Docker下快速搭建RabbitMQ单例及集群
引子
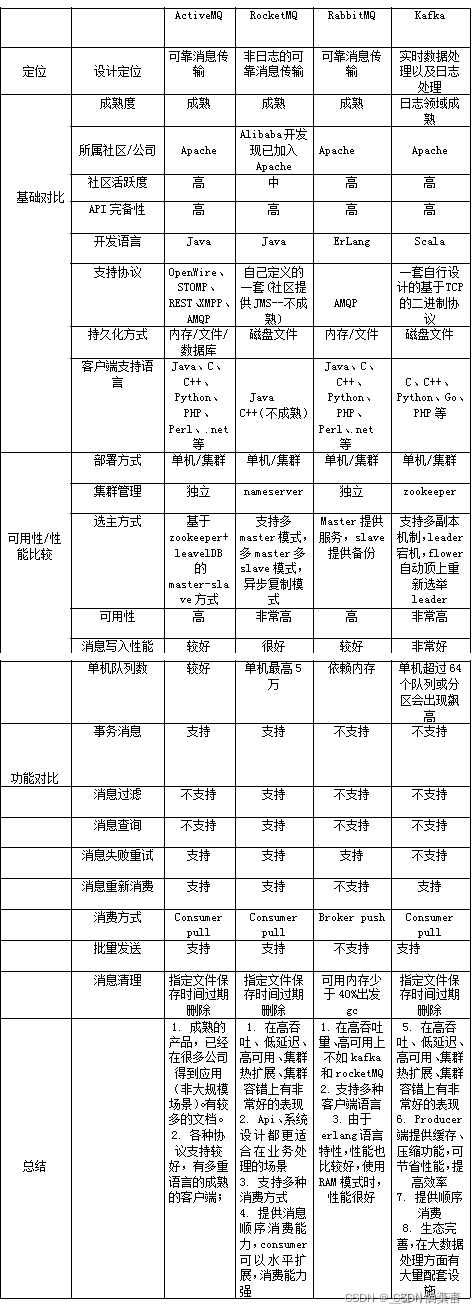
生命在于折腾,为上数据实时化用到了消息传送的内容,当时也和总公司人员商量选型,kafka不能区分分公司就暂定用了RbtMQ
刚好个人也在研究容器及分布式部署相关内容就在docker上实践
单机 docker(要想快 先看问题 避免踩坑)
启动web控制台
启用RabbitMQ Web管理控制台,方法是运行:
rabbitmq-plugins enable rabbitmq_management添加用户及赋权
rabbitmqctl add_user admin StrongPassword
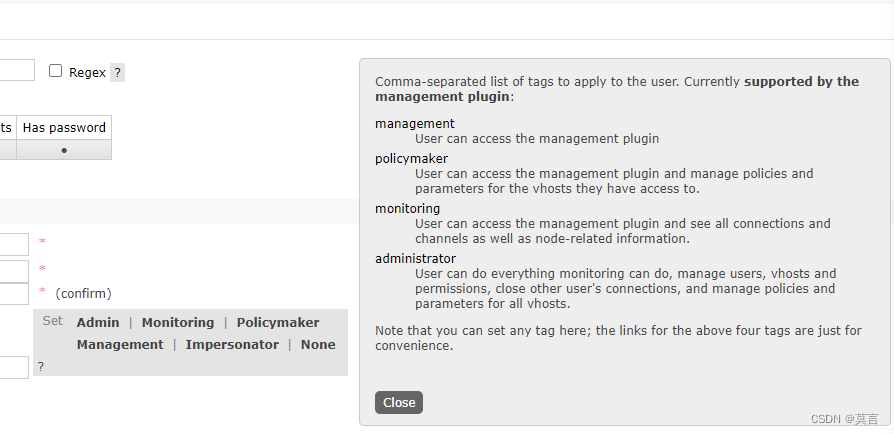
rabbitmqctl set_user_tags admin administrator
rabbitmqctl set_permissions -p / admin “.*” “.*” “.*”角色定义
要访问RabbitMQ的管理面板,请使用您最喜爱的Web浏览器并打开以下URL。
http://Your_Server_IP:15672/
基本上用官方发布的镜像直接拉过来 就能用了
遇到的问题
1 进不去管理端
docker pull rabbitmq但是建议在docker pull的时候可以选择带上management,可以省事一点
docker pull rabbitmq:management此处最好修改host 将主控的docker容器ID在此填写 --add-host[单机docker暂时用不上]
docker run -di --name=rbtmq-mst -p 5671:5671 -p 5672:5672 -p 4369:4369 -p 15671:15671 -p 15672:15672 -p 25672:25672 rabbitmq:management# tmp 集群时要用到
-e RABBITMQ_ERLANG_COOKIE='rabbitcookie'
--link rabbitmq1:rabbit1
docker ps
docker exec -it 镜像ID /bin/bash
rabbitmq-plugins enable rabbitmq_management2 Stats in management UI are disabled on this node
即打开统计开关
#进入rabbitmq容器
docker exec -it {rabbitmq容器名称或者id} /bin/bash
#进入容器后,cd到以下路径
cd /etc/rabbitmq/conf.d/
#修改 management_agent.disable_metrics_collector = false
echo management_agent.disable_metrics_collector = false > management_agent.disable_metrics_collector.conf
#退出容器
exit
#重启rabbitmq容器
docker restart {rabbitmq容器id或容器名称}关于cluster集群
docker run -di --hostname rbtmq_mst --name rbtmq_mst -p 5671:5671 -p 5672:5672 -p 4369:4369 -p 15671:15671 -p 15672:15672 -p 25672:25672 -e RABBITMQ_ERLANG_COOKIE='rabbitcookie' rabbitmq:management
docker run -di --hostname rbtmq_slv1 --name rbtmq_slv1 -p 5871:5671 -p 5872:5672 -p 4569:4369 -p 17671:15671 -p 17672:15672 -p 27672:25672 --link rbtmq_mst:rbtmq_mst -e RABBITMQ_ERLANG_COOKIE='rabbitcookie' rabbitmq:management
docker run -di --hostname rbtmq_slv2 --name rbtmq_slv2 -p 5971:5671 -p 5972:5672 -p 4769:4369 -p 19671:15671 -p 19672:15672 -p 29672:25672 --link rbtmq_mst:rbtmq_mst --link rbtmq_slv1:rbtmq_slv1 -e RABBITMQ_ERLANG_COOKIE='rabbitcookie' rabbitmq:managementRABBITMQ_ERLANG_COOKIE env variable support is deprecated and will be REMOVED in a future version. Use the $HOME/.erlang.cookie file or the --erlang-cookie switch instead.
