BLIP2
BLIP2的任务是基于已有的固定参数的图像encoder和语言大模型(LLM)搭建一个具有图像理解能力的图文模型,输入是图像和文本,输出是文本。
BLIP2基于Q-Former结构,如下图所示。Q-Former包含图像transformer和文本transformer两个transformer。两个transformer的self-attention layer是共享的。图像transformer的输入是固定数量的可学习的query embedding。query embedding先通过self-attention和文本交互,再并通过cross-attention和图像特征交互。Q-Former的cross-attention的参数随机初始化,其他参数用bert的参数初始化。Q-Former的优势是可以从图像encoder中提取出固定长度的特征。
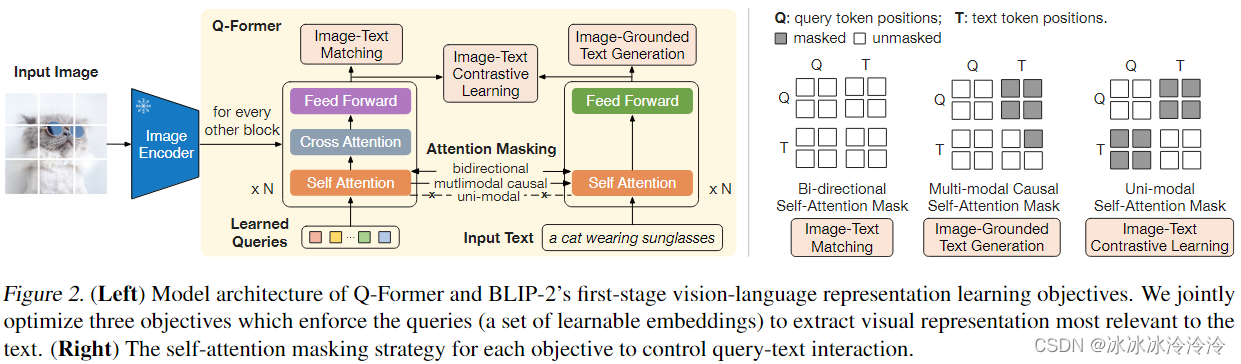
BLIP2的训练分为两步:
- 从固定参数的图像encoder学习视觉文本编码,有Image-Text Contrastive Learning (ITC)、Image-grounded Text Generation (ITG) 、Image-Text Matching (ITM)三个训练目标。
- 从固定参数的LLM学习理解图片生成文本。通过FC层连接Q-Former将queries的映射到和文本token相同维度,拼接在文本前面。
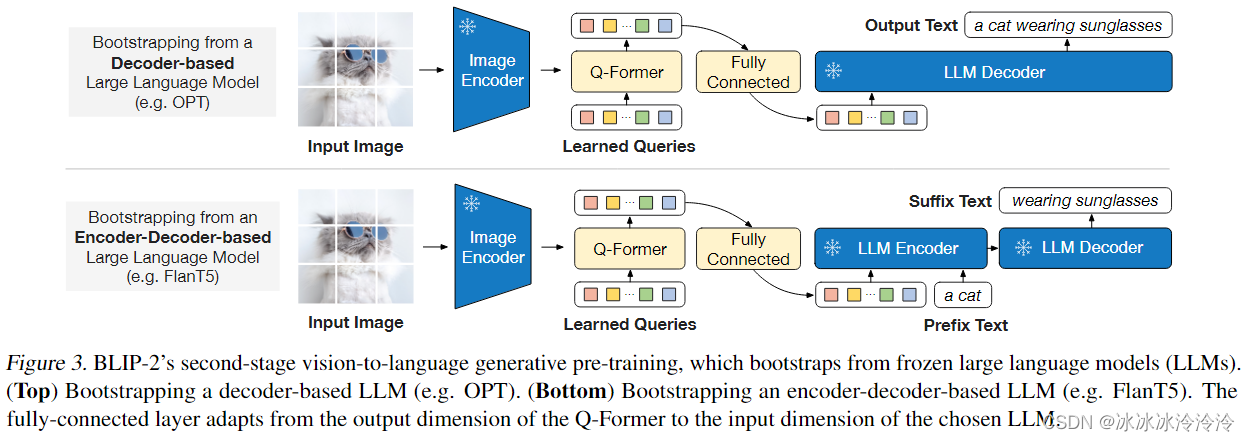
图像encoder选择了CLIP的ViT-L/14和EVA-CLIP的ViT-G/14。LLM选择了OPT和FlanT5。
训练数据包含129M幅图片,来自COCO、Visual Genome、CC3M、 CC12M、SBU、 LAION400M。互联网图片使用CapFilt方法生成文本描述。