基于注意力的知识蒸馏Attention Transfer原理与代码解析
paper:Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfer
code:https://github.com/megvii-research/mdistiller/blob/master/mdistiller/distillers/AT.py
背景
一个流行的假设是存在非注意non-attentional和注意attentional感知过程,非注意感知有助于从整体观察一个场景并获取high-level信息,注意力感知过程会将我们导向并更关注某个局部。不同的观察者有不同的知识,不同的目标,因此有不同的注意力策略,从而以不同方式看待同一场景。本文研究的主题是一个教师网络能否通过向学生网络传递它的注意力信息(即它更关注哪些区域)来提升学生网络的性能。
本文的创新点
本文提出将注意力作为一种将知识从教师网络传递给学生网络的机制。对于一个给定的卷积神经网络,首先需要合适地定义注意力,作者将注意力看做是一组spatial maps,给定输入spatial map上编码了网络最关注的空间区域。本文还提出了同时使用基于激活的和基于梯度的空间注意力图,并通过实验表明了基于注意力的知识蒸馏的有效性,同时表明了基于激活的注意力传递比单纯基于激活的知识传递效果更好。
方法介绍
给定CNN某层的输出激活张量 \(A\in R^{C\times H\times W}\),输入到一个基于激活的映射函数 \(\mathcal{F}\) 得到得到一个spatial attention map

这里隐含的假设是一个隐含神经元激活值的绝对值可以用来表明该神经元对某个特定输入的重要程度,比如注意力图上某个位置的值越大说明网络越关注该位置。基于该假设,我们可以沿通道维度上计算这些值的统计数据来构建一个空间注意力图。如下图所示
本文主要考虑了以下三种统计方法

我们假设教师网络和学生网络之间的注意力传递发生在相同分辨率的注意力图上,当分辨率不一致时也可以通过插值来进行匹配。一个示例如下图所示,其中教师和学生网络都是残差网络,在每个stage的最后进行注意力知识的传递,即计算对应attention map之间的损失。

定义 \(S,T\) 和 \(\mathbf{W_{S}},\mathbf{W_{T}}\) 分别表示学生和教师网络以及对应的模型权重,\(\mathcal{L}\left ( \mathbf{W},x \right ) \) 是交叉熵损失,\(\mathcal{I}\) 是所有教师和学生网络对应注意力图的索引。完整损失函数如下
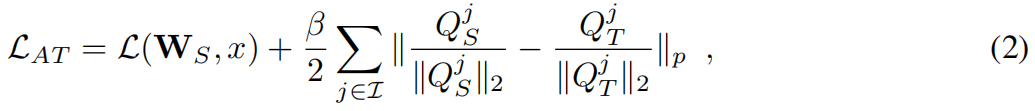
其中 \(Q_{S}^{j}=vec(F(A^{j}_{S}))\) 和 \(Q_{T}^{j}=vec(F(A^{j}_{T}))\) 别是学生网络和教师网络第 \(j\) 层的向量形式的注意力图,\(p\) 是范数类型本文默认 \(p=2\)。注意力的知识传递还可以和知识蒸馏结合使用,只需要在式(2)中加一项教师和学生软化标签分布之间的交叉熵损失项即可。
代码解析
其中函数at_loss从教师和学生网络中一一取出对应层的特征图f_s和f_t,函数single_stage_at_loss计算对应单层之间的注意力损失。
import torch
import torch.nn as nn
import torch.nn.functional as Ffrom ._base import Distillerdef single_stage_at_loss(f_s, f_t, p):def _at(feat, p):# (64,64,32,32)->(64,64,32,32)->(64,32,32)->(64,1024)->(64,1024)return F.normalize(feat.pow(p).mean(1).reshape(feat.size(0), -1)) # 沿通道取means_H, t_H = f_s.shape[2], f_t.shape[2]if s_H > t_H:f_s = F.adaptive_avg_pool2d(f_s, (t_H, t_H))elif s_H < t_H:f_t = F.adaptive_avg_pool2d(f_t, (s_H, s_H))# (64,1024)-(64,1024)->(64,1024)->()return (_at(f_s, p) - _at(f_t, p)).pow(2).mean()def at_loss(g_s, g_t, p):return sum([single_stage_at_loss(f_s, f_t, p) for f_s, f_t in zip(g_s, g_t)])class AT(Distiller):"""Paying More Attention to Attention: Improving the Performance of Convolutional Neural Networks via Attention Transfersrc code: https://github.com/szagoruyko/attention-transfer"""def __init__(self, student, teacher, cfg):super(AT, self).__init__(student, teacher)self.p = cfg.AT.Pself.ce_loss_weight = cfg.AT.LOSS.CE_WEIGHTself.feat_loss_weight = cfg.AT.LOSS.FEAT_WEIGHTdef forward_train(self, image, target, **kwargs):logits_student, feature_student = self.student(image)with torch.no_grad():_, feature_teacher = self.teacher(image)# lossesloss_ce = self.ce_loss_weight * F.cross_entropy(logits_student, target)loss_feat = self.feat_loss_weight * at_loss(feature_student["feats"][1:], feature_teacher["feats"][1:], self.p)losses_dict = {"loss_ce": loss_ce,"loss_kd": loss_feat,}return logits_student, losses_dict