词嵌入、情感分类任务
目录
1.词嵌入(word embedding)
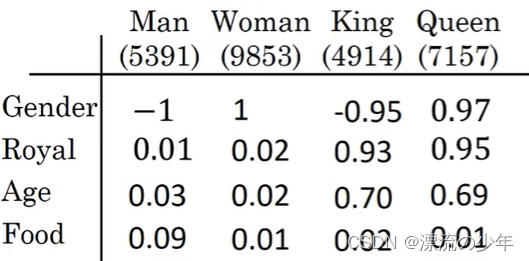
对单词使用one-hot编码的缺点是难以看出词与词之间的关系。

所以需要使用更加特征化的表示(featurized representation),如下图所示,我们可以得到每个词的向量表达。
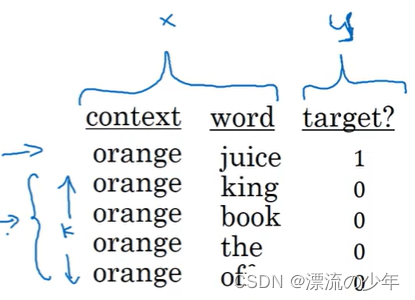
假设训练集中有这样一条序列:I want a glass of orange juice to go along with my cereal.
在skip-grams模型中,我们要做的就是抽取上下文和目标词配对,来构造一个监督学习任务。
(PS:skip-gram模型是根据中心词预测上下文m个词的算法,m是用户自己定义的预测窗口大小)
在模型中,以上下文作为输入,来预测目标词,conten c("orange")->...->softmax->y。
但是使用softmax计算概率过于费时,。(10000表示词汇表的数量,
是关于输出target的参数)。
解决办法:
①可以使用分级的softmax分类器(hierarchical softmax classifier)。例如,第一个分类器告诉你目标在前5000个单词中,第二个分类器告诉你目标在前2500个单词中...
②负采样(negative sampling)。假设有1个正样本和k个负样本,只需要k+1个二分类logistic回归分类器(binary logistic regression classfiers)即可。
2.情感分类任务
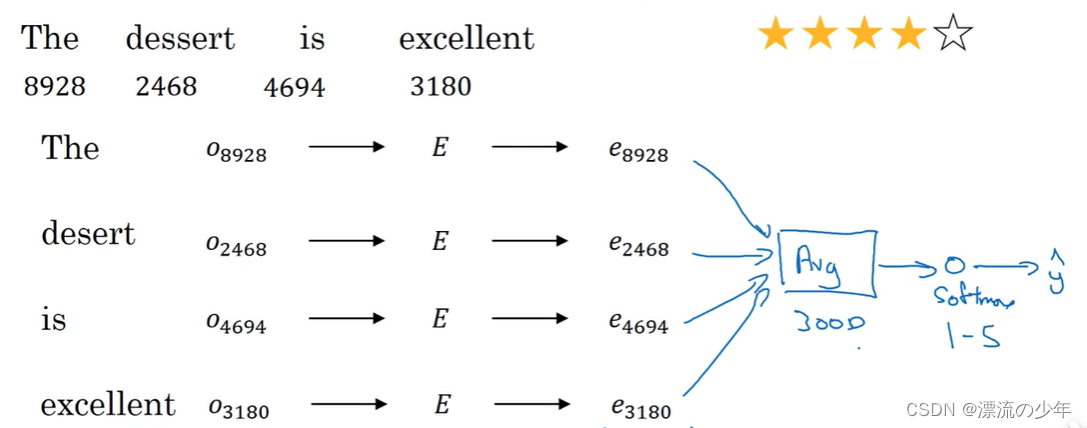
例如,对一个餐馆进行评价,需要对评论的情绪进行分类。

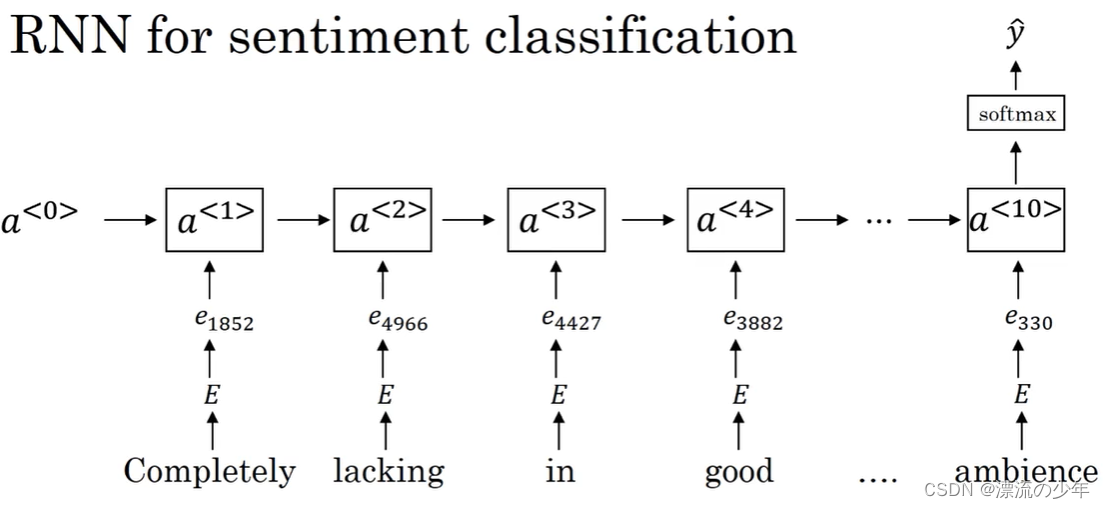
对于该任务,可以使用普通的分类网络,对每个词嵌入向量求和或取平均,最后输入到softmax层进行分类。但是这样没有考虑词序。比如"Completely lacking in good taste, good service, and good ambience"这样的评论虽然有很多“good”,但其实是负面评论。
可以考虑使用RNN。