机器学习笔记:李宏毅ChatGPT Finetune VS Prompt
1 两种大语言模型:GPT VS BERT

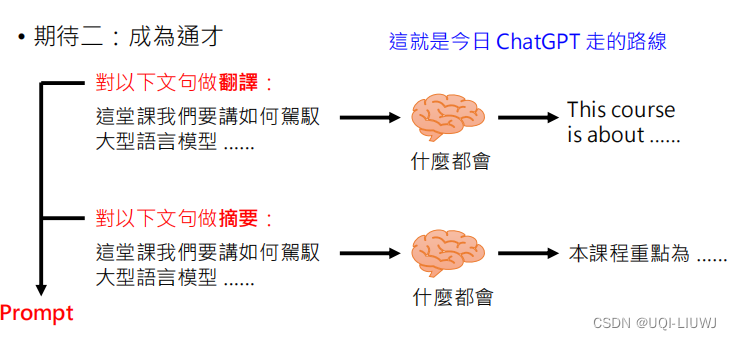
2 对于大语言模型的两种不同期待
2.1 “专才”
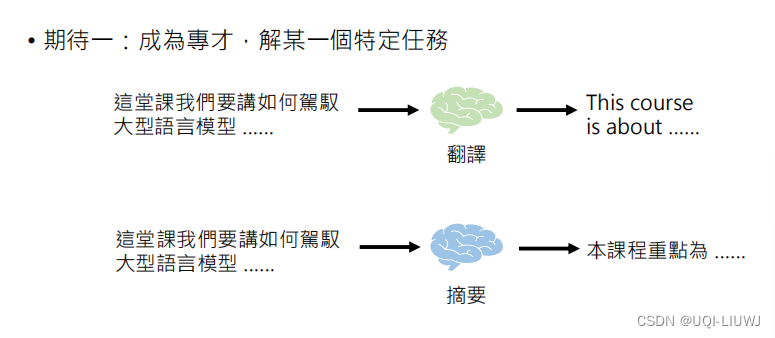
2.1.1 成为专才的好处
Is ChatGPT A Good Translator? A Preliminary Study 2023 Arxiv 箭头方向指的是从哪个方向往哪个方向翻译表格里面的数值越大表示翻译的越好可以发现专门做翻译的工作会比ChatGPT好一些
箭头方向指的是从哪个方向往哪个方向翻译表格里面的数值越大表示翻译的越好可以发现专门做翻译的工作会比ChatGPT好一些
How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation 同样地,专项翻译任务上,ChatGPT不如一些专门做翻译的模型
同样地,专项翻译任务上,ChatGPT不如一些专门做翻译的模型
