ceph集群中RBD的性能测试、性能调优
文章目录
- rados bench
- rbd bench-write
- 测试工具Fio
- 测试ceph rbd块设备的iops性能
- 测试ceph rbd块设备的带宽
- 测试ceph rbd块设备的延迟
- 性能调优
rados bench
参考:https://blog.csdn.net/Micha_Lu/article/details/126490260
rados bench为ceph自带的基准测试工具,rados bench用于测试rados存储池底层性能,该工具可以测试写、顺序读、随机读三种类型.
写入速率测试:
rados bench -p rbd-bak 10 write --no-cleanup
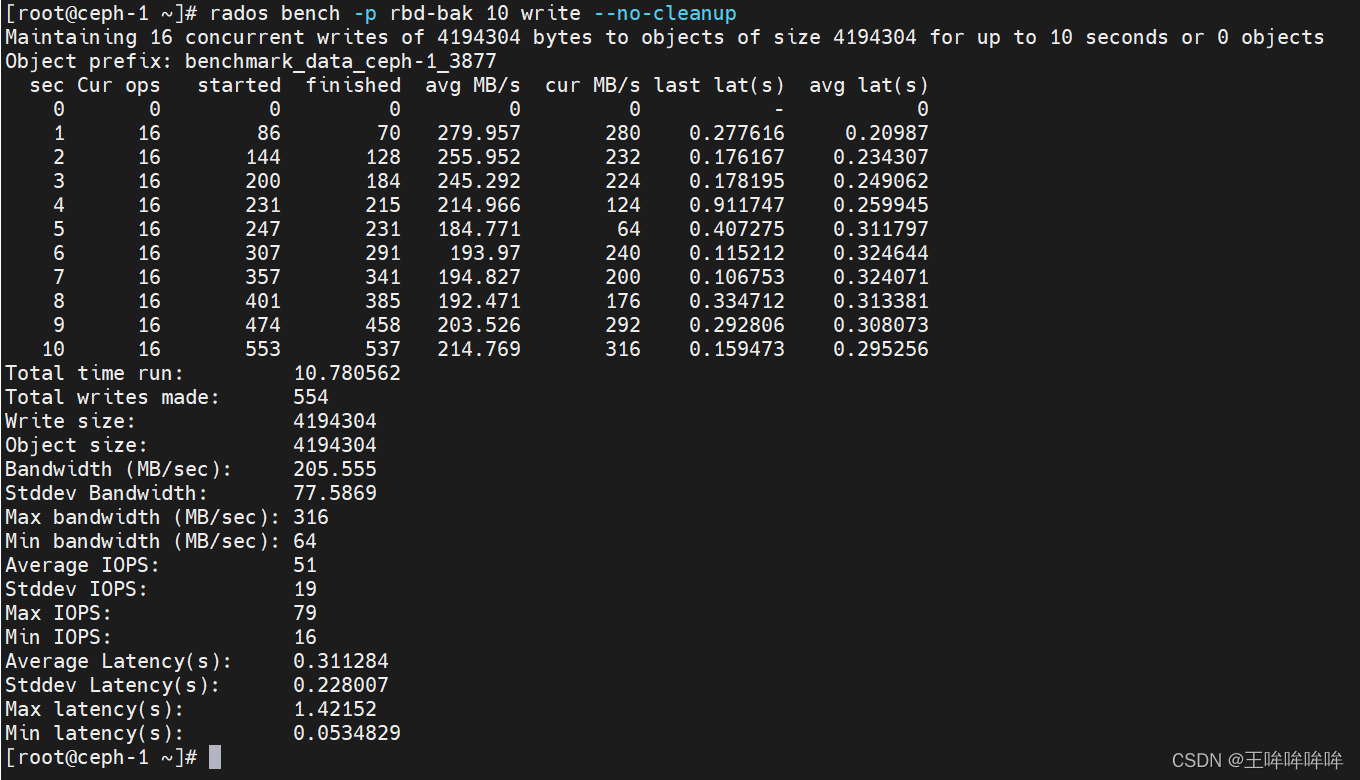
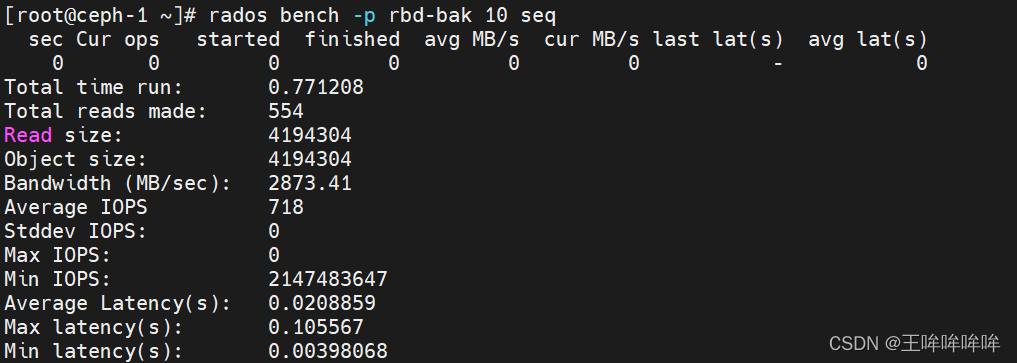
