Java类集框架(二)
目录
1.Map(常用子类 HashMap,LinkedHashMap,HashTable,TreeMap)
2.Map的输出(Map.Entry,iterator,foreach)
3.数据结构 - 栈(Stack)
4.数据结构 - 队列(Queue)
5.属性类Properties
5.Collections工具类
1.Map(常用子类 HashMap,LinkedHashMap,HashTable,TreeMap)
Map最大的特点就是二元偶对象(存储的结构是 key = value),比如说存放的可以是学生+成绩,如:黄小龙 = 60 。并且Map与Collection集合在操作上的不同是,Map中文是地图,最大的作用是用以查找数据,而Collection最主要用以输出数据
| 方法 | 描述 |
|---|---|
| public void put(K key, V value) | 将指定的键值对添加到Map中 |
| public V get(Object key) | 返回与指定键关联的值 |
| public Set<Map.Entry<K, V>> entrySet() | 返回Map中包含的所有键值对的Set集合 |
| public V remove(Object key) | 从Map中移除指定键及其关联的值 |
| public boolean containsKey(Object key) | 如果Map中包含指定键,则返回true;否则返回false |
1.HashMap(散列Map)子类
案例代码HashMap的创建:
package Example1813;import java.util.HashMap;
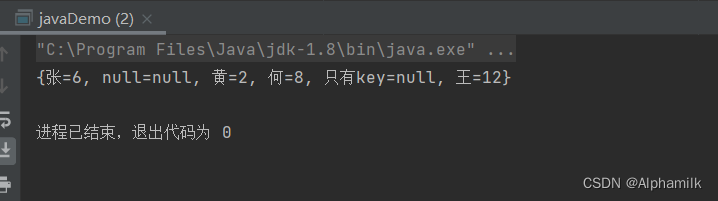
import java.util.Map;public class javaDemo {public static void main(String[] args) {Map<String,Integer> map = new HashMap<String,Integer>();map.put("王",12);map.put("张",6);map.put("黄",2);map.put("何",8);
// 输入存在null的数据map.put("只有key",null);map.put(null,2);map.put(null,null);System.out.println(map);}
}
- 由于是Hash散列,所以存储的数据是混乱无序的,如果按照顺序输入数据可能会被打乱,所以为了解决这个问题如同Set的HashSet一样引入了LinkedHashMap
- HashMap允许放入的数据存在空值(NULL)
2.LinkedHashMap子类
有序型Map,通过放入的顺序保证输出的顺序
案例代码:成绩查询系统
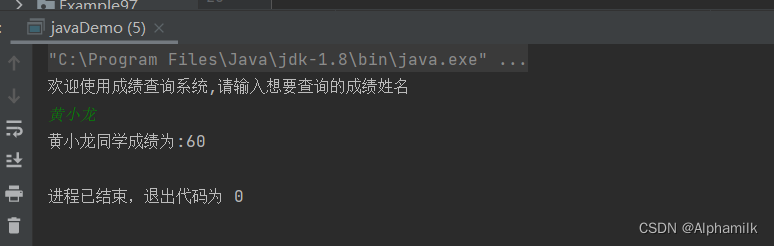
package Ecample1814;import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Scanner;public class javaDemo {public static void main(String[] args) {Map<String,Integer> map = new LinkedHashMap<>();map.put("黄小龙",60);map.put("张春蛋",62);map.put("王二",73);map.put("王包",77);map.put("陈色",78);System.out.println("欢迎使用成绩查询系统,请输入想要查询的成绩姓名");Scanner scan = new Scanner(System.in);String temp = scan.next();if (map.containsKey(temp)){System.out.println(temp+"同学成绩为:"+ map.get(temp));}else System.out.println("无查询对象");}
}
3.HashTable子类
HashTable,也是无序的存放,但是其中不能存放空值否则会报错
案例代码:
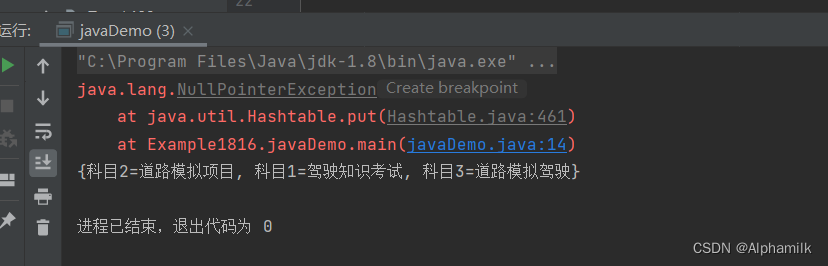