2.1.2 使用方式
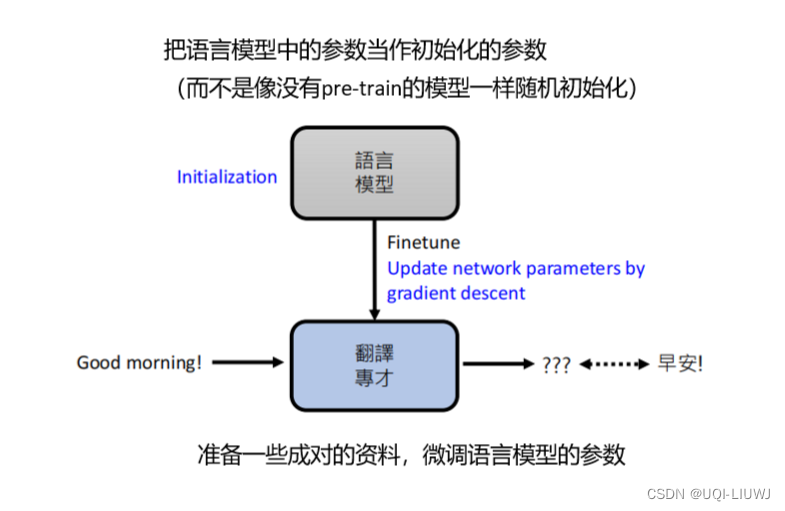
对于训练模型进行改造
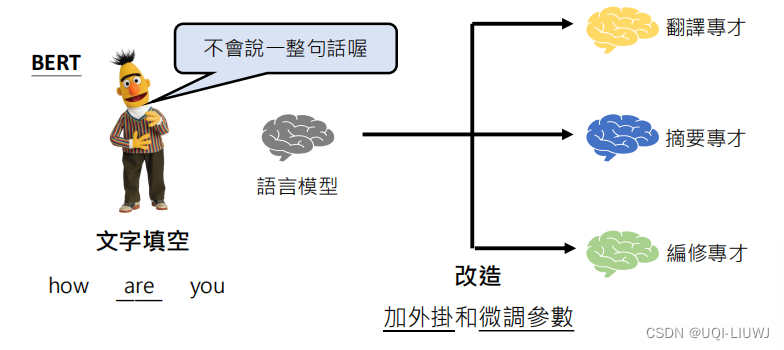
bert的先天劣势就是,他是句子填空,而不是句子接龙,所以希望他进行某一项任务,需要对他进行额外的处理,以及额外的参数微调(finetune)
2.1.2.1 加head
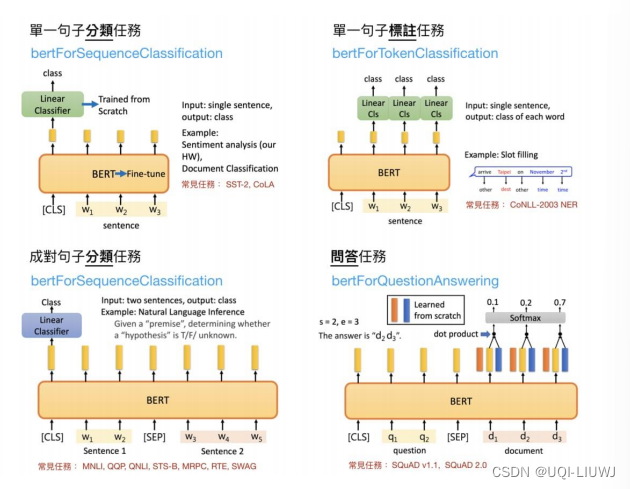
额外地对BERT进行一定的添加,使其能够输出希望的结果
2.1.2.2 微调 Finetune
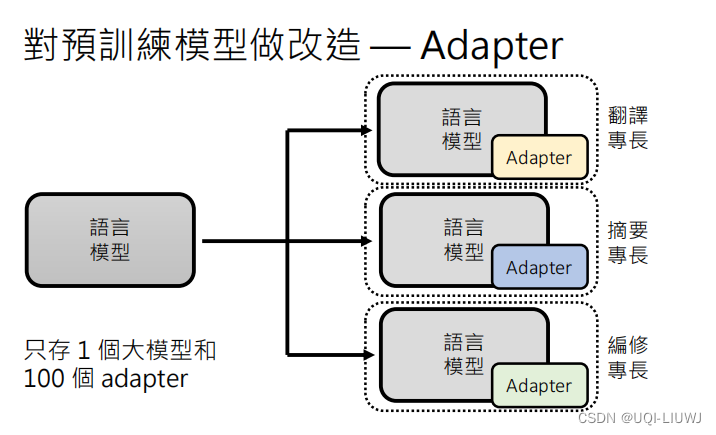
2.1.2.3 对训练模型做改造——加入Adapter
在语言模型里插入额外的模组,语言模型的参数不动,只更新adapter的参数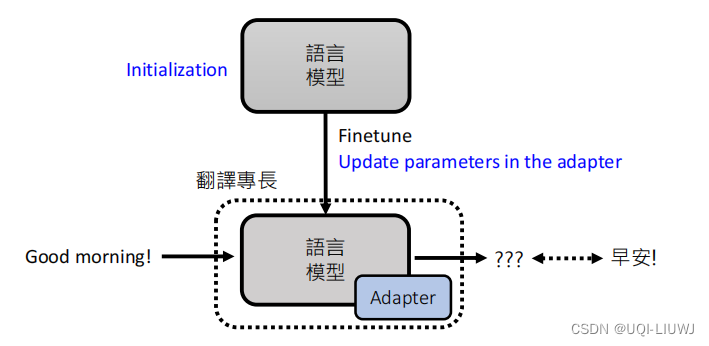
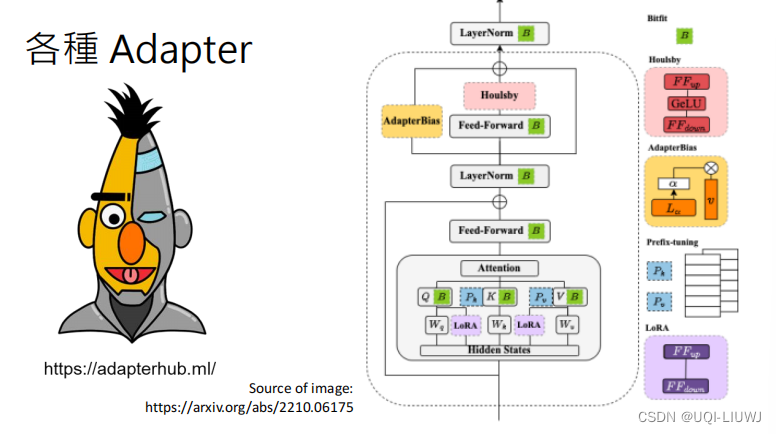
2.1.2.3.1 为什么需要Adapter?