顺序读速率测试:
rados bench -p rbd-bak 10 seq
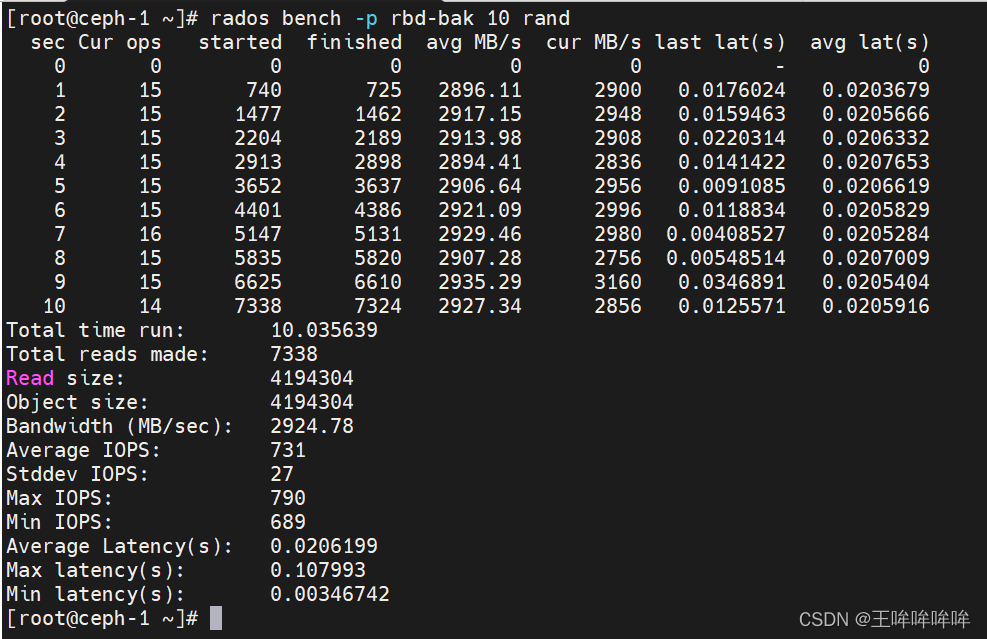
随机读速率测试:
rados bench -p rbd-bak 10 rand
rbd bench-write
rbd bench-write为ceph自带的基准性能测试工具,rbd bench-write用于测试块设备的简单写入测试。
rbd bench-write rbd-bak/image1 --io-size 1M --io-pattern seq --io-threads 32 --io-total 10G
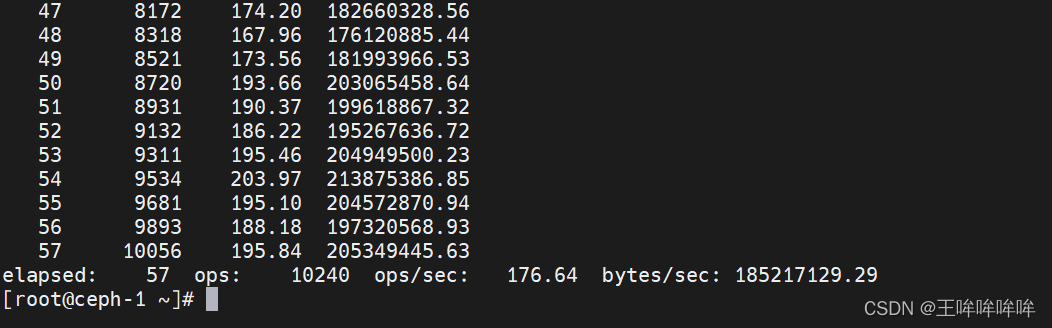
测试结果取最后一行elapsed的值,带宽为bytes/sec对应参数值(单位为bytes/sec,可根据需要转换为MB/s),IOPS为ops/sec对应参数值
