Java进阶——数据结构与算法之哈希表与树的入门小结(四)
文章大纲
- 引言
- 一、哈希表
- 1、哈希表概述
- 2、哈希表的基本设计思想
- 3、JDK中的哈希表的设计思想概述
- 二、树
- 1、树的概述
- 2、树的特点
- 3、树的相关术语
- 4、树的存储结构
- 4.1、双亲表示法
- 4.2、孩子兄弟表示法:
- 4.3、孩子表示法:
- 4.4、双亲孩子表示法
- 三、二叉树
- 1、二叉树的性质
- 3、二叉树的类型
- 4、二叉树的存储结构
- 5、二叉树的遍历
- 5.1、先序遍历(根结点 ---> 左子树 ---> 右子树)
- 5.2、中序遍历(左子树 ---> 根结点 ---> 右子树)
- 5.3、后序遍历(左子树 ---> 右子树 ---> 根结点)
- 6、二叉树的链式实现
引言
前面介绍了线性表结构中的顺序存储结构寻址容易但是插入删除性能不好,而链式结构插入删除性能较好寻址却欠佳,那么有没有“鱼和熊掌兼可得”的结构呢?
一、哈希表
1、哈希表概述
哈希表(Hash table也叫散列表),是根据关键码值(Key value)而直接进行访问的数据结构。即它通过把关键码值映射到表中一个位置来访问记录,直接通过key来加快查找的速度,这个映射函数叫做散列函数,散列函数就是用于计算哈希值的,存放记录的数组叫做散列表。
2、哈希表的基本设计思想
以一个实例简单分析下哈希表的设计思想,首先我们有一组数据{14,19,5,7,21,1,13,0,18}需要存储,暂且设计散列表长度为预存储数组的长度,最后再设计一个映射公式即散列函数表达式f(x)= x mod 13,经过映射之后无论多大的数据都能确保经过散列函数计算之后在散列表下标范围内(当然我们用的hashCode要比这复杂得多不过核心思想是一样的)

当然以上是一种简单的哈希表基本设计思想,适用于特定的场景,比如说通讯录、QQ好友列表、微信好友列表、字典等有上限的且重复不多的数据存储。
3、JDK中的哈希表的设计思想概述
JDK中采用的是所谓的拉链法,JDK1.7之前采用的是数组+单链表的结构,而在之后改成了数组+单链表+红黑树的结构,基本思想是一致的,区别在于解决哈希冲突的方案,JDK1.7之前散列表中存储的元素上一个单链表,当发生哈希冲突时,直接把值添加到链表尾部,这样就解决了哈希冲突,但是为了避免单链表长度过长,在JDK1.8之后设置来一个阈值,当链表长度超过这个阈值时则自动转为红黑树进行存储。

二、树
1、树的概述
树是一种数据结构,它是由n(n>=1)个有限结点组成一个具有层次关系的集合。把它叫做“树”是因为它看起来像一棵倒挂的树,不过它是根朝上,而叶朝下的,当n>0时根结点是唯一的,不可能存在多个根结点,数据结构中的树只能有一个根结点;.m>0时,子树的个数没有限制,但它们一定是互不相交的。单个结点是一棵树,树根就是该结点本身。
2、树的特点
- 每个结点有零个或多个子结点;
- 没有父结点的结点称为根结点;
- 每一个非根结点有且只有一个父结点;
- 除了根结点外,每个子结点可以分为多个不相交的子树
3、树的相关术语
- 结点的度——一个结点含有的子树的个数称为该结点的度;
- 叶结点或终端结点——度为0的结点称为叶结点;
- 非终端结点或分支结点——度不为0的结点;
- 双亲结点或父结点——若一个结点含有子结点,则这个结点称为其子结点的父结点;
- 孩子结点或子结点——一个结点含有的子树的根结点称为该结点的子结点;
- 兄弟结点——具有相同父结点的结点互称为兄弟结点;
- 树的度——一棵树中,最大的结点的度称为树的度;
- 结点的层次——从根开始定义起,根为第1层,根的子结点为第2层,以此类推;
- 树的高度或深度——树中结点的最大层次;
- 堂兄弟结点——双亲在同一层的结点互为堂兄弟;
- 结点的祖先——从根到该结点所经分支上的所有结点;
- 子孙——以某结点为根的子树中任一结点都称为该结点的子孙。
- 森林——由m(m>=0)棵互不相交的树的集合称为森林;

