A Generalized Loss Function for Crowd Counting and Localization阅读笔记
简单来说,就是用了UOT来解决人群计数问题
代码:https://github.com/jia-wan/GeneralizedLoss-Counting-Pytorch.git
我改了一点的:https://github.com/Nightmare4214/GeneralizedLoss-Counting-Pytorch.git
loss
设density map为 A = { ( a i , x i ) } i = 1 n \mathcal{A} =\left\{\left(a_i, \mathbf{x}_i\right)\right\}_{i=1}^{n} A={(ai,xi)}i=1n
其中 a i a_i ai为预测density, x i ∈ R n \mathbf{x}_i\in\mathbb{R}^n xi∈Rn为坐标, n n n为像素个数
令 a = [ a i ] i \mathbf{a} = \left[a_i\right]_i a=[ai]i,也就是density map转成列向量
真实点图为 B = { ( b j , y j ) } j = 1 m \mathcal{B}=\left\{\left(b_j,\mathbb{y}_j\right)\right\}_{j=1}^m B={(bj,yj)}j=1m
其中 y j \mathbf{y}_j yj为坐标, m m m为标注点个数, b j b_j bj为这个点代表的人群数量
这个论文假设 b = [ b j ] j = 1 m \mathbf{b}=\left[b_j\right]_j = \mathbf{1}_m b=[bj]j=1m,也就是说每个点只有一个人
熵正则化的UOT为
L C τ ( A , B ) = min P ∈ R + n × m ⟨ C , P ⟩ − ϵ H ( P ) + τ D 1 ( P 1 m ∣ a ) + τ D 2 ( P T 1 n ∣ b ) \mathcal{L}_{\mathbf{C}}^{\tau}\left(\mathcal{A},\mathcal{B}\right) = \min_{\mathbf{P}\in\mathbb{R}_+^{n\times m}} \left\langle \mathbf{C},\mathbf{P}\right\rangle -\epsilon H\left(\mathbf{P}\right) + \tau D_1\left(\mathbf{P}\mathbf{1}_m|\mathbf{a}\right) +\tau D_2\left(\mathbf{P}^T\mathbf{1}_n|\mathbf{b}\right) LCτ(A,B)=P∈R+n×mmin⟨C,P⟩−ϵH(P)+τD1(P1m∣a)+τD2(PT1n∣b)
其中 C ∈ R + n × m \mathbf{C}\in\mathbb{R}_+^{n\times m} C∈R+n×m是传输代价矩阵, C i , j C_{i,j} Ci,j为将density从 x i \mathbf{x}_i xi搬运到 y j \mathbf{y}_j yj的距离
P \mathbf{P} P为传输矩阵
令 a ^ = P 1 m , b ^ = P T 1 n \hat{\mathbf{a}} = \mathbf{P}\mathbf{1}_m, \hat{\mathbf{b}}=\mathbf{P}^T\mathbf{1}_n a^=P1m,b^=PT1n
这个loss有4个部分
第一部分是传输的loss,目的是将预测的density map往真实标注靠
第二部分是熵 H ( P ) = − ∑ i , j P i , j log P i , j H\left(\mathbf{P}\right) = -\sum_{i,j}P_{i,j}\log P_{i,j} H(P)=−∑i,jPi,jlogPi,j是熵正则化项,用来控制稀疏程度,越大越稀疏(会趋于均匀分布),反之亦然
第三部分就是希望 a ^ \hat{\mathbf{a}} a^靠近 a \mathbf{a} a
第四部分就是希望 b ^ \hat{\mathbf{b}} b^靠近 b \mathbf{b} b
论文里, D 1 D_1 D1取 L 2 L_2 L2的平方
D 2 D_2 D2取 L 1 L_1 L1
代价矩阵
C i , j = e 1 η ( x i , y j ) ∥ x i − y j ∥ 2 C_{i,j} = e^{\frac{1}{\eta\left(x_i,y_j\right)}\|\mathbf{x}_i-\mathbf{y}_j\|_2} Ci,j=eη(xi,yj)1∥xi−yj∥2
这里的 x i , y j \mathbf{x}_i,\mathbf{y}_j xi,yj是经过归一化的
不过要注意,代码里这个 η ( x i , y j ) \eta\left(x_i,y_j\right) η(xi,yj)是常数,默认是 0.6 0.6 0.6
求解