package Example1816;import java.util.Hashtable;
import java.util.Map;public class javaDemo {public static void main(String[] args) {Map<String,String> hashtable= new Hashtable<>();hashtable.put("科目1","驾驶知识考试");hashtable.put("科目2","道路模拟项目");hashtable.put("科目3","道路模拟驾驶");try {
// 放入空值hashtable.put(null,null);}catch (Exception e){
// 提示异常e.printStackTrace();}System.out.println(hashtable);}
}
HashTable与HashMap的区别
HashTable属于同步操作(线程安全),并且其中的key和value不允许存放null,否则会抛出异常NullPointerException
HashMap属于异步操作(非线程安全),其中的key或者value可以存放null
4.TreeMap 子类
TreeMap的子类属于是有序的集合类型,它可以根据key进行排序,所以再key一定要有实现Comparable的接口的才能进行排序
String类就实现了Comparable接口
案例代码:按照运动员号数输出所有运动员的比赛时间
package Example1817;import java.util.Hashtable;
import java.util.Map;
import java.util.TreeMap;public class javaDemo {public static void main(String[] args) {Map<String,String> map = new TreeMap<>();map.put("运动员2号","6.32秒");map.put("运动员1号","6.54秒");map.put("运动员4号","6.72秒");map.put("运动员3号","7.02秒");System.out.println(map);}
}

2.Map的输出(Map.Entry与iterator,foreach)
虽然Map主要用于数据的查找,但是有些时候也是需要其中数据的输出。但是在Map的方法中可以发现并不像Collection一样有iterator方法,所以目标放在方法转换方法entrySet(),先将数据转为Set集合类型再通过iterator迭代器进行输出,这就是Map的标准输出
首先介绍Map.Entry内部接口
由于Map中所有保存的对象都是二元偶对象,所以针对此对象的数据标准建立了一个Map.Entry内部接口,该接口可以接收二元偶对象并存在两个方法,getkey()与getvalue();分别获取一个对象的key与value
通过Map.Entry搭配Iterator实现Map的输出案例:
package Example1818;import java.util.Hashtable;
import java.util.Iterator;
import java.util.Map;
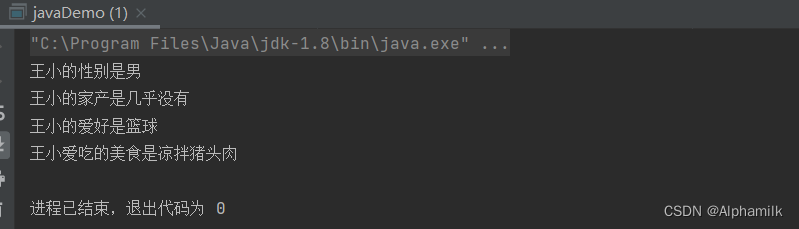
import java.util.Set;public class javaDemo {public static void main(String[] args) {Map<String, String> map = new Hashtable<>();map.put("王小的爱好", "篮球");map.put("王小爱吃的美食", "凉拌猪头肉");map.put("王小的性别", "男");map.put("王小的家产", "几乎没有");
// map转为集合SetSet<Map.Entry<String, String>> entrySet = map.entrySet();
// 调用集合Set的iterator方法Iterator<Map.Entry<String, String>> entryIterator = entrySet.iterator();while (entryIterator.hasNext()) {Map.Entry<String,String> temp =entryIterator.next();System.out.println(temp.getKey()+"是"+temp.getValue());}}