参数过时 ,以下覆盖方法待测试解决
docker cp rbtmq_mst:/var/lib/rabbitmq d:\tmp\
docker cp d:\tmp\rabbitmq\.erlang.cookie rbtmq_slv2:/var/lib/rabbitmq/
chmod 600 /var/lib/rabbitmq/.erlang.cookie
上述建完之后 需要重新刷新app,
docker exec -it rbtmq_slv1 bash
并将从机加入到集群中
root@rbtmq_slv1:/# rabbitmqctl stop_app
root@rbtmq_slv1:/# rabbitmqctl reset
root@rbtmq_slv1:/# rabbitmqctl join_cluster --ram rabbit@rbtmq_mst
Clustering node rabbit@rbtmq_slv1 with rabbit@rbtmq_mst
root@rbtmq_slv1:/# rabbitmqctl start_app
Starting node rabbit@rbtmq_slv1 ...
--ram 和--disc区别RabbitMQ对于queue中的message的保存方式有两种方式:disc和ram。如果采用disc,则需要对exchange/queue/delivery mode都要设置成durable模式。Disc方式的好处是当RabbitMQ失效了,message仍然可以在重启之后恢复。使用ram方式,RabbitMQ处理message的效率要高很多,ram和disc两种方式的效率比大概是3:1。所以如果在有其它HA手段保障的情况下,选用ram方式是可以提高消息队列的工作效率的。如果使用ram方式,RabbitMQ能够承载的访问量则取决于可用的内存数了。RabbitMQ使用两个参数来限制使用系统的内存,避免系统被自己独占。作者:Bogon链接:https://www.jianshu.com/p/6df48edda72e来源:简书著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
测试用例[用PY唯快,无他尔]
发消息
# This is a sample Python script.
import pika
# Press Shift+F10 to execute it or replace it with your code.
# Press Double Shift to search everywhere for classes, files, tool windows, actions, and settings.
def print_hi(name):# Use a breakpoint in the code line below to debug your script.print(f'Hi, {name}') # Press Ctrl+F8 to toggle the breakpoint.
# Press the green button in the gutter to run the script.
if __name__ == '__main__':print_hi('PyCharm')connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
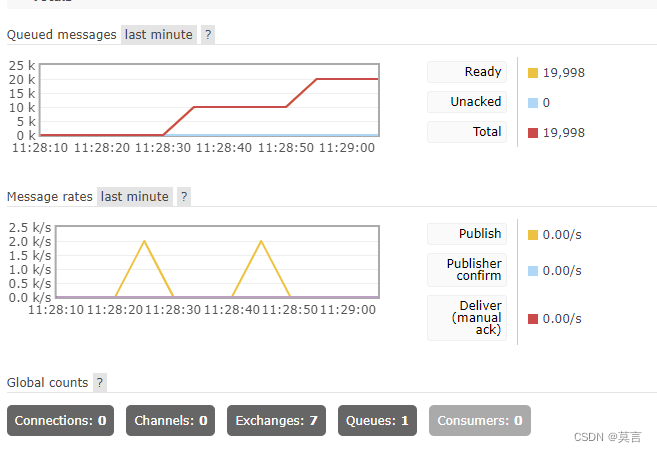
for i in range (9999999,0,-1):channel.basic_publish(exchange='',routing_key='hello',body='helllllllo '+str(i))print("[x] send message")
# See PyCharm help at https://www.jetbrains.com/help/pycharm/消费消息
import pikaconnection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='hello')
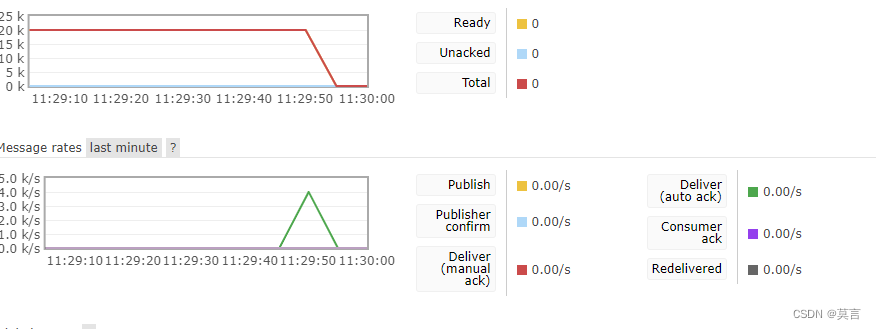
def callback(ch,method,properties,body):print("[x] Rev %r" % body)channel.basic_consume(queue='hello',auto_ack=True,on_message_callback=callback)print('[*] Waiting for MSG. Exit by Ctrl+C')channel.start_consuming()