4、树的存储结构
树的存储结构有有四种:双亲表示法、孩子兄弟表示法、孩子表示法、双亲孩子表示法
4.1、双亲表示法
把所有节点都村存在一组连续空间中,同时在每个结点中,附设一个指示器指示其双亲结点到链表中的位置。
节点结构为
| data(数据域) | parent(指针域) |
|---|---|
| 存储结点的数据信息 | 存储该结点的双亲所在数组中的下标 |
 |
根节点的指针域为-1,根据结点的parent指针很容易找到它的双亲结点。所用时间复杂度为O(1),直到parent为-1时,表示找到了树结点的根。
4.2、孩子兄弟表示法:
任意一棵树,它的结点的第一个孩子如果存在就是唯一的,它的右兄弟如果存在也是唯一的。因此我们设置两个指针,分别指向该结点的第一个孩子和此结点的右兄弟,结点结构:
| data(数据域) | firstchild(指针域) | rightsib(指针域) |
|---|---|---|
| data是数据域 | 存储该结点的第一个孩子结点的存储地址 | 存储该结点的右兄弟结点的存储地址 |
 |
4.3、孩子表示法:
把每个结点的孩子结点排列起来,以单链表作存储结构,则n个结点有n个孩子链表,如果是叶子结点则此单链表为空,然后n个头指针又组成一个线性表,采用顺序存储结构,存放进一个一维数组中。为此设计两种结点结构:一种是孩子链表的孩子结点:
| child(数据域) | next(指针域) |
|---|---|
| 存储某个结点在表头数组中的下标 | 存储指向某结点的下一个孩子结点的指针 |
| 另一种是表头数组的表头结点: | |
| data(数据域) | firstchild(头指针域) |
| — | — |
| 存储某个结点的数据信息 | 存储该结点的孩子链表的头指针 |

4.4、双亲孩子表示法

三、二叉树
二叉树是**每个结点最多有两个子树的树结构,**通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树不是树的一种特殊情形,尽管其与树有许多相似之处,但树和二叉树有两个主要差别,树中结点的最大度数没有限制,而二叉树结点的最大度数为2, 树的结点无左、右之分,而二叉树的结点有左、右之分。
1、二叉树的性质
- 在非空二叉树中,第i层的结点总数不超过2的(i-1)次方 , i>=1
- 深度为h的二叉树最多有 2的h次方减1个结点(h>=1),最少有h个结点
- 对于任意一棵二叉树,如果其叶结点数为N0,而度数为2的结点总数为N2,则N0=N2+1
- 具有n个结点的完全二叉树的深度为 [log2 N]+1 (注:[ ]表示向下取整)
- 有N个结点的完全二叉树各结点如果用顺序方式存储,则结点之间有如下关系:若I为结点编号则 如果I>1,则其父结点的编号为I/2;如果2I<=N,则其左孩子(即左子树的根结点)的编号为2I;若2I>N,则无左孩子;如果2I+1<=N,则其右孩子的结点编号为2I+1;若2I+1>N,则无右孩子。
- 给定N个节点,能构成h(N)种不同的二叉树。h(N)为卡特兰数的第N项。h(n)=C(2*n,n)/(n+1)。
- 设有i个枝点,I为所有枝点的道路长度总和,J为叶的道路长度总和J=I+2i [2]
3、二叉树的类型
- 完全二叉树——若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
- 满二叉树——除了叶结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树。
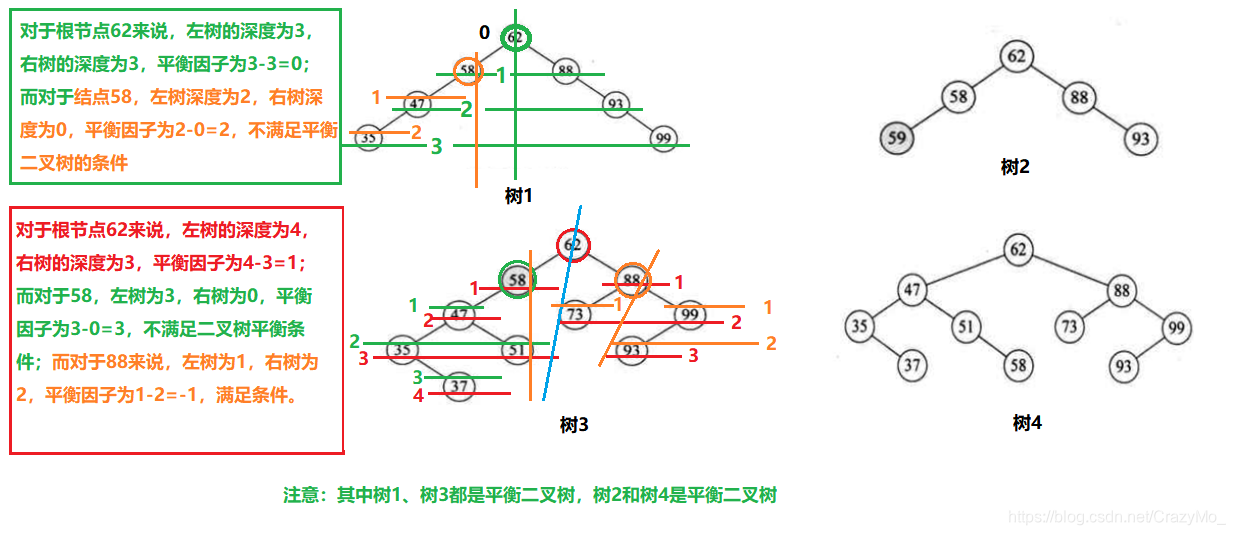
- 平衡二叉树——平衡二叉树又被称为AVL树(区别于AVL算法),它是一棵二叉排序树,且具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
4、二叉树的存储结构