}
问1:为什么迭代器的泛型是Iterator<Map.Entry<String,String>>而不是Iterator<String,String>
迭代器的泛型类型应为
Iterator<Map.Entry<String, String>>而不是Iterator<String, String>,因为在遍历Map键值对时,每个键值对都表示一个Map.Entry对象。在Java中,
Map接口的键值对由Map.Entry表示,其在内部定义了两个相关的方法:getKey()和getValue()。因此,当使用迭代器来遍历Map时,需要使用Map.Entry作为泛型参数,并且迭代器的类型应该是Iterator<Map.Entry<String, String>>。通过这种方式,迭代器可以迭代返回
Map.Entry对象(包含键和值),然后可以使用getKey()和getValue()方法分别获取键和值。
3.数据结构 - 栈(Stack)
栈作为一种数据结构其最主要的特点就是"先进后出"
举个最简单例子理解,在古代如果一个人有大量的钱财需要自己存放,那么他可能会挖一个坑,这个坑就理解为栈,首先他先放财物在坑底,然后放石头块,最后放沙子。那有一天他要用到财务的时候,就需要按挖沙子,挖石头块,得到财物的流程,这里可以发现最开始放的财物反而最后才能得到,这就是先进后出
Stack常用的方法:
| 修饰符 | 返回值类型 | 方法名 | 描述 |
|---|---|---|---|
public | void | push() | 将元素推入栈顶。 |
public | E | pop() | 移除并返回栈顶元素。 |
public | E | peek() | 返回栈顶元素但不移除。 |
public | int | search() | 返回元素在栈中的位置,如果不存在则返回 -1。 |
public | boolean | empty() | 检查栈是否为空,为空则返回 true,否则返回 false。 |
案例Stack的创建以及操作方法:
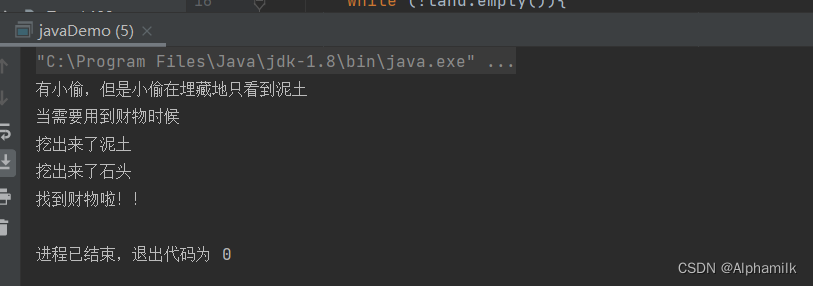
package Example1819;import java.util.Stack;public class javaDemo {public static void main(String[] args) {Stack<String> land = new Stack<>();
// 埋藏财物land.push("财物");land.push("石头");land.push("泥土");System.out.println("有小偷,但是小偷在埋藏地只看到"+land.peek());System.out.println("当需要用到财物时候");
// 开始挖财物while (!land.empty()){String temp;temp = land.pop();if (temp.equals("财物")){System.out.println("找到财物啦!!");}else System.out.println("挖出来了"+temp);}}
}
4.数据结构 - 队列(Queue,Deque)
队列作为一种数据结构其最主要的特点就是“先进先出”
就跟名字的队列一样,就像抢票一样,先到先得
由于在jdk1.6以后为了方便队列的操作将Queue定义为了Deque,此次的变更扩充了许多的方法,以下是Deque的常用方法
| 修饰符 | 返回值类型 | 方法名 | 描述 |
|---|---|---|---|
boolean | void | addFirst(E e) | 将指定元素插入到双端队列的开头位置,如果成功则返回 true,如果队列已满则抛出异常。 |
boolean | void | addLast(E e) | 将指定元素插入到双端队列的末尾位置,如果成功则返回 true,如果队列已满则抛出异常。 |
boolean | boolean | offerFirst(E e) | 将指定元素插入到双端队列的开头位置,如果成功则返回 true,如果队列已满则返回 false。 |
boolean | boolean | offerLast(E e) | 将指定元素插入到双端队列的末尾位置,如果成功则返回 true,如果队列已满则返回 false。 |
