java面试题-阿里真题详解
前言
大家好,我是局外人一枚,最近有不少粉丝去阿里巴巴面试了,回来之后总结不少难题给我,以下是面试的真题,跟大家一起来讨论怎么回答。
阿里一面
1、说⼀下ArrayList和LinkedList区别
⾸先,他们的底层数据结构不同,ArrayList底层是基于数组实现的,LinkedList底层是基于链表实现的
由于底层数据结构不同,他们所适⽤的场景也不同,ArrayList更适合随机查找,LinkedList更适合删除和添加,查询、添加、删除的时间复杂度不同
另外ArrayList和LinkedList都实现了List接⼝,但是LinkedList还额外实现了Deque接⼝,所以LinkedList还可以当做队列来使⽤
2、说一下HashMap的Put方法
根据Key通过哈希算法与与运算得出数组下标
如果数组下标位置元素为空,则将key和value封装为Entry对象(JDK1.7中是Entry对象,JDK1.8中是Node对象)并放⼊该位置
如果数组下标位置元素不为空,则要分情况讨论
a. 如果是JDK1.7,则先判断是否需要扩容,如果要扩容就进⾏扩容,如果不⽤扩容就⽣成Entry对象,并使⽤头插法添加到当前位置的链表中
b. 如果是JDK1.8,则会先判断当前位置上的Node的类型,看是红⿊树Node,还是链表Node
i. 如果是红⿊树Node,则将key和value封装为⼀个红⿊树节点并添加到红⿊树中去,在这个过程中会判断红⿊树中是否存在当前key,如果存在则更新value
ii. 如果此位置上的Node对象是链表节点,则将key和value封装为⼀个链表Node并通过尾插法插⼊到链表的最后位置去,因为是尾插法,所以需要遍历链表,在遍历链表的过程中会判断是否存在当前key,如果存在则更新value,当遍历完链表后,将新链表Node插⼊到链表中,插⼊到链表后,会看当前链表的节点个数,如果⼤于等于8,那么则会将该链表转成红⿊树
iii. 将key和value封装为Node插⼊到链表或红⿊树中后,再判断是否需要进⾏扩容,如果需要就扩容,如果不需要就结束PUT⽅法
3、说一下ThreadLocal
1、ThreadLocal是Java中所提供的线程本地存储机制,可以利⽤该机制将数据缓存在某个线程内部,该线程可以在任意时刻、任意⽅法中获取缓存的数据。
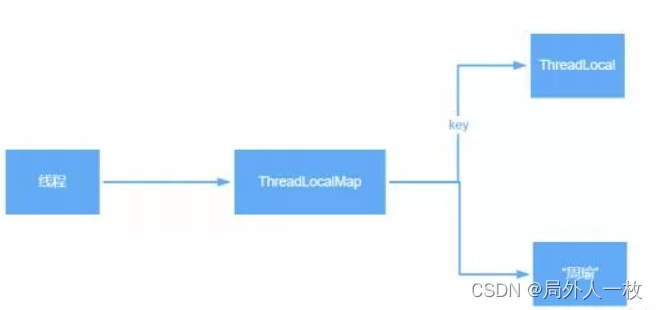
2、ThreadLocal底层是通过ThreadLocalMap来实现的,每个Thread对象(注意不是ThreadLocal对象)中都存在⼀个ThreadLocalMap,Map的key为ThreadLocal对象,Map的value为需要缓存的值
3、如果在线程池中使⽤ThreadLocal会造成内存泄漏,因为当ThreadLocal对象使⽤完之后,应该要把设置的key,value,也就是Entry对象进⾏回收,但线程池中的线程不会回收,⽽线程对象是通过强引⽤指向ThreadLocalMap,ThreadLocalMap也是通过强引⽤指向Entry对象,线程不被回收,Entry对象也就不会被回收,从⽽出现内存泄漏,解决办法是,在使⽤了ThreadLocal对象之后,⼿动调⽤ThreadLocal的remove⽅法,⼿动清楚Entry对象
4、ThreadLocal经典的应⽤场景就是连接管理(⼀个线程持有⼀个连接,该连接对象可以在不同的⽅法之间进⾏传递,线程之间不共享同⼀个连接)
5、说一下JVM中,哪些是共享区,哪些可以作为gc root你们项目
1、堆区和⽅法区是所有线程共享的,栈、本地⽅法栈、程序计数器是每个线程独有的
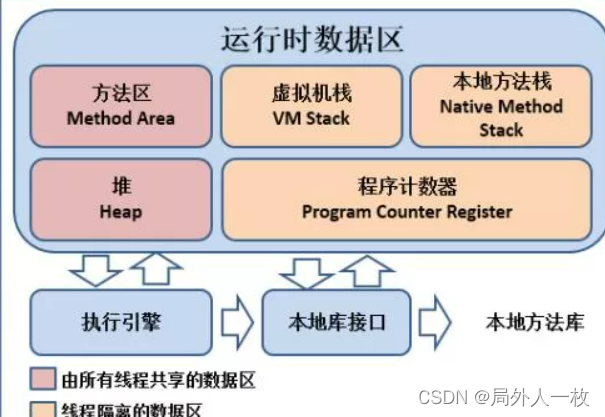