测试工具Fio
yum install fio -y
测试ceph rbd块设备的iops性能
关于fio命令的参数,参考:https://blog.csdn.net/zhiboqingyun/article/details/123368887
每秒的输入输出量(或读写次数),是衡量磁盘性能的主要指标之一;
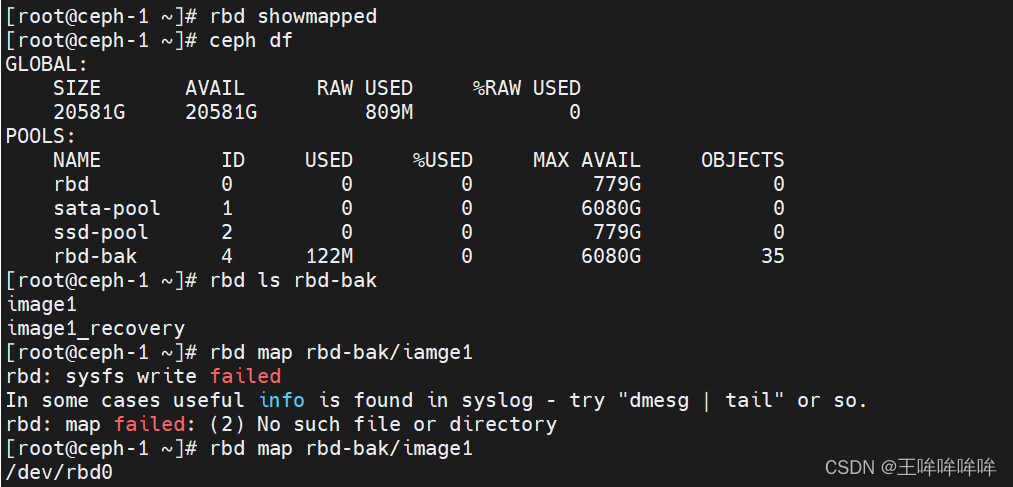
测试随机写4kb文件的iops性能
fio --name=4krandwrite_iops --filename=/dev/rbd0 --numjobs=8 --bs=4k --ioengine=libaio --direct=1 --randrepeat=0 --norandommap --rw=randwrite --group_reporting --iodepth=512 --iodepth_batch=128 --iodepth_batch_complete=128 --gtod_reduce=1 --runtime=10
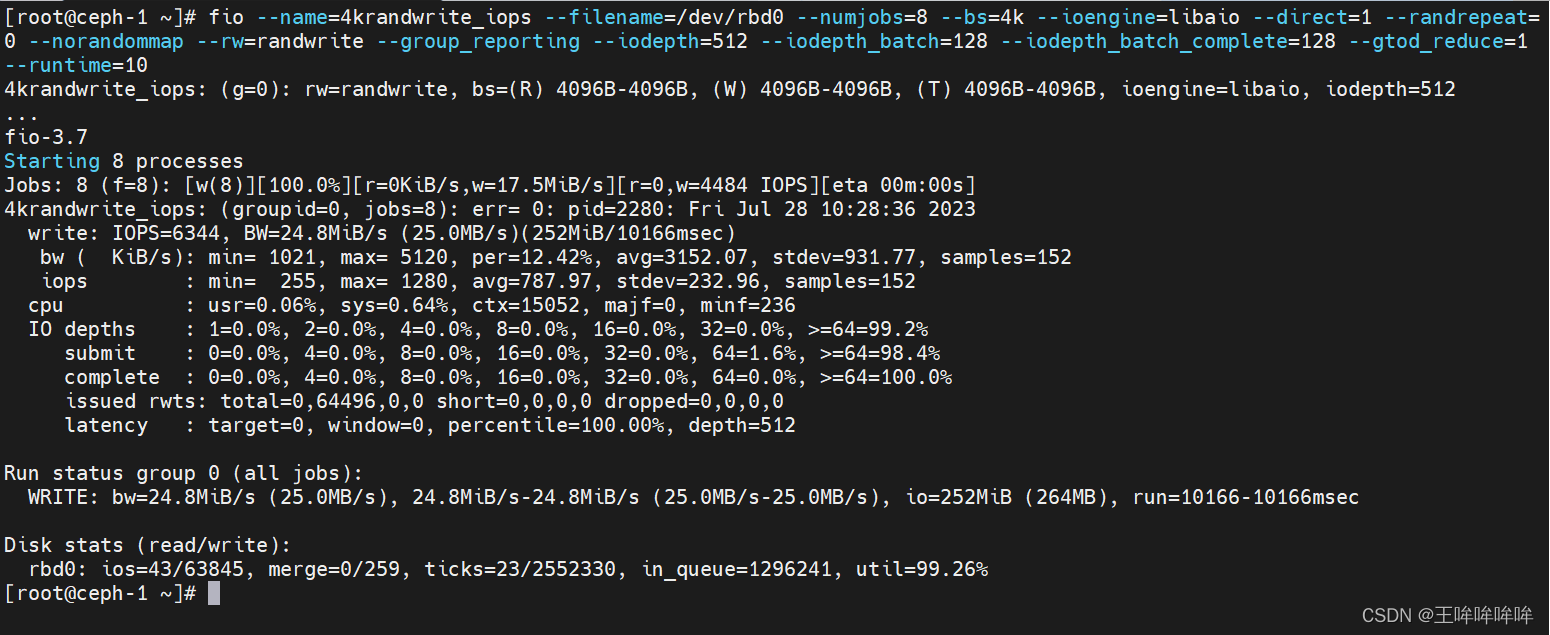
顺序写4kb文件的iops性能
fio --name=4kwrite_iops --filename=/dev/rbd0 --numjobs=8 --bs=4k --ioengine=libaio --direct=1 --randrepeat=0 --norandommap --rw=write --group_reporting --iodepth=512 --iodepth_batch=128 --iodepth_batch_complete=128 --gtod_reduce=1 --runtime=10
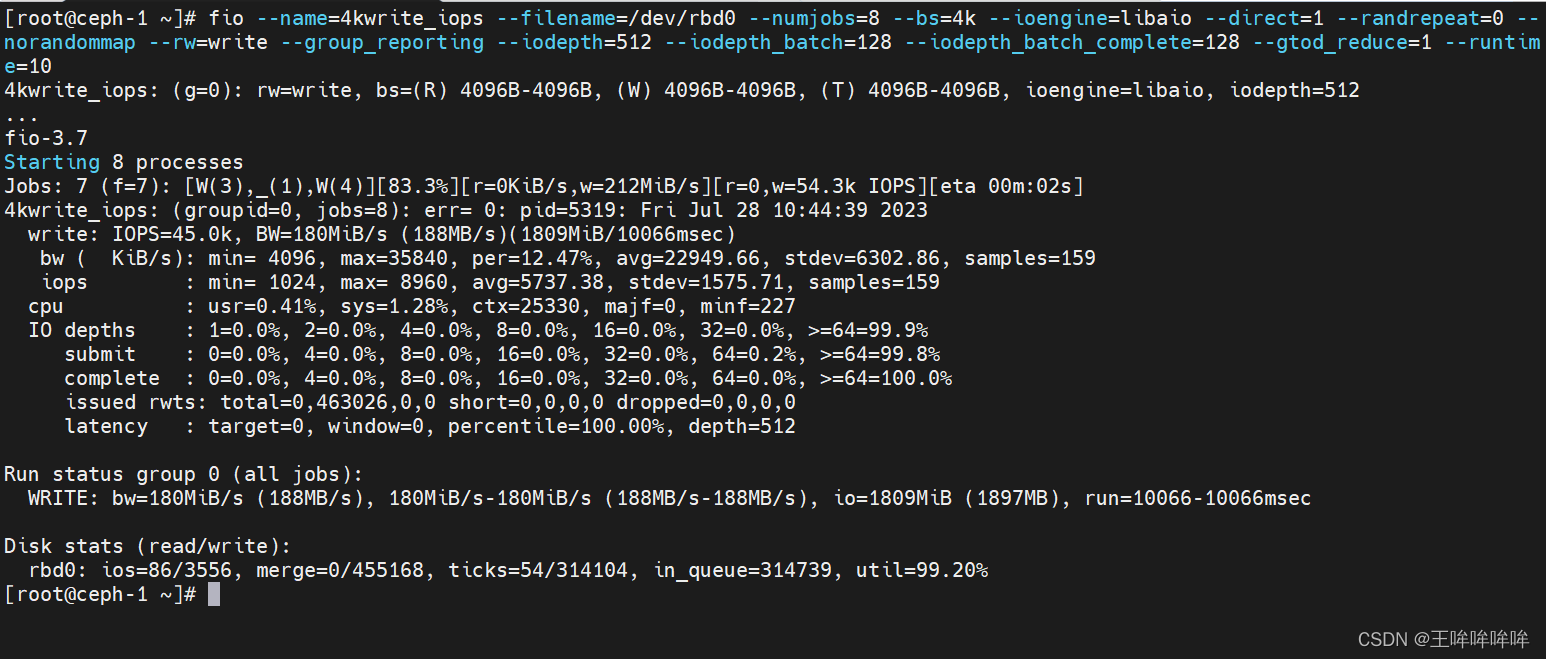