采用的是sinkhorn
P = diag ( u ) K diag ( v ) , K = exp ( − C / ε ) \mathbf{P}=\operatorname{diag}(\mathbf{u}) \mathbf{K} \operatorname{diag}(\mathbf{v}), \quad \mathbf{K}=\exp (-\mathbf{C} / \varepsilon) P=diag(u)Kdiag(v),K=exp(−C/ε)
这里近似 D 1 , D 2 D_1,D_2 D1,D2为KL散度,这样的话有高效的解法
u ( ℓ + 1 ) = ( a K v ( ℓ ) ) τ τ + ϵ , v ( ℓ + 1 ) = ( b K ⊤ u ( ℓ + 1 ) ) τ τ + ϵ \mathbf{u}^{(\ell+1)}=\left(\frac{\boldsymbol{a}}{\mathbf{K} \mathbf{v}^{(\ell)}}\right)^{\frac{\tau}{\tau+\epsilon}}, \quad \mathbf{v}^{(\ell+1)}=\left(\frac{\boldsymbol{b}}{\mathbf{K}^{\top} \mathbf{u}^{(\ell+1)}}\right)^{\frac{\tau}{\tau+\epsilon}} u(ℓ+1)=(Kv(ℓ)a)τ+ϵτ,v(ℓ+1)=(K⊤u(ℓ+1)b)τ+ϵτ
(其实即使是 K L KL KL散度,他代码似乎也不能这么写)
代码
数据集
预处理
用的是UCF-QNRF
预处理:
1.让 h , w h,w h,w中较小的那个,处于 [ 512 , 2048 ] \left[512,2048\right] [512,2048]的范围,另一个按照缩放比例调整
2.过滤不在图片中的点
3.额外计算每个点到其他点的一个距离,具体地
P = ( p 1 T p 2 T ⋮ p m T ) , p i ∈ R 2 \mathbf{P} = \begin{pmatrix} \mathbf{p}_1^T\\ \mathbf{p}_2^T\\ \vdots\\ \mathbf{p}_m^T \end{pmatrix},\quad \mathbf{p}_i\in\mathbb{R}^2 P= p1Tp2T⋮pmT ,pi∈R2
d i s = [ ∥ p i − p j ∥ ] i , j \mathbf{dis} = \left[\|\mathbf{p}_i-\mathbf{p}_j\|\right]_{i,j} dis=[∥pi−pj∥]i,j
最后对每一行进行快排的那个选择哨兵的过程,找到第3个(从0开始数)
对第 1 , 2 , 3 1,2,3 1,2,3个元素取平均(从0开始数)
def find_dis(point):a = point[:, None, :]b = point[None, ...]dis = np.linalg.norm(a - b, ord=2, axis=-1) # dis_{i,j} = ||p_i - p_j||# mean(4th_min, 2 of the [1st_min, 2nd_min, 3rd_min])dis = np.mean(np.partition(dis, 3, axis=1)[:, 1:4], axis=1, keepdims=True)return dis
因此得到的标签为
P = [ ( x i , y i , d i s i ) ] i ∈ R m × 3 \mathbf{P}=\left[\left(x_i,y_i,dis_i\right)\right]_i\in\mathbb{R}^{m\times 3} P=[(xi,yi,disi)]i∈Rm×3
读取数据
随机裁剪图片,到 ( 512 , 512 ) \left(512,512\right) (512,512)
设 i , j i,j i,j为裁剪的左上角坐标, h = w = 512 h=w=512 h=w=512
接着读取标签
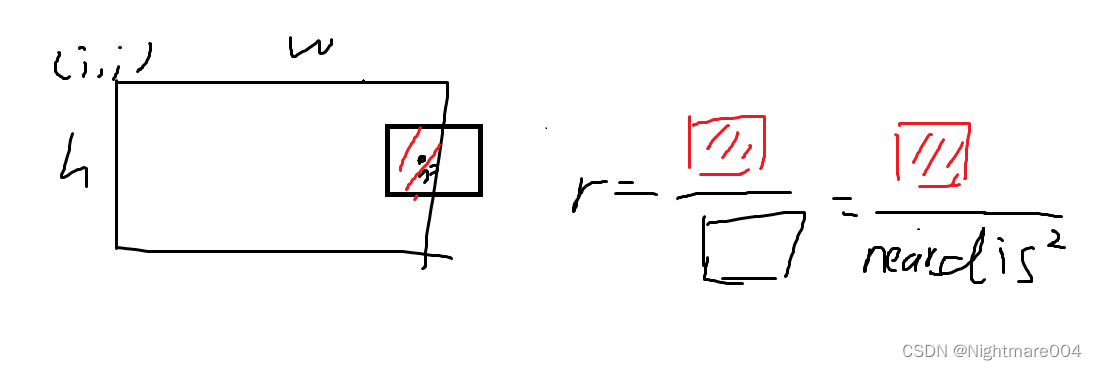
根据 d i s dis dis来设定一个小矩形
计算这个矩形在裁剪范围的面积,和矩形面积的 1 4 \frac{1}{4} 41
如果这个比例大于0.3,就选择这个点,否则舍弃
然后其他的就是随机水平翻转
模型
vgg19+上采样+两层卷积+abs
训练
注意这里sinkhorn是有 ϵ − scaling heuristic \epsilon-\text{scaling heuristic} ϵ−scaling heuristic的这样可以做到20轮以内收敛
为了数值稳定,还用了 log-domain \text{log-domain} log-domain
结果
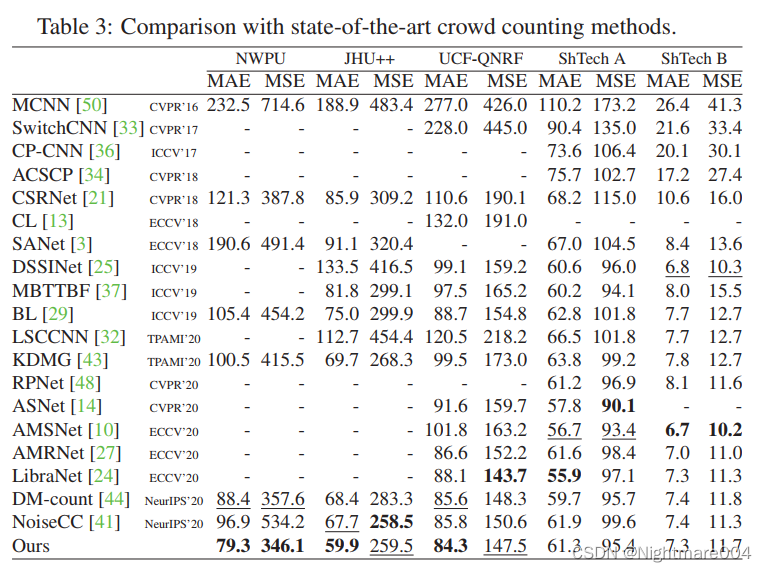
作者的提供的模型的结果:mae 85.09911092883813, mse 150.88815648865386
我在UCF-QNRF跑的结果:mae:85.69232401590861, mse:155.30853159819492