Z=prod(∂Y∂Z,∂X∂Y).
反向传播的目的是计算梯度∂J/∂W(1)\partial J/\partial \mathbf{W}^{(1)}∂J/∂W(1)和∂J/∂W(2)\partial J/\partial \mathbf{W}^{(2)}∂J/∂W(2). 为此,我们应用链式法则,依次计算每个中间变量和参数的梯度。 计算的顺序与前向传播中执行的顺序相反,因为我们需要从计算图的结果开始,并朝着参数的方向努力。
- 计算目标函数J=L+sJ=L+sJ=L+s相对于损失项LLL和正则项sss的梯度
∂J∂L=1and∂J∂s=1.\frac{\partial J}{\partial L} = 1 \; \text{and} \; \frac{\partial J}{\partial s} = 1.∂L∂J=1and∂s∂J=1. - 根据链式法则计算目标函数关于输出层变量o\mathbf{o}o的梯度:
∂J∂o=prod(∂J∂L,∂L∂o)=∂L∂o∈Rq.\frac{\partial J}{\partial \mathbf{o}} = \text{prod}\left(\frac{\partial J}{\partial L}, \frac{\partial L}{\partial \mathbf{o}}\right) = \frac{\partial L}{\partial \mathbf{o}} \in \mathbb{R}^q.∂o∂J=prod(∂L∂J,∂o∂L)=∂o∂L∈Rq. - 计算正则化项相对于两个参数的梯度:
∂s∂W(1)=λW(1)and∂s∂W(2)=λW(2).\frac{\partial s}{\partial \mathbf{W}^{(1)}} = \lambda \mathbf{W}^{(1)} \; \text{and} \; \frac{\partial s}{\partial \mathbf{W}^{(2)}} = \lambda \mathbf{W}^{(2)}.∂W(1)∂s=λW(1)and∂W(2)∂s=λW(2). - 计算最接近输出层的模型参数的梯度 ∂J/∂W(2)∈Rq×h\partial J/\partial \mathbf{W}^{(2)} \in \mathbb{R}^{q \times h}∂J/∂W(2)∈Rq×h。 使用链式法则得出:
∂J∂W(2)=prod(∂J∂o,∂o∂W(2))+prod(∂J∂s,∂s∂W(2))=∂J∂oh⊤+λW(2).\frac{\partial J}{\partial \mathbf{W}^{(2)}}= \text{prod}\left(\frac{\partial J}{\partial \mathbf{o}}, \frac{\partial \mathbf{o}}{\partial \mathbf{W}^{(2)}}\right) + \text{prod}\left(\frac{\partial J}{\partial s}, \frac{\partial s}{\partial \mathbf{W}^{(2)}}\right)= \frac{\partial J}{\partial \mathbf{o}} \mathbf{h}^\top + \lambda \mathbf{W}^{(2)}.∂W(2)∂J=prod(∂o∂J,∂W(2)∂o)+prod(∂s∂J,∂W(2)∂s)=∂o∂Jh⊤+λW(2). - 为了获得关于W(1)\mathbf{W}^{(1)}W(1)的梯度,我们需要继续沿着输出层到隐藏层反向传播。 关于隐藏层输出的梯度∂J/∂h∈Rh\partial J/\partial \mathbf{h} \in \mathbb{R}^h∂J/∂h∈Rh由下式给出:
∂J∂h=prod(∂J∂o,∂o∂h)=W(2)⊤∂J∂o.\frac{\partial J}{\partial \mathbf{h}} = \text{prod}\left(\frac{\partial J}{\partial \mathbf{o}}, \frac{\partial \mathbf{o}}{\partial \mathbf{h}}\right) = {\mathbf{W}^{(2)}}^\top \frac{\partial J}{\partial \mathbf{o}}.∂h∂J=prod(∂o∂J,∂h∂o)=W(2)⊤∂o∂J. - 由于激活函数ϕ\phiϕ是按元素计算的, 计算中间变量z\mathbf{z}z的梯度∂J/∂z∈Rh\partial J/\partial \mathbf{z} \in \mathbb{R}^h∂J/∂z∈Rh需要使用按元素乘法运算符,我们用⊙\odot⊙表示:
∂J∂z=prod(∂J∂h,∂h∂z)=∂J∂h⊙ϕ′(z).\frac{\partial J}{\partial \mathbf{z}} = \text{prod}\left(\frac{\partial J}{\partial \mathbf{h}}, \frac{\partial \mathbf{h}}{\partial \mathbf{z}}\right) = \frac{\partial J}{\partial \mathbf{h}} \odot \phi'\left(\mathbf{z}\right).∂z∂J=prod(∂h∂J,∂z∂h)=∂h∂J⊙ϕ′(z). - 最后,我们可以得到最接近输入层的模型参数的梯度 ∂J/∂W(1)∈Rh×d\partial J/\partial \mathbf{W}^{(1)} \in \mathbb{R}^{h \times d}∂J/∂W(1)∈Rh×d。 根据链式法则,我们得到:
∂J∂W(1)=prod(∂J∂z,∂z∂W(1))+prod(∂J∂s,∂s∂W(1))=∂J∂zx⊤+λW(1).\frac{\partial J}{\partial \mathbf{W}^{(1)}} = \text{prod}\left(\frac{\partial J}{\partial \mathbf{z}}, \frac{\partial \mathbf{z}}{\partial \mathbf{W}^{(1)}}\right) + \text{prod}\left(\frac{\partial J}{\partial s}, \frac{\partial s}{\partial \mathbf{W}^{(1)}}\right) = \frac{\partial J}{\partial \mathbf{z}} \mathbf{x}^\top + \lambda \mathbf{W}^{(1)}.∂W(1)∂J=prod(∂z∂J,∂W(1)∂z)+prod(∂s∂J,∂W(1)∂s)=∂z∂Jx⊤+λW(1).
反向传播范例
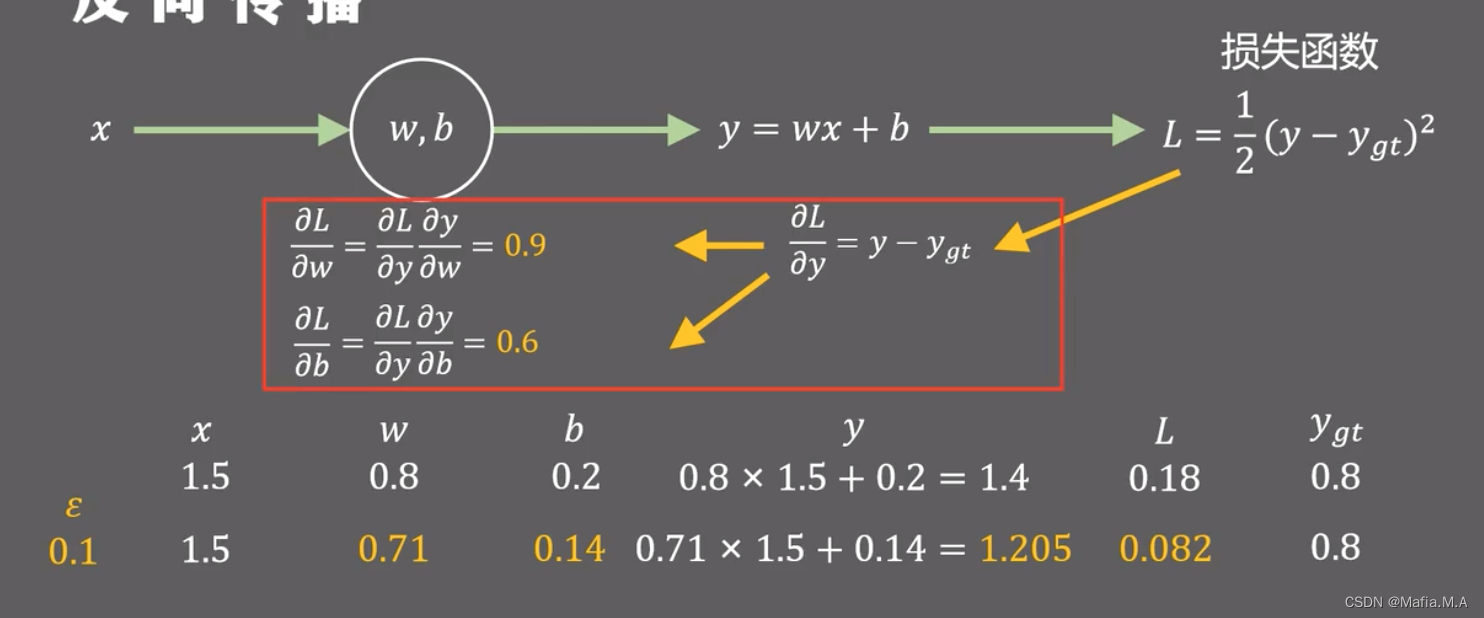
假设输入x = 1.5,模型初始参数w=0.8,b=0.2。学习率为0.1,则过程如下图:
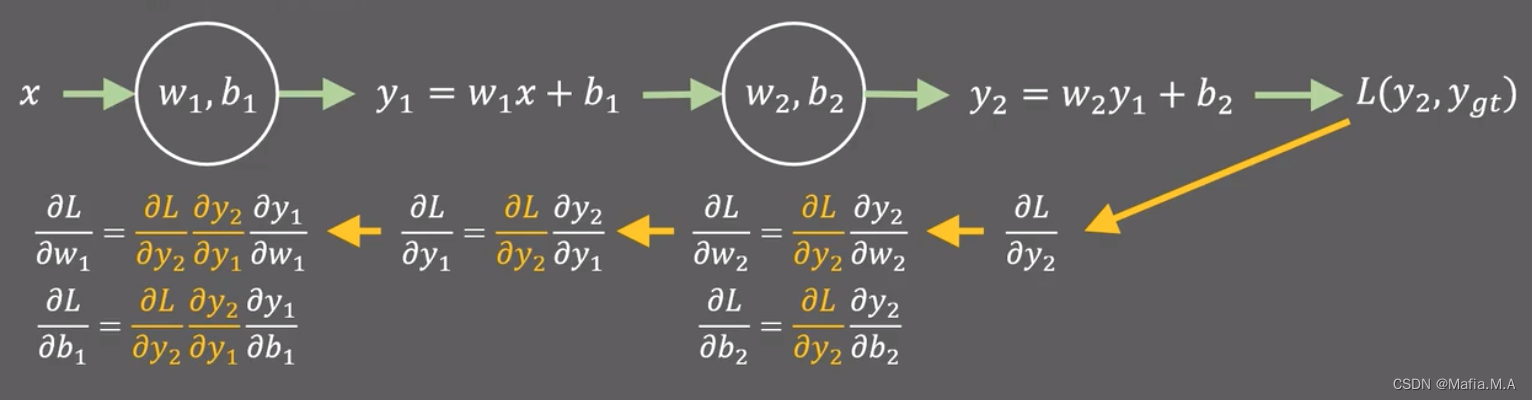
当有两层的时候:
小结
- 前向传播在神经网络定义的计算图中按顺序计算和存储中间变量,它的顺序是从输入层到输出层。
- 反向传播按相反的顺序(从输出层到输入层)计算和存储神经网络的中间变量和参数的梯度。
- 在训练深度学习模型时,前向传播和反向传播是相互依赖的。
- 训练比预测需要更多的内存。
前向传播计算图
其中正方形表示变量,圆圈表示操作符。 左下角表示输入,右上角表示输出。 注意显示数据流的箭头方向主要是向右和向上的。