Spark写PGSQL分区表
这里写目录标题
- 需求
- 碰到的问题
- 格式问题
- 分区问题(重点)
- 解决
- 完整代码
- 效果
需求
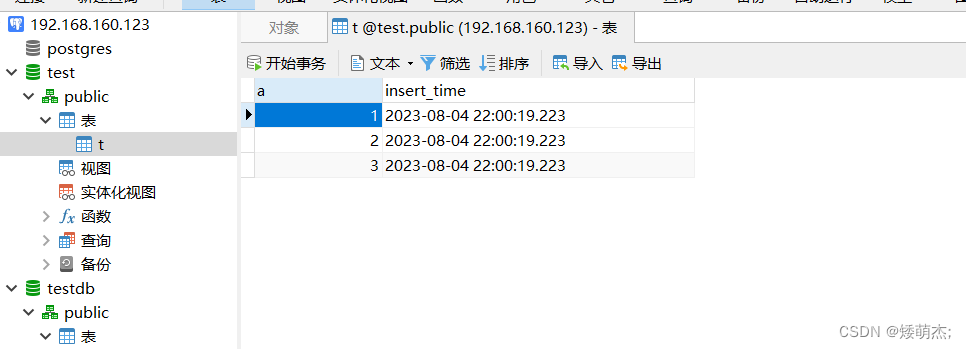
spark程序计算后的数据需要往PGSQL中的分区表进行写入。
碰到的问题
格式问题
使用了字符串格式,导致插入报错。
val frame = df.withColumn("insert_time",current_timestamp()))
Batch entry 0 INSERT INTO t ("a","insert_time") VALUES
(1,'2023-08-01 10:00:00') was aborted: ERROR: column
"insert_time" is of type timestamp without time zone but
expression is of type character varying
分区问题(重点)
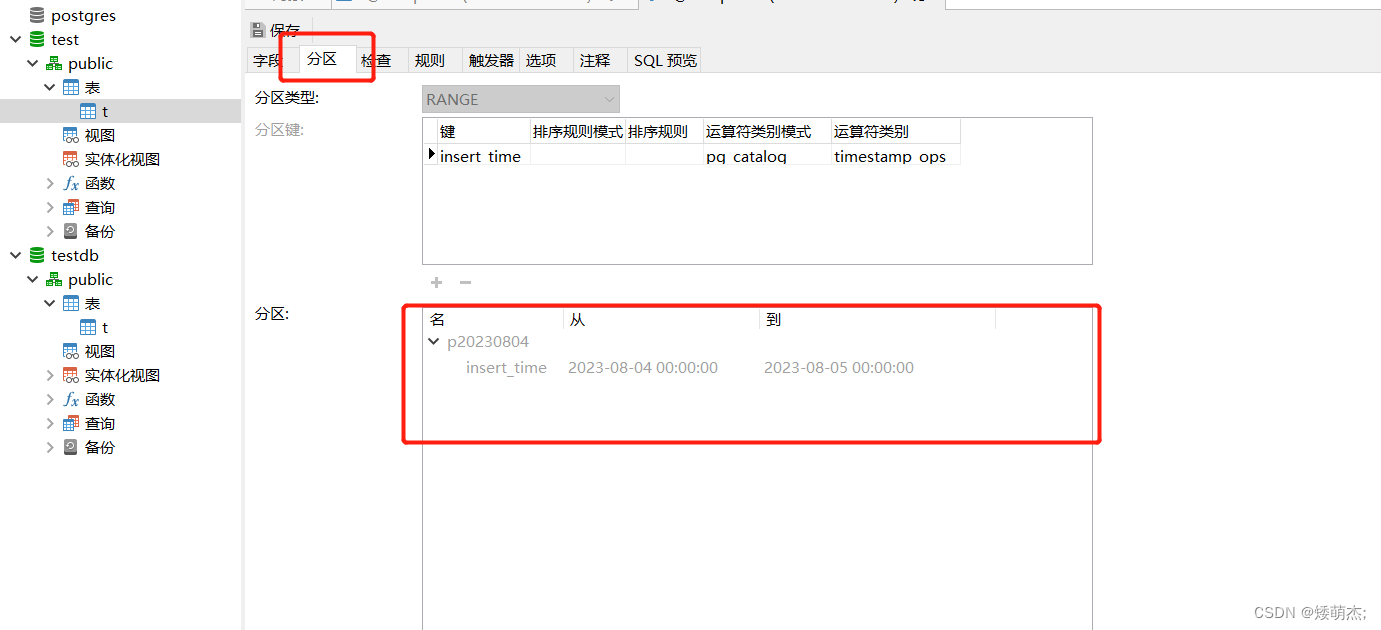
一直都是spark计算完后写单表或者hive的表,都需要去手动去维护分区。但是写PGSQL空表(只有表字段,还没有数据,没有创建分区),需要手动先创建分区,否则会报错。
报错信息
Partition key of the failing row contains (insert_time) =
(2023-08-04 21:14:09.641). Call getNextException to see other
errors in the batch.