如果没有Adapter的话,100个任务就需要存放100个大模型(的参数)
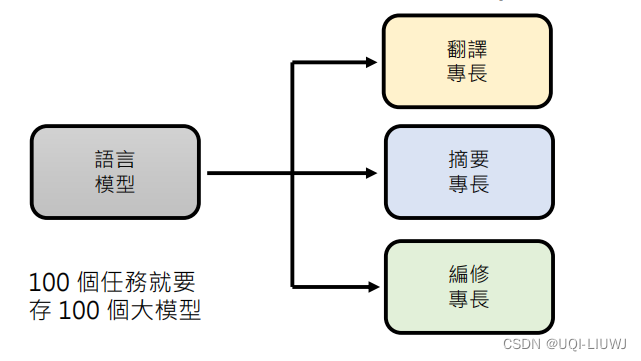
有了Adapter之后,同样的100个任务,我们只需要存一个大模型的参数,和100个任务对应Adapter的参数即可。而一般Adapter的参数量比大模型少多了
2.2 “通才”
通过人类给模型下的指令(prompt)实现,
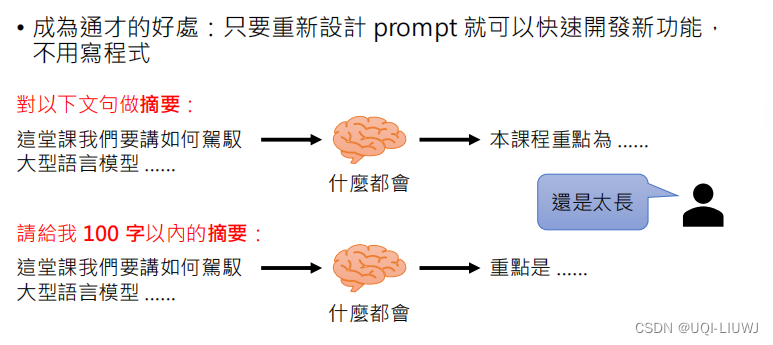
2.2.1 成为通才的好处
2.2.2 In-context Learning
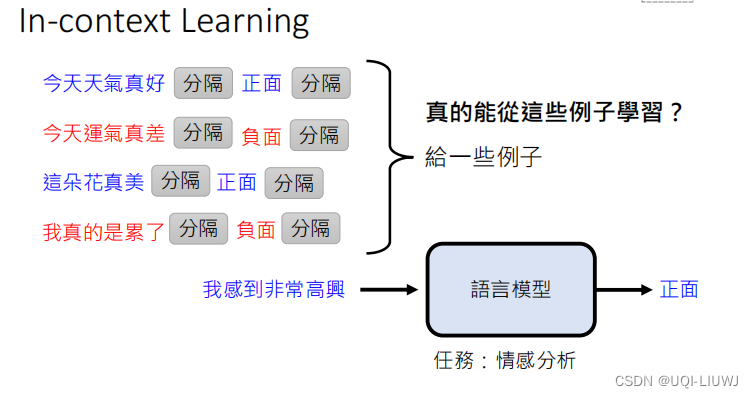
给大语言模型一个句子,让他分析句子是正面的还是负面的
我们需要告诉模型我们要进行情感分析。怎么告诉呢?