E | E | removeFirst() | 移除并返回双端队列的开头元素,如果队列为空则抛出异常。 |
E | E | removeLast() | 移除并返回双端队列的末尾元素,如果队列为空则抛出异常。 |
E | E | pollFirst() | 移除并返回双端队列的开头元素,如果队列为空则返回 null。 |
E | E | pollLast() | 移除并返回双端队列的末尾元素,如果队列为空则返回 null。 |
E | E | peekFirst() | 返回双端队列的开头元素但不移除,如果队列为空则返回 null。 |
E | E | peekLast() | 返回双端队列的末尾元素但不移除,如果队列为空则返回 null。 |
案例代码:
package Example1820;import java.util.Deque;
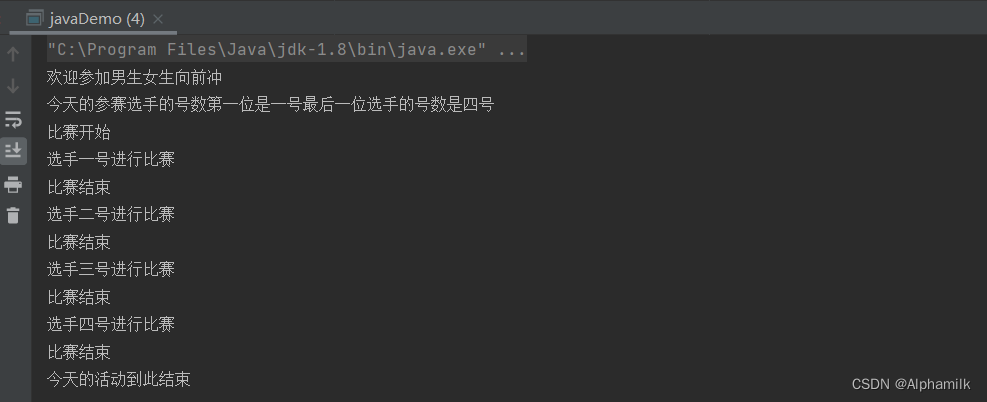
import java.util.LinkedList;public class javaDemo {public static void main(String[] args) {
// 通过链表接收对象Deque<String> deque = new LinkedList<>();System.out.println("欢迎参加男生女生向前冲");
// 从队尾进行插入,每一位到前一位的后面deque.addLast("一号");deque.addLast("二号");deque.addLast("三号");deque.addLast("四号");System.out.println("今天的参赛选手的号数第一位是"+deque.peekFirst()+"最后一位选手的号数是"+ deque.peekLast());System.out.println("比赛开始");while (!deque.isEmpty()){System.out.println("选手"+deque.pollFirst()+"进行比赛");System.out.println("比赛结束");}System.out.println("今天的活动到此结束");}
}
5.属性类Properties
属性类是专门用以处理字符串的一个类并且是HashTable的子类,但是注意只能对字符串进行操作,同时可以通过输入/输出流进行数据的保存
以下是属性类的常用方法:
| getProperties(String key) | 返回指定键对应的属性值。 |
| getProperties(String key, defaultValue) | 返回指定键对应的属性值,如果键不存在则返回默认值。 |
| setProperties(Properties props) | 将指定的属性集合设置为当前属性集合。 |
| store(OutputStream out, String comments) | 将当前属性集合保存到输出流中。 |
| load(InputStream in) | 从输入流中加载属性集合。 |
设置属性的案例:
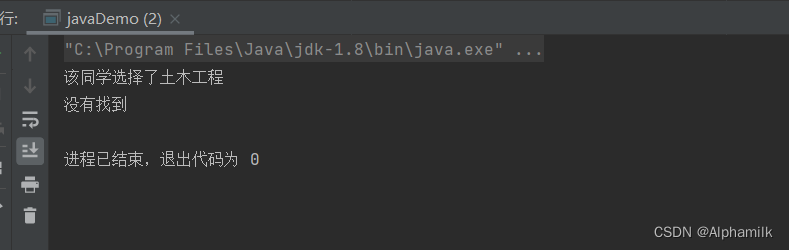
package Example1821;import java.util.Properties;public class javaDemo {public static void main(String[] args) {Properties properties = new Properties();
// 创建属性properties.setProperty("属性的key","属性的value");properties.setProperty("黄小龙","土木工程");properties.setProperty("张小芳","计算机科学技术");properties.setProperty("王洪","道桥设计");properties.setProperty("黄键化","石油开采");
// 获取属性System.out.println("该同学选择了"+properties.getProperty("黄小龙"));System.out.println(properties.getProperty("王孟","没有找到"));}
}
2.通过输入输出流进行文件保存