插入失败的行的分区键包含的时间戳值 2023-08-04 21:14:09.641 在分区表中找不到对应的分区范围。
解决
最终的解决方案是在插入数据之前,通过代码去添加分区,添加好分区后再写入数据即可。
object WritePgSQL {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("SparkPostgreSQLPartitionedTable").config("spark.master", "local").getOrCreate()// 设置PostgreSQL连接信息val postgresUrl = "jdbc:postgresql://192.168.160.123:5432/test"val connectionProperties = new java.util.Properties()connectionProperties.setProperty("user", "test")connectionProperties.setProperty("password", "123456")// 创建测试数据val data = Seq((1, "2023-08-01 10:00:00"),(2, "2023-08-02 12:00:00"),(3, "2023-08-03 15:00:00"))val columns = Seq("a", "insert_time1")val df = spark.createDataFrame(data).toDF(columns: _*)val frame = df.drop("insert_time1").withColumn("insert_time", current_timestamp().cast("timestamp"))// 动态创建分区范围// p1 可以换成p20230804这样的分区格式// t为表名// (TIMESTAMP '2023-08-04 00:00:00') 分区开始范围,一般通过代码生成,为计算时间的零点// (TIMESTAMP '2023-08-05 00:00:00') 分区结束范围,一般通过代码生成,为计算时间的下一天零点val createPartitionSql =s"""CREATE TABLE "p1" PARTITION OF t FOR VALUES FROM (TIMESTAMP '2023-08-04 00:00:00') TO (TIMESTAMP '2023-08-05 00:00:00') ;"""println(createPartitionSql)// 执行创建分区 SQLval connection = java.sql.DriverManager.getConnection(postgresUrl, connectionProperties)val statement = connection.createStatement()statement.executeUpdate(createPartitionSql)connection.close()// 将数据写入PostgreSQL分区表frame.write.mode("append").jdbc(postgresUrl, "t", connectionProperties)}
}完整代码
自动生成当天日期和分区名称
object WritePgSQL {def main(args: Array[String]): Unit = {val spark = SparkSession.builder().appName("SparkPostgreSQLPartitionedTable").config("spark.master", "local").getOrCreate()// 设置PostgreSQL连接信息val postgresUrl = "jdbc:postgresql://192.168.160.123:5432/test"val connectionProperties = new java.util.Properties()connectionProperties.setProperty("user", "test")connectionProperties.setProperty("password", "123456")// 创建测试数据val data = Seq((1, "2023-08-01 10:00:00"),(2, "2023-08-02 12:00:00"),(3, "2023-08-03 15:00:00"))val columns = Seq("a", "insert_time1")val df = spark.createDataFrame(data).toDF(columns: _*)val frame = df.drop("insert_time1").withColumn("insert_time", current_timestamp().cast("timestamp"))// 获取今天和明天的时间范围// 获取当前日期val currentDate = LocalDate.now()// 获取下一天的日期val nextDayDate = currentDate.plusDays(1)// 创建固定的时间部分(00:00:00)val startTime = LocalTime.of(0, 0, 0)// 组合日期和时间来得到完整的日期时间,并格式化为字符串val currentDateTimeString = LocalDateTime.of(currentDate, startTime).format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))val nextDayDateTimeString = LocalDateTime.of(nextDayDate, startTime).format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss"))// 格式化为yyyyMMdd字符串val dateFormatter = DateTimeFormatter.ofPattern("yyyyMMdd")val currentDateString = currentDate.format(dateFormatter)// 动态创建分区范围val createPartitionSql =s"""CREATE TABLE "p$currentDateString" PARTITION OF tFOR VALUES FROM (TIMESTAMP '$currentDateTimeString') TO (TIMESTAMP '$nextDayDateTimeString') ;"""// 执行创建分区 SQLval connection = java.sql.DriverManager.getConnection(postgresUrl, connectionProperties)val statement = connection.createStatement()statement.executeUpdate(createPartitionSql)connection.close()// 将数据写入PostgreSQL分区表frame.write.mode("append").jdbc(postgresUrl, "t", connectionProperties)}
}
效果