- 我们给大模型一些例子,(前面那些句子+情感分析结果)
- 把那些例子串起来,加上我们想要分析的句子,一股脑喂给大模型,让大模型输出是正面还是负面
2.2.2.1 大模型真的能从这些例子中学到信息?
2.2.2.1.1 Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? 2022 ARXIV
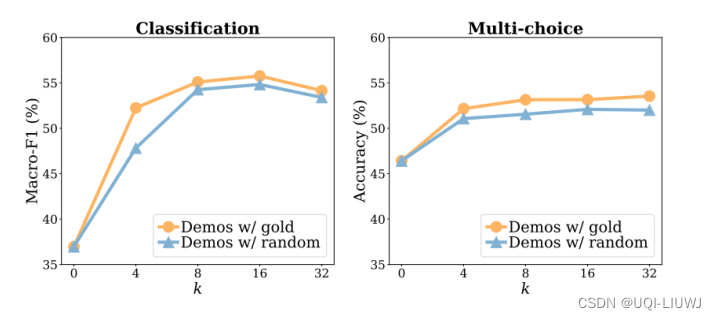
故意给模型输入一些错误的情感分析标注,看模型的分析结果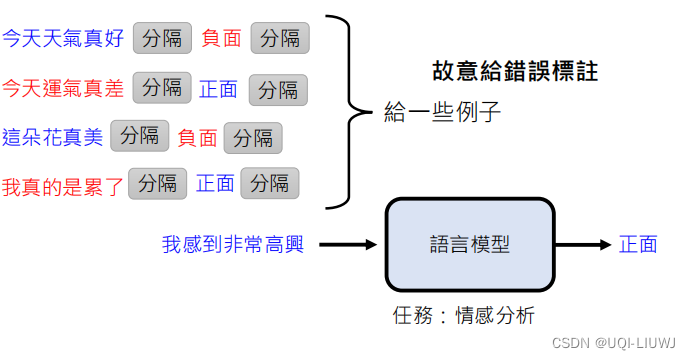
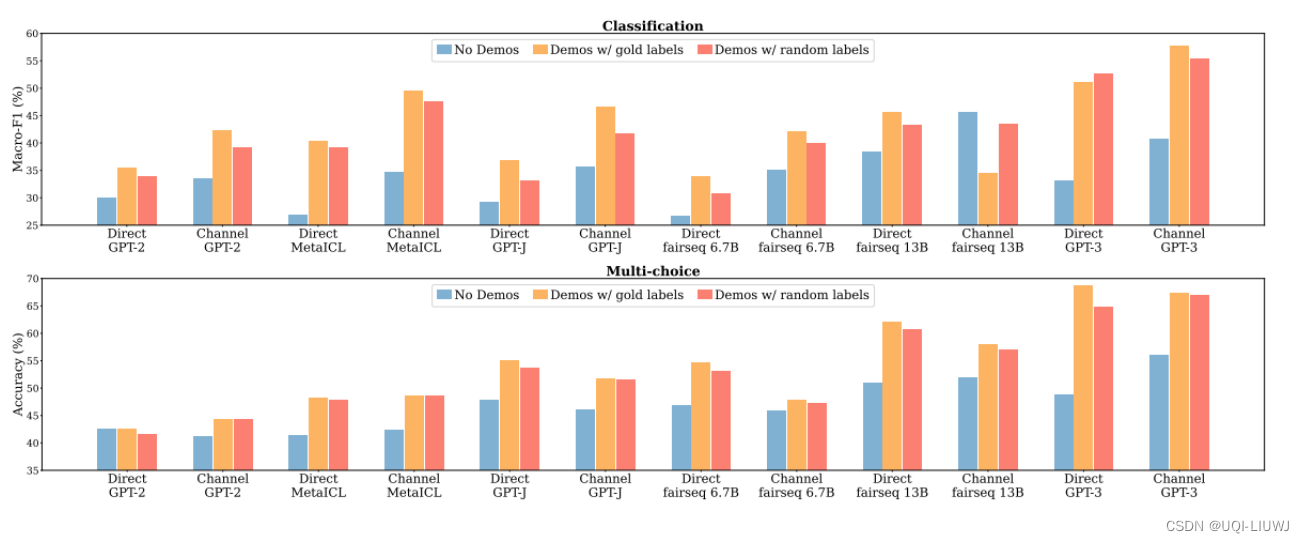
- No demo是没有范例
- 橙色是给了正确的范例
- 红色是给了一些错误的范例
——>可以发现正确率并没有下降很多
并没有从范例里学到很多有用的信息?