2、什么是gc root,JVM在进⾏垃圾回收时,需要找到“垃圾”对象,也就是没有被引⽤的对象,但是直接找“垃圾”对象是⽐较耗时的,所以反过来,先找“⾮垃圾”对象,也就是正常对象,那么就需要从某些“根”开始去找,根据这些“根”的引⽤路径找到正常对象,⽽这些“根”有⼀个特征,就是它只会引⽤其他对象,⽽不会被其他对象引⽤,例如:栈中的本地变量、⽅法区中的静态变量、本地⽅法栈中的变量、正在运⾏的线程等可以作为gc root。
6、你们项目如何排查JVM问题
对于还在正常运⾏的系统:
可以使⽤jmap来查看JVM中各个区域的使⽤情况
可以通过jstack来查看线程的运⾏情况,⽐如哪些线程阻塞、是否出现了死锁
可以通过jstat命令来查看垃圾回收的情况,特别是fullgc,如果发现fullgc⽐较频繁,那么就得进⾏调优了
通过各个命令的结果,或者jvisualvm等⼯具来进⾏分析
⾸先,初步猜测频繁发送fullgc的原因,如果频繁发⽣fullgc但是⼜⼀直没有出现内存溢出,那么表示fullgc实际上是回收了很多对象了,所以这些对象最好能在younggc过程中就直接回收掉,避免这些对象进⼊到⽼年代,对于这种情况,就要考虑这些存活时间不⻓的对象是不是⽐较⼤,导致年轻代放不下,直接进⼊到了⽼年代,尝试加⼤年轻代的⼤⼩,如果改完之后,fullgc减少,则证明修改有效
同时,还可以找到占⽤CPU最多的线程,定位到具体的⽅法,优化这个⽅法的执⾏,看是否能避免某些对象的创建,从⽽节省内存
对于已经发⽣了OOM的系统:
1、⼀般⽣产系统中都会设置当系统发⽣了OOM时,⽣成当时的dump⽂件
(- XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/usr/local/base)
2、我们可以利⽤jsisualvm等⼯具来分析dump⽂件
3、根据dump⽂件找到异常的实例对象,和异常的线程(占⽤CPU⾼),定位到具体的代码
4、然后再进⾏详细的分析和调试
总之,调优不是⼀蹴⽽就的,需要分析、推理、实践、总结、再分析,最终定位到具体的问题
7、如何查看线程死锁
1.可以通过jstack命令来进⾏查看,jstack命令中会显示发⽣了死锁的线程
2.或者两个线程去操作数据库时,数据库发⽣了死锁,这是可以查询数据库的死锁情况
1、查询是否锁表 show OPEN TABLES where In_use > 0;
2、查询进程 show processlist;
3、查看正在锁的事务 SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCKS;
4、查看等待锁的事务
SELECT * FROM INFORMATION_SCHEMA.INNODB_LOCK_WAITS;
8、线程之间如何进行通讯的
1、线程之间可以通过共享内存或基于⽹络来进⾏通信
2、如果是通过共享内存来进⾏通信,则需要考虑并发问题,什么时候阻塞,什么时候唤醒
3、像Java中的wait()、notify()就是阻塞和唤醒
4、通过⽹络就⽐较简单了,通过⽹络连接将通信数据发送给对⽅,当然也要考虑到并发问题,处理⽅式就是加锁等⽅式
9、介绍一下Spring,读过源码介绍一下大致流程
1、Spring是⼀个快速开发框架,Spring帮助程序员来管理对象
2、Spring的源码实现的是⾮常优秀的,设计模式的应⽤、并发安全的实现、⾯向接⼝的设计等
3、在创建Spring容器,也就是启动Spring时:
a. ⾸先会进⾏扫描,扫描得到所有的BeanDefinition对象,并存在⼀个Map中
b.然后筛选出⾮懒加载的单例BeanDefinition进⾏创建Bean,对于多例Bean不需要在启动过程中去进⾏创建,对于多例Bean会在每次获取Bean时利⽤BeanDefinition去创建