package Example1822;import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.util.Properties;public class javaDemo {public static void main(String[] args)throws Exception {File file = new File("E:"+File.separator+"jiawa"+File.separator+"information.properties");Properties properties = new Properties();
// 填入信息properties.setProperty("www.baidu.com","78");properties.setProperty("www.csdn.com","80");properties.setProperty("www.4399.com","90");properties.setProperty("ww.7k7k","68");
// 通过输出流将信息输出到对应文件中if (file.exists()){properties.store(new FileOutputStream(file),"website and it gets scores");}
// 通过输入流得到信息Properties inproperty = new Properties();inproperty.load(new FileInputStream(file));System.out.println(inproperty.get("www.4399.com"));}
}

5.Collections工具类
该工具类是专门提供的一个集合的工具类,该工具类实现Collection,Map,List,Set等集合接口的数据操作
下面是Collections工具类的常用方法:
| 方法 | 描述 |
|---|---|
addAll(Collection<? super T> c, T... elements) | 将元素数组添加到集合 c 中 |
binarySearch(List<? extends T> list, T key) | 使用二分查找算法在有序列表 list 中查找元素 key 的索引 |
copy(List<? super T> dest, List<? extends T> src) | 将源列表 src 的元素复制到目标列表 dest |
fill(List<? super T> list, T obj) | 使用指定的对象 obj 填充列表 list |
max(Collection<? extends T> coll) | 返回集合 coll 的最大元素 |
min(Collection<? extends T> coll) | 返回集合 coll 的最小元素 |
reverse(List<?> list) | 反转列表 list 中的元素 |
shuffle(List<?> list) | 随机打乱列表 list 中的元素 |
sort(List<T> list) | 对列表 list 进行升序排序 |
swap(List<?> list, int i, int j) | 交换列表 list 中索引为 i 和 j 的元素 |
案例:通过Collections类操作List集合
package Example1823;import java.util.ArrayList;
import java.util.Collections;
import java.util.List;public class javaDemo {public static void main(String[] args) {List<String> list = new ArrayList<String>();
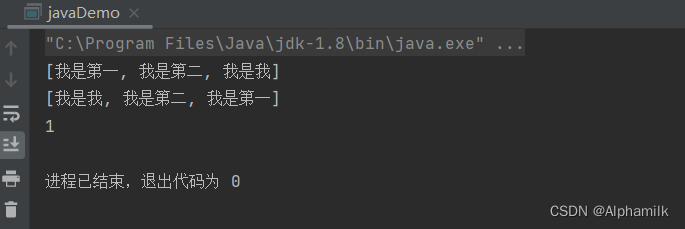
// 批量添加信息Collections.addAll(list,"我是第一","我是第二","我是我");System.out.println(list);
// 集合内容反转Collections.reverse(list);System.out.println(list);
// 通过二分法查找System.out.println(Collections.binarySearch(list,"我是第二"));}
}