那么,故意给一些不在这个domain里面的,无关的输入呢?
这种将无关domain的信息加入的结果就是紫色部分,可以看到如果是来自不同的domain的话,效果会下降
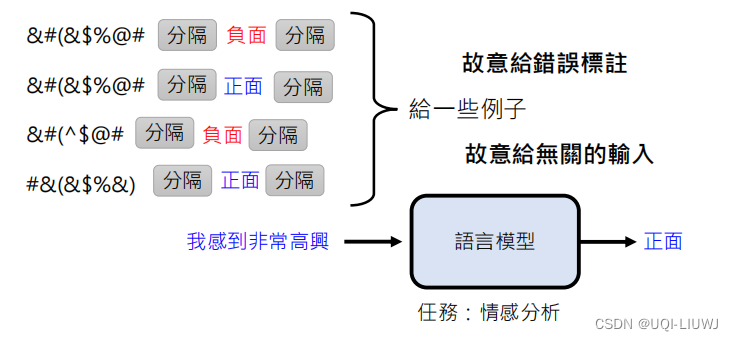
所以这篇论文中,in-context learning作用的猜测是:“唤醒”模型
换句话说,大语言模型本身就会情感分析,in-context learning的作用是“唤醒”他,让语言模型知道接下来做的任务是情感分析
这篇论文的另一个例子也佐证了这个观点,我们提供的句子-情感结果对增加,精度涨的不多(如果是finetune的话,精度会提升的很快)
——>说明并不是靠in-context learning提供的这几个输入来学习情感分析。大语言模型本身就已经具备了情感分析的功能了
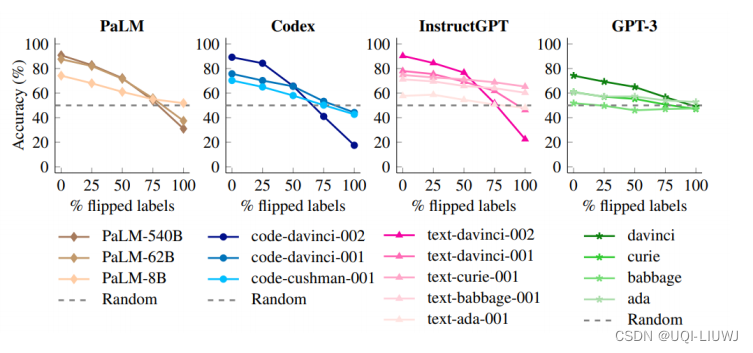
2.2.2.1.2 Larger language models do in-context learning differently 2023 arxiv
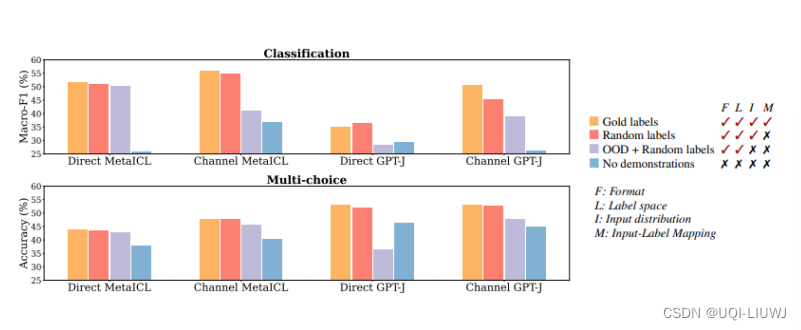
- 每一个图像中,颜色越深的表示模型越大
- 横轴表示in-context learning阶段提供给大模型的有多少比例的是错误的信息
- 可以看到大模型受到错误范例的影响是很大的,而小模型(GPT3,这里的小是相对的小)受到错误范例的影响是不大
- 上一篇paper考虑的是较小的模型,所以可能会觉得给了错误的范例影响不大
- 同时我们可以看到,在大模型中,当in-context learning的错误率为100%(全是相反的结果)的时候,大模型的正确率都是低于50%的,说明他们确实从错误的资料中学到了一些知识