c.利⽤BeanDefinition创建Bean就是Bean的创建⽣命周期,这期间包括了合并BeanDefinition、推断构造⽅法、实例化、属性填充、初始化前、初始化、初始化后等步骤,其中AOP就是发⽣在初始化后这⼀步骤中
4、单例Bean创建完了之后,Spring会发布⼀个容器启动事件
5、Spring启动结束
6、在源码中会更复杂,⽐如源码中会提供⼀些模板⽅法,让⼦类来实现,⽐如源码中还涉及到⼀些BeanFactoryPostProcessor和BeanPostProcessor的注册,Spring的扫描就是通过BenaFactoryPostProcessor来实现的,依赖注⼊就是通过BeanPostProcessor来实现的
7、在Spring启动过程中还会去处理@Import等注解
10、说一下Spring的事务机制
1、Spring事务底层是基于数据库事务和AOP机制的
2、⾸先对于使⽤了@Transactional注解的Bean,Spring会创建⼀个代理对象作为Bean
3、当调⽤代理对象的⽅法时,会先判断该⽅法上是否加了@Transactional注解
4、如果加了,那么则利⽤事务管理器创建⼀个数据库连接
5、并且修改数据库连接的autocommit属性为false,禁⽌此连接的⾃动提交,这是实现Spring事务⾮常重要的⼀步
6、然后执⾏当前⽅法,⽅法中会执⾏sql
7、执⾏完当前⽅法后,如果没有出现异常就直接提交事务
8、如果出现了异常,并且这个异常是需要回滚的就会回滚事务,否则仍然提交事务
9、Spring事务的隔离级别对应的就是数据库的隔离级别
10、Spring事务的传播机制是Spring事务⾃⼰实现的,也是Spring事务中最复杂的
11、Spring事务的传播机制是基于数据库连接来做的,⼀个数据库连接⼀个事务,如果传播机制配置为需要新开⼀个事务,那么实际上就是先建⽴⼀个数据库连接,在此新数据库连接上执⾏sql
11、什么时候@Transactional失效
因为Spring事务是基于代理来实现的,所以某个加了@Transactional的⽅法只有是被代理对象调⽤时,那么这个注解才会⽣效,所以如果是被代理对象来调⽤这个⽅法,那么@Transactional是不会⽣效的。
同时如果某个⽅法是private的,那么@Transactional也会失效,因为底层cglib是基于⽗⼦类来实现的,⼦类是不能重载⽗类的private⽅法的,所以⽆法很好的利⽤代理,也会导致@Transactianal失效
Dubbo底层是通过RPC来完成服务和服务之间的调⽤的,Dubbo⽀持很多协议,⽐如默认的dubbo协议,⽐如http协议、⽐如rest等都是⽀持的,他们的底层所使⽤的技术是不太⼀样的,⽐如dubbo协议底层使⽤的是netty,也可以使⽤mina,http协议底层使⽤的tomcat或jetty。
服务消费者在调⽤某个服务时,会将当前所调⽤的服务接⼝信息、当前⽅法信息、执⾏⽅法所传⼊的⼊参信息等组装为⼀个Invocation对象,然后不同的协议通过不同的数据组织⽅式和传输⽅式将这个对象传送给服务提供者,提供者接收到这个对象后,找到对应的服务实现,利⽤反射执⾏对应的⽅法,得到⽅法结果后再通过⽹络响应给服务消费者。
当然,Dubbo在这个调⽤过程中还做很多其他的设计,⽐如服务容错、负载均衡、Filter机制、动态路由机制等等,让Dubbo能处理更多企业中的需求。
12、Dubbo是如何做系统交互的Dubbo的负载均衡策略
Dubbo⽬前⽀持:
1、平衡加权轮询算法
2、加权随机算法
3、⼀致性哈希算法
4、最⼩活跃数算法
13、还读过哪些框架源码介绍一下你还熟悉的
这个问题⽐较⼴泛,你即可以说:HashMap、线程池等JDK⾃带的源码,也可以说Mybatis、Spring Boot、Spring Cloud、消息队列等开发框架或中间件的源码