顺序读4kb文件的iops性能
fio --name=4kread_iops --filename=/dev/rbd0 --numjobs=8 --bs=4k --ioengine=libaio --direct=1 --randrepeat=0 --norandommap --rw=read --group_reporting --iodepth=512 --iodepth_batch=128 --iodepth_batch_complete=128 --gtod_reduce=1 --runtime=10
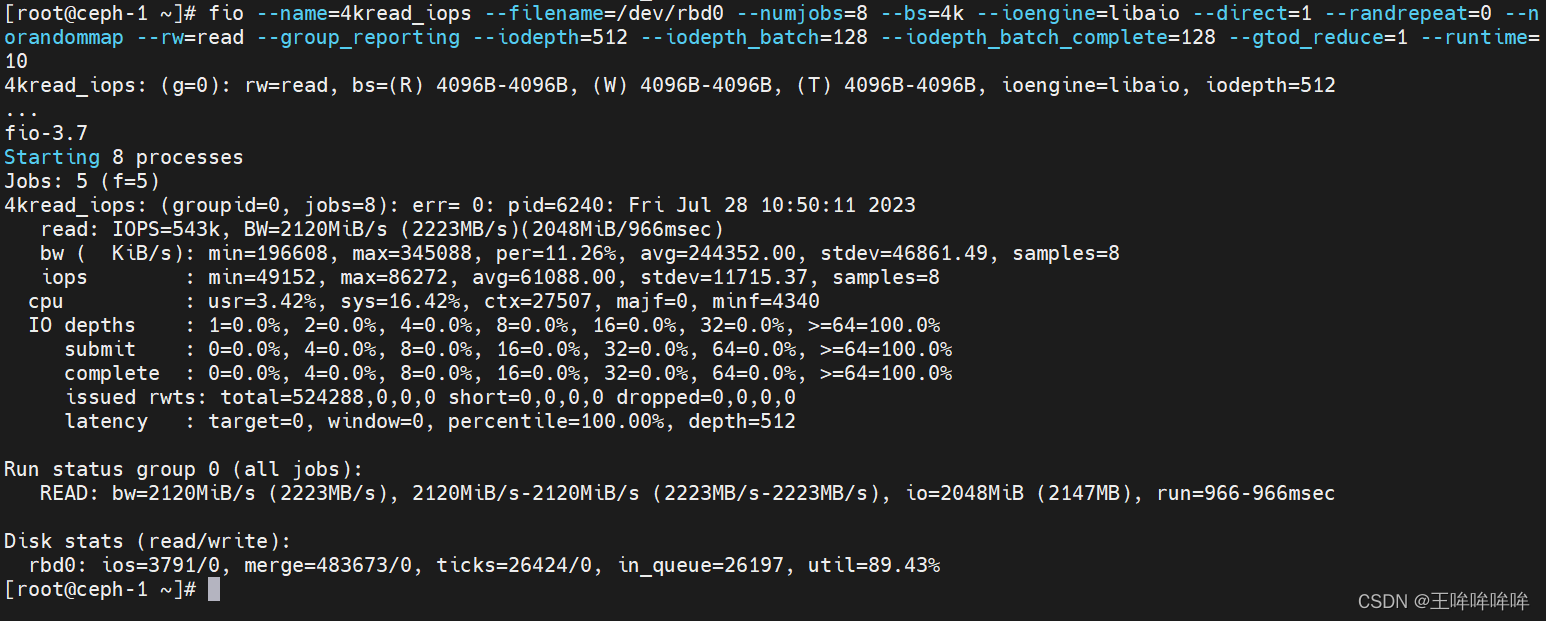
随机读4kb文件的iops性能
fio --name=4krandread_iops --filename=/dev/rbd0 --numjobs=8 --bs=4k --ioengine=libaio --