5、二叉树的遍历
遍历是对树的一种最基本的运算,所谓遍历二叉树就是按一定的规则和顺序走遍二叉树的所有结点,使每一个结点都被访问一次,而且只被访问一次。由于二叉树是非线性结构,因此,树的遍历实质上是将二叉树的各个结点转换成为一个线性序列来表示。假设L、D、R分别表示遍历左子树、访问根结点和遍历右子树, 则对一棵二叉树的遍历有三种情况:DLR(称为先根次序遍历),LDR(称为中根次序遍历),LRD (称为后根次序遍历)。

5.1、先序遍历(根结点 —> 左子树 —> 右子树)
首先访问根,再先序遍历左子树,最后先序遍历右子树。
public void postOrderTraversal(TreeNode root) {if (root != null) {return;}postOrderTraversa1(root.left);postOrderTraversa1(root.right);System.out.print(root.val+" ");
}
非递归版本
public void preOrderTraversval2(TreeNode root) {LinkedList<TreeNode> stack = new LinkedList<>();TreeNode pNode = root;while (pNode != null || !stack.isEmpty()) {if (pNode != null) {System.out.print(pNode.val+" ");stack.push(pNode);pNode = pNode.left;} else { //pNode == null && !stack.isEmpty()TreeNode node = stack.pop();pNode = node.right;}}}
5.2、中序遍历(左子树 —> 根结点 —> 右子树)
首先中序遍历左子树,再访问根,最后中序遍历右子树
public void postOrderTraversal(TreeNode root) {if (root != null) {return;}postOrderTraversa1(root.left);postOrderTraversa1(root.right);System.out.print(root.val+" ");
}
5.3、后序遍历(左子树 —> 右子树 —> 根结点)
首先后序遍历左子树,再后序遍历右子树,最后访问根,即
public void postOrderTraversal(TreeNode root) {if (root != null) {return;}postOrderTraversa1(root.left);postOrderTraversa1(root.right);System.out.print(root.val+" ");
}
6、二叉树的链式实现
package com.crazymo.ndk.tree;public class BinaryTree<E> {public TreeNode<E> root;public BinaryTree(E data){root=new TreeNode<>(data,null,null);}public void createTree(){TreeNode<String> nodeB=new TreeNode<String>("B",null,null);TreeNode<String> nodeC=new TreeNode<String>("C",null,null);TreeNode<String> nodeD=new TreeNode<String>("D",null,null);TreeNode<String> nodeE=new TreeNode<String>("E",null,null);TreeNode<String> nodeF=new TreeNode<String>("F",null,null);TreeNode<String> nodeG=new TreeNode<String>("G",null,null);TreeNode<String> nodeH=new TreeNode<String>("H",null,null);TreeNode<String> nodeJ=new TreeNode<String>("J",null,null);TreeNode<String> nodeI=new TreeNode<String>("I",null,null);root.leftChild= (TreeNode<E>) nodeB;root.rightChild= (TreeNode<E>) nodeC;nodeB.leftChild=nodeD;nodeC.leftChild=nodeE;nodeC.rightChild=nodeF;nodeD.leftChild=nodeG;nodeD.rightChild=nodeH;nodeE.rightChild=nodeJ;nodeH.leftChild=nodeI;}/*** 中序访问树的所有节点*/public void midOrderTraverse(TreeNode<E> root){//逻辑if(root==null){return;}midOrderTraverse(root.leftChild);//逻辑System.out.print("mid:"+root.data+"\t");//输出midOrderTraverse(root.rightChild);//逻辑}/*** 前序访问树的所有节点 Arrays.sort();*/public void preOrderTraverse(TreeNode<E> root){if(root==null){return;}System.out.print("pre:"+root.data+"\t");preOrderTraverse(root.leftChild);preOrderTraverse(root.rightChild);}/*** 后序访问树的所有节点*/public void postOrderTraverse(TreeNode<E> root){if(root==null){return;}postOrderTraverse(root.leftChild);postOrderTraverse(root.rightChild);System.out.print("post:"+root.data+"\t");}/***节点的数据结构* @param <E>*/public class TreeNode<E> {E data;TreeNode<E> leftChild;TreeNode<E> rightChild;public TreeNode(E data, TreeNode<E> leftChild, TreeNode<E> rightChild) {this.data = data;this.leftChild = leftChild;this.rightChild = rightChild;}}
}树的遍历
BinaryTree binarayTree=new BinaryTree("A");//构造简单二叉树binarayTree.createTree();binarayTree.midOrderTraverse(binarayTree.root);System.out.println();binarayTree.preOrderTraverse(binarayTree.root);System.out.println();binarayTree.postOrderTraverse(binarayTree.root);