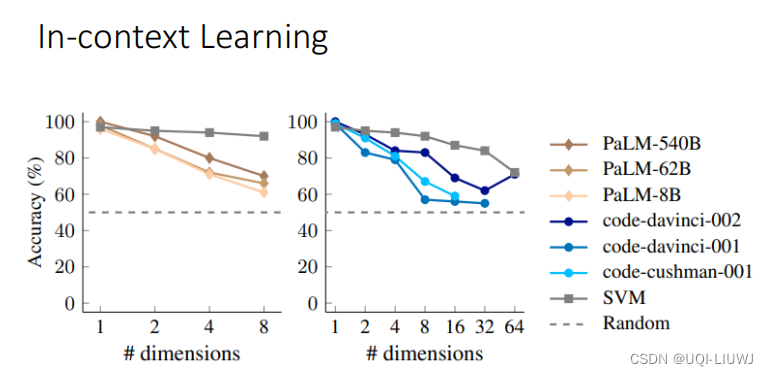
与此同时,我们直接让大模型进行分类任务
我们在in-context learning阶段将input和output全部作为输入提供给大模型,让大模型来进行分类任务
可以看到大模型确实学到了in-context learning中的信息

2.2.2.2 让模型学习 in-context learning
[2110.15943] MetaICL: Learning to Learn In Context (arxiv.org)
前面的in-context learning都是没有finetune过程了,这里相当于finetune了一下
用别的任务的in-context learning的范例、输入、输出进行微调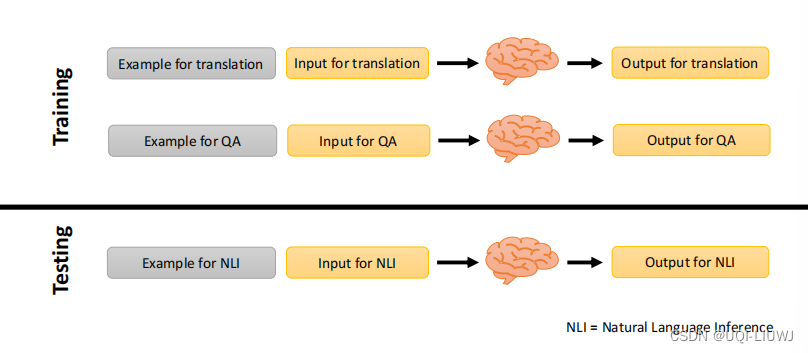
2.2.3 instruction tuninging
大语言模型还是需要进行一定的微调,才能效果比较好,这个微调的过程就是instruction-tuning
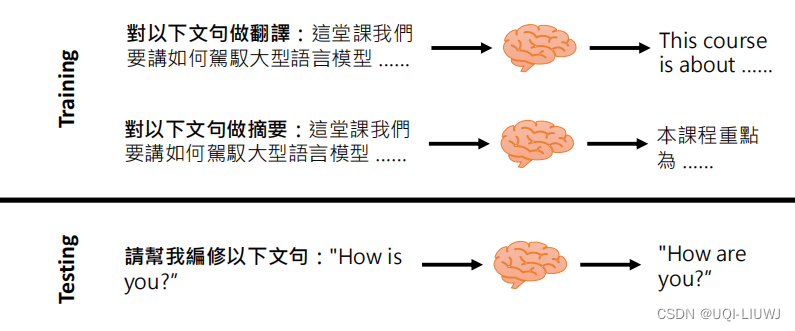
训练(finetune)的时候, 给模型一些指令和对应的答案。测试的时候,给finetune指令之外的其他指令。让模型自己给出合理的回应。
早期模型如Multitask Prompted Training Enables Zero-Shot Task Generalization就提出了一个T0模型,来达成instruction-tuning的效果
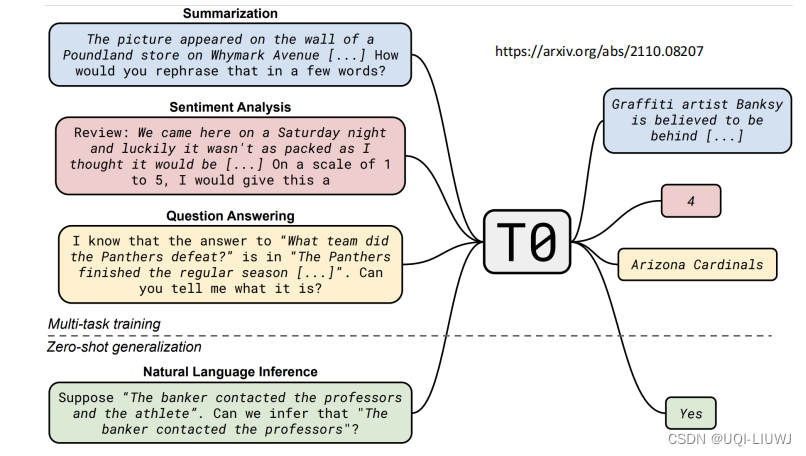
[2109.01652] Finetuned Language Models Are Zero-Shot Learners (arxiv.org)
