网络爬虫简介
前言
没什么可以讲的所以就介绍爬虫吧
介绍
网络爬虫(英语:web crawler),也叫网路蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。
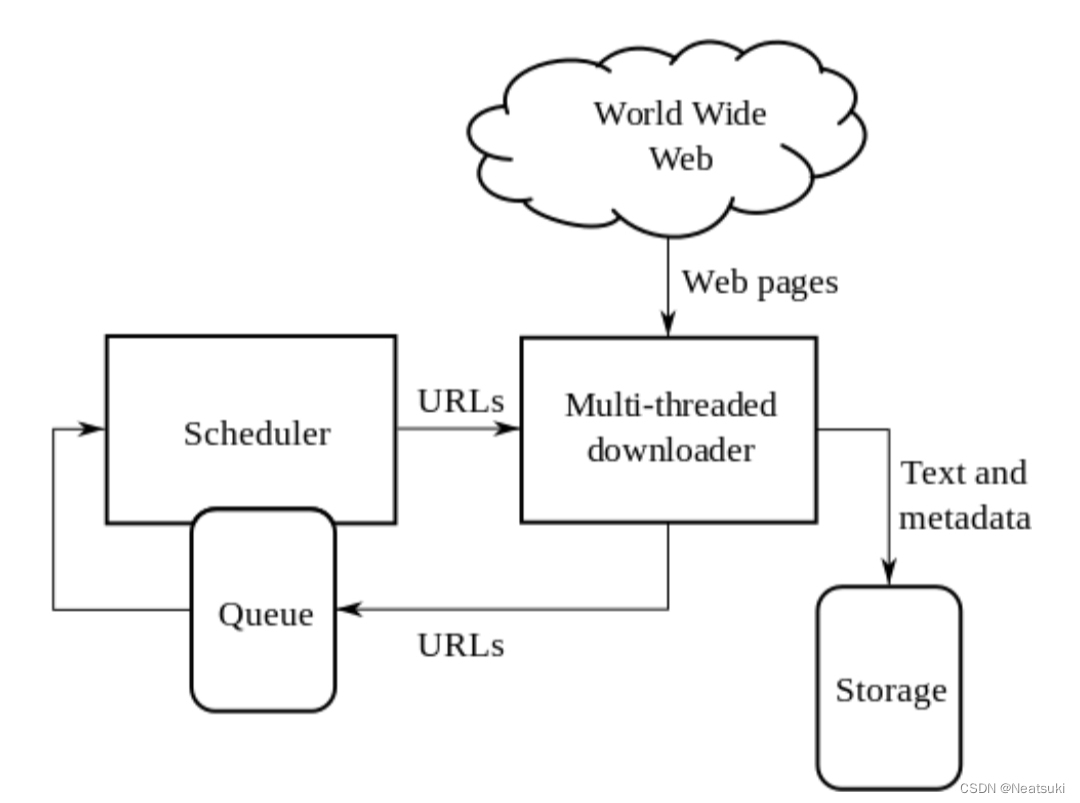
网路搜索引擎等站点通过爬虫软体更新自身的网站内容(英语:Web content)或其对其他网站的索引。网路爬虫可以将自己所访问的页面保存下来,以便搜索引擎事后生成索引(英语:Index (search engine))供用户搜索。
爬虫访问网站的过程会消耗目标系统资源。不少网络系统并不默许爬虫工作。因此在访问大量页面时,爬虫需要考虑到规划、负载,还需要讲“礼貌”。 不愿意被爬虫访问、被爬虫主人知晓的公开站点可以使用robots.txt文件之类的方法避免访问。这个文件可以要求机器人(英语:Software agent)只对网站的一部分进行索引,或完全不作处理。互联网上的页面极多,即使是最大的爬虫系统也无法做出完整的索引。因此在公元2000年之前的万维网出现初期,搜索引擎经常找不到多少相关结果。现在的搜索引擎在这方面已经进步很多,能够即刻给出高质素结果。爬虫还可以验证超连结和HTML代码,用于网络抓取。
命名
网络爬虫也可称作网络蜘蛛、蚂蚁、自动索引程序(automatic indexer),或(在FOAF(英语:FOAF (software))软件中)称为网络疾走(web scutter)。
概述
网络爬虫始于一张被称作种子的统一资源地址(URL)列表。当网络爬虫访问这些统一资源定位器时,它们会甄别出页面上所有的超链接,并将它们写入一张“待访列表”,即所谓爬行疆域(英语:crawl frontier)。此疆域上的URL将会被按照一套策略循环来访问。如果爬虫在执行的过程中复制归档和保存网站上的信息,这些档案通常储存,使他们可以较容易的被查看。阅读和浏览他们储存的网站上并即时更新的信息,这些被储存的网页又被称为“快照”。越大容量的网页意味着网络爬虫只能在给予的时间内下载越少部分的网页,所以要优先考虑其下载。高变化率意味着网页可能已经被更新或者被取代。一些服务器端软件生成的URL(统一资源定位符)也使得网络爬虫很难避免检索到重复内容。
但是互联网的资源卷帙浩繁,这也意味着网络爬虫只能在一定时间内下载有限数量的网页,因此它需要衡量优先顺序的下载方式。有时候网页出现、更新和消失的速度很快,也就是说网络爬虫下载的网页在几秒后就已经被修改或甚至删除了。这些都是网络爬虫设计师们所面临的两个问题。
再者,服务器端软件所生成的统一资源地址数量庞大,以致网络爬虫难免也会采集到重复的内容。根据超文本传输协定,无尽组合的参数所返回的页面中,只有很少一部分确实传回正确的内容。例如:数张快照陈列室的网站,可能通过几个参数,让用户选择相关快照:其一是通过四种方法对快照排序,其二是关于快照分辨率的的三种选择,其三是两种文件格式,另加一个用户可否提供内容的选择,这样对于同样的结果会有48种(432)不同的统一资源地址与其关联。这种数学组合替网络爬虫造成了麻烦,因为它们必须越过这些无关脚本变化的组合,寻找不重复的内容。
爬虫策略
爬虫的实现由以下策略组成:
- 指定页面下载的选择策略
- 检测页面是否改变的重新访问策略
- 定义如何避免网站过度访问的约定性策略
- 如何部署分布式网络爬虫的并行策略
选择策略
链接跟随限制
爬虫可能只想搜索HTML页面而避免其他MIME 类型。为了只请求HTML资源,爬虫在抓取整个以GET方式请求的资源之前,通过创建HTTP的HEAD请求来决定网络资源的MIME类型。为了避免发出过多的请求,爬虫会检查URL和只请求那些以某些字符(如.html, .htm, .asp, .aspx, .php, .jsp, .jspx 或 / )作为后缀的URL。这个策略可能会跳过很多HTML网络资源。
为了避免掉入从网站下载无限量的URL的爬虫陷阱,有些爬虫还能避免请求一些带有“?”的资源(动态生成)。不过假若网站重写URL以简化URL的目的,这个策略就变得不可靠了。
URL规范化
爬虫通常使用某些URL规范化的方式以避免资源的重复爬取。URL规范化,指的是以某种一致的方式修改和标准化URL的过程。这个过程有各种各样的处理规则,包括统一转换为小写、移除“.”和“…”片段,以及在非空路径里插入斜杆。
路径上移爬取
有些爬虫希望从指定的网站中尽可能地爬取资源。而路径上移爬虫就是为了能爬取每个URL里提示出的每个路径。例如,给定一个Http的种子URL: http://llama.org/hamster/monkey/page.html ,要爬取 /hamster/monkey/ , /hamster/ 和 / 。Cothey发现路径能非常有效地爬取独立的资源,或以某种规律无法在站内链接爬取到的资源。
主题爬取
对于爬虫来说,一个页面的重要性也可以说是,给定查询条件一个页面相似性能起到的作用。网络爬虫要下载相似的网页被称为主题爬虫或局部爬虫。这个主题爬虫或局部爬虫的概念第一次被Filippo Menczer和 Soumen Chakrabarti 等人提出的。
重新访问策略
网站的属性之一就是经常动态变化,而爬取网站的一小部分往往需要花费几个星期或者几个月。等到网站爬虫完成它的爬取,很多事件也已经发生了,包括增加、更新和删除。 在搜索引擎的角度,因为没有检测这些变化,会导致存储了过期资源的代价。最常用的估价函数是新鲜度和过时性。 新鲜度:这是一个衡量抓取内容是不是准确的二元值。在时间t内,仓库中页面p的新鲜度是这样定义的:

过时性:这是一个衡量本地已抓取的内容过时程度的指标。在时间t时,仓库中页面p的时效性的定义如下:

平衡礼貌策略
爬虫相比于人,可以有更快的检索速度和更深的层次,所以,他们可能使一个站点瘫痪。不需要说一个单独的爬虫一秒钟要执行多条请求,下载大的文件。一个服务器也会很难响应多线程爬虫的请求。 就像Koster所注意的那样,爬虫的使用对很多工作都是很有用的,但是对一般的社区,也需要付出代价。使用爬虫的代价包括:
网络资源:在很长一段时间,爬虫使用相当的带宽高度并行地工作。
服务器超载:尤其是对给定服务器的访问过高时。
质量糟糕的爬虫,可能导致服务器或者路由器瘫痪,或者会尝试下载自己无法处理的页面。
个人爬虫,如果过多的人使用,可能导致网络或者服务器阻塞。
对这些问题的局部解决方法是漫游器排除协议(Robots exclusion protocol),也被称为robots.txt议定书,这份协议是让管理员指明网络服务器的不应该爬取的约定。这个标准没有包括重新访问一台服务器的间隔的建议,虽然设置访问间隔是避免服务器超载的最有效办法。最近的商业搜索引擎,如Google,Ask Jeeves,MSN和Yahoo可以在robots.txt中使用一个额外的 “Crawl-delay”参数来指明请求之间的延迟。
并行策略
一个并行爬虫是并行运行多个进程的爬虫。它的目标是最大化下载的速度,同时尽量减少并行的开销和下载重复的页面。为了避免下载一个页面两次,爬虫系统需要策略来处理爬虫运行时新发现的URL,因为同一个URL地址,可能被不同的爬虫进程抓到。