Android性能优化—数据结构优化
优化数据结构是提高Android应用性能的重要一环。在Android开发中,ArrayList、LinkedList和HashMap等常用的数据结构的正确使用对APP性能的提升有着重大的影响。
一、ArrayList
ArrayList内部使用的是数组,默认大小10,当数组长度不足时,会进行扩容,扩容后的长度为原来的1.5倍。扩容实际上是新建一个长度为原数组1.5的新数组,然后遍历原数组,将数据一一赋值给新数组。
add(position,object) 给指定位置添加元素时,会将该元素及其下标后面的元素都往后移动一位,
最后将add的元素添加到position位置。
delete(position) 删除指定位置元素,删除该元素,并将该元素下标后面的元素都往前移动一位。
由于添加和删除指定位置的元素,其后面的元素需要移动,造成耗时,速度慢,在尾部添加和删除不需要移动,不受影响。
优缺点:
读取速度快,尾部添加和删除速度快,中途添加和删除速度慢。
使用场景:
1)ArrayList提供了常数时间复杂度的随机访问操作(get和set方法),因为它内部使用数组来存储元素,可以通过索引直接访问元素。
2)ArrayList对于在末尾添加或删除元素的操作具有较好的性能,时间复杂度为O(1)。当需要在集合的尾部频繁添加和删除元素时,可以使用ArrayList。
3)ArrayList对于在中间位置插入或删除元素的操作性能较差,因为需要移动后续元素来保持顺序。如果需要频繁在集合的中间位置进行插入或删除操作,LinkedList更适合。
4)在创建ArrayList时,如果能够预估元素数量,可以通过指定初始容量,避免频繁的扩容操作,提高性能。
数组特点:
存储区间是连续,且占用内存严重,空间复杂也很大,时间复杂为O(1)。
优点:是随机读取效率很高,原因数组是连续(随机访问性强,查找速度快)。
缺点:插入和删除数据效率低,因插入数据,这个位置后面的数据在内存中要往后移的,且大小固定不易动态扩展。
二、LinkList
双链表结构,添加和删除速度快;查询需要从头遍历所有节点,速度慢。不需要连续内存,不会导致内存浪费。
链表特点:
区间离散,占用内存宽松,空间复杂度小,时间复杂度O(N)。
优点:插入删除速度快,内存利用率高,没有大小固定,扩展灵活。
缺点:不能随机查找,每次都是从第一个开始遍历(查询效率低)。
使用场景:
1)需要频繁在集合的中间位置插入或删除元素;
2)不需要频繁随机访问元素;
3)需要高效的插入和删除操作而不关心空间开销,LinkedList在插入和删除操作上的性能优于ArrayList,但它需要额外的空间来存储链表节点的指针,因此在空间开销上相对较高。
三、HashMap
1.7及之前使用 数组+链表
1.7之后使用 数组+链表+红黑树
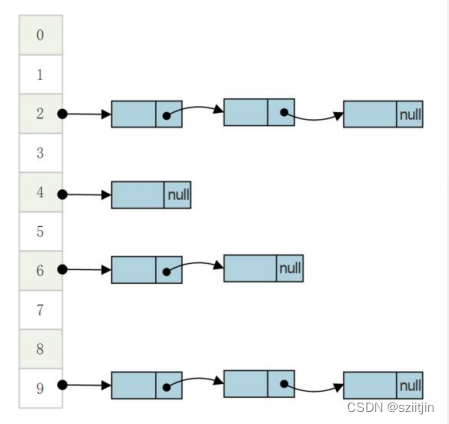
数组+链表:
HashMap数组默认长度16,加载因子默认0.75f,当数组中存储的元素 > 0.75*数组长度 时,需要扩容,将数组长度扩容为原来的2倍,以保证为2的整数次幂。
HashMap以key-value成对出现,一个key对应一个value;
put:key-value
通过key获取hash值,然后跟数组长度取模 == key-value存储在数组的下标;
然后将key、hash值、value、下一个节点,封装成一个节点,插到链表的头节点 -- 头插法
get:key
通过key获取hash值,然后跟数组长度取模 == key-value存储在数组的下标;
然后遍历数组下标元素--链表,通过判断节点的key值一致,返回对应的节点。

扩容:
由于扩容后数组长度不一致,导致按原数组长度计算的下标失效,所以在扩容后,需要将原HashMap保存元素遍历,按新的数组长度,重新计算数组下标,存储。该过程耗时,故尽量在使用HashMap时,评估实际数组的长度,在创建HashMap时指定其长度,避免出现扩容的情况。
优缺点:
数组的特点:查询效率高,插入,删除效率低。
链表的特点:查询效率低,插入删除效率高。
在HashMap底层使用数组+链表+红黑树的结构完美的解决了数组和链表的问题,使得查询和插入,删除的效率都很高。
当数组中存储的元素 > 0.75*数组长度时,需要扩容,导致HashMap至少有25%的空间浪费,无疑是使用了空间换时间的方式去提高效率。
四、SparseArray
Android为了解决HashMap存在的空间浪费问题,推出的新数据类型;采用双数组的方式+HashMap的思想+二分查找,解决HashMap浪费空间的同时,提高了效率。
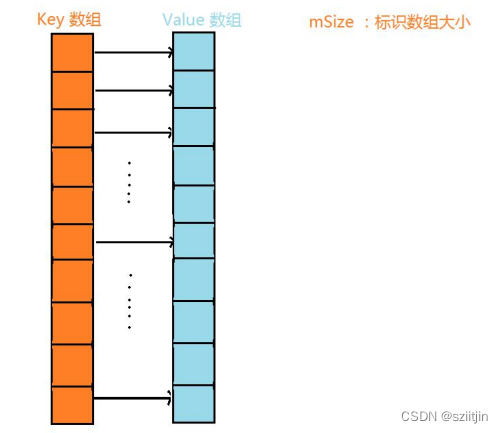
缺点:SparseArray的key只能是int类型
SparseArray采用了延迟删除的机制,通过将删除KEY的Value设置DELETED,方便之后对该下标的存储进行复用;
使用二分查找,时间复杂度为O(LogN),如果没有查找到,那么取反返回左边界,再取反后,左边界即为应该插入的数组下标;
如果无法直接插入,则根据mGarbage标识(是否有潜在延迟删除的无效数据),进行数据清除,再通过System.arraycopy进行数组后移,将目标元素插入二分查找左边界对应的下标;
mSize小于等于keys.length,小于的部分为空数据或者是gc后前移的数据的原数据(也是无效数据),因此二分查找的右边界以mSize为准;
mSize包含了延迟删除后的元素个数;如果遇到频繁删除,不会触发gc机制,导致mSize 远大于有效数组长度,造成性能损耗;
mGarbage为true不一定有无效元素,因为可能被删除的元素恰好被新添加的元素覆盖;

使用场景:
key为整型;不需要频繁的删除;元素个数相对较少。
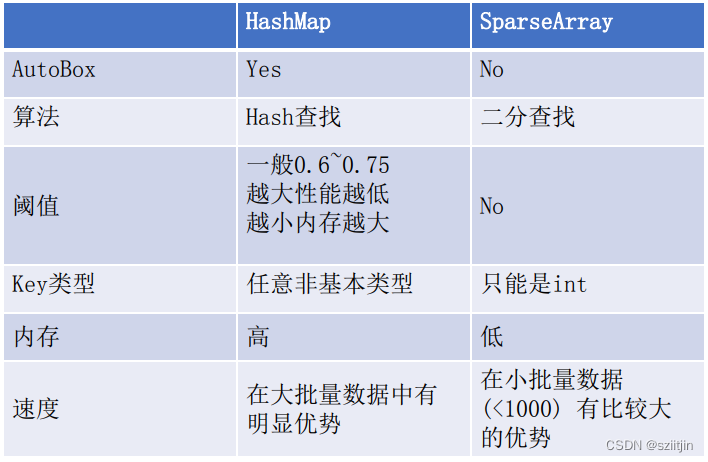
五、ArrayMap
实现了Map接口,并使用int[]数来存储key的hash值,数组的索引用作index,而使用Object[]数组来存储key<->value ,这还是比较新颖的 。
使用二分查找查找hash值在key数组中的位置,然后根据这个位置得到value数组中对应位置的元素。
和SparseArray类似,当数据有几百条时,性能会比HashMap低50%,因此ArrayMap适用于数据量很小的场景
ArrayMap和HashMap的区别:
1)ArrayMap的存在是为了解决HashMap占用内存大的问题,它内部使用了一个int数组用来存储元素的hashcode,使用了一个Object数组用来存储元素,两者根据索引对应形成key-value结构,这样就不用像HashMap那样需要额外的创建Entry对象来存储,减少了内存占用。但是在数据量比较大时,ArrayMap的性能就会远低于HashMap,因为 ArrayMap基于二分查找算法来查找元素的,并且数组的插入操作如果不是末尾的话需要挪动数组元素,效率较低。
2)而HashMap内部基于数组+单向链表+红黑树实现,也是key-value结构, 正如刚才提到的,HashMap每put一个元素都需要创建一个Entry来存放元素,导致它的内存占用会比较大,但是在大数据量的时候,因为HashMap中当出现冲突时,冲突的数据量大于8,就会从单向链表转换成红黑树,而红黑树的插入、删除、查找的时间复杂度为O(logn),相对于ArrayMap的数组而言在插入和删除操作上要快不少,所以数据量上百的情况下,使用HashMap会有更高的效率。
如何解决冲突问题:
在ArrayMap中,假设存在冲突的话,并不会像HashMap那样使用单向链表或红黑树来保留这些冲突的元素,而是全部key、value都存储到一个数组当中,然后查找的话通过二分查找进行,这也就是当数据量大时不宜用ArrayMap的原因了。