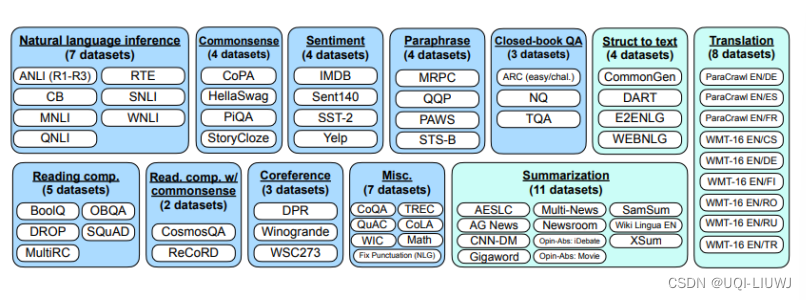
FLAN也是一个早期做instruction tuning的work
首先收集大量的NLP任务和数据集
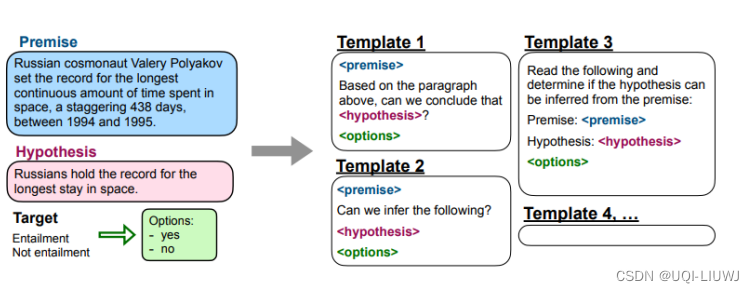
而由于instruction tuning是希望模型理解人类下的指令,所以FLAN每一个NLP的任务想了十种不同的描述方式(template)
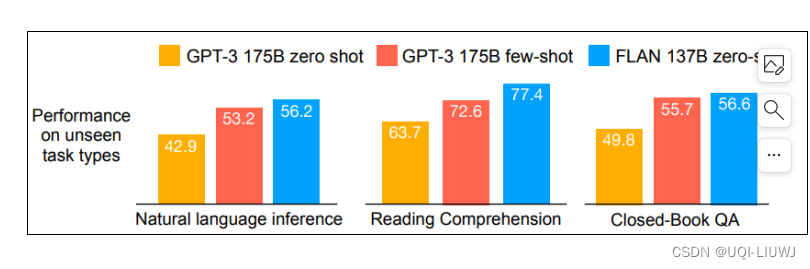
- 当测试任务是natrual language inference的时候,finetune训练的时候就没有这个任务
- zero shot 是只有指令,没有in-context learning
- few-shot就是in-context learning
- FLAN就是进行instruction learning的结果
2.2.4 Chain of Thought
[2201.11903] Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (arxiv.org)
另一种更详细地给机器prompting的方法
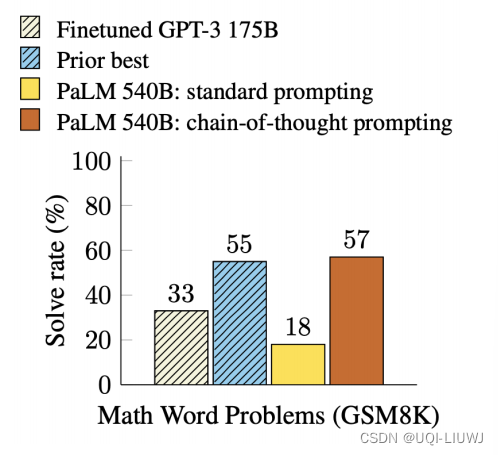
- 如果是数学这种需要推理的问题,直接给 in-context learning 往往效果若不好

- 而如果我们给范例的时候,同时给推导过程+答案。期望模型输出答案的时候,也先输出推导,再输出答案
- 这就叫Chain of Thought Prompting

- 从效果上来看,加了CoT之后的效果更好
2.2.5 加一些prompting,让CoT效果更好
[2205.11916] Large Language Models are Zero-Shot Reasoners (arxiv.org)
在进行CoT的时候,范例输完了,需要模型回答的问题说完了,加一行’Let's think step by step',可以获得更好的效果

Large Language Models Are Human-Level Prompt Engineers ICLR 2023
加的那一行文字不一样,效果也不一样

2.2.6 CoT+Self=consistency
[2203.11171] Self-Consistency Improves Chain of Thought Reasoning in Language Models (arxiv.org)
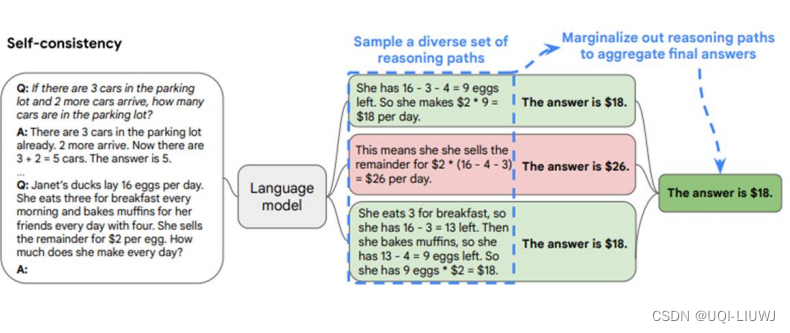
- 使用CoT让模型先输出推导过程,再输出推导结果,可能每次推导过程不一样 答案也不一样
- 这里让语言模型产生好几次推导和对应的结果,出现最多次的答案就是正确答案
- 当然也可以每个答案 用语言模型算一个几率(信心分数)权重
- 但这个权重论文中说没有什么帮助,所以直接根据数量投票就好
2.2.7 强化学习找Prompt
[2206.03931] Learning to Generate Prompts for Dialogue Generation through Reinforcement Learning (arxiv.org)
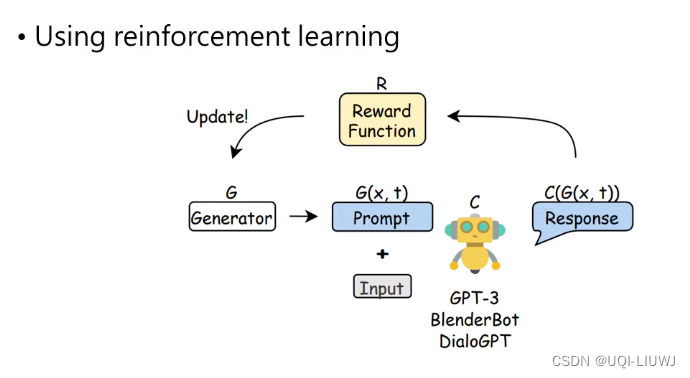
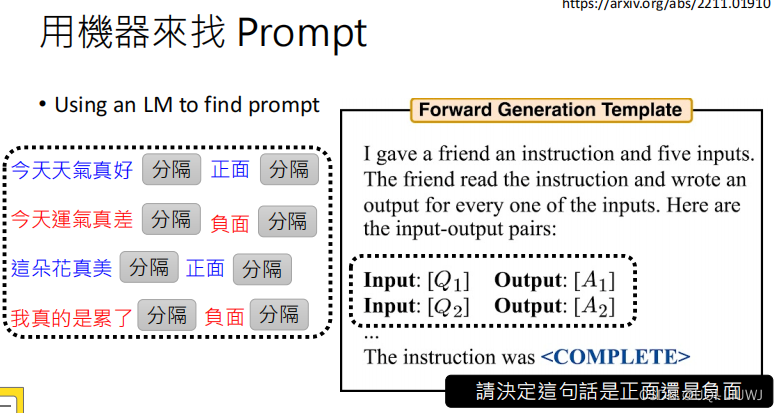
2.2.8 直接用LLM来找Prompt
[2211.01910] Large Language Models Are Human-Level Prompt Engineers (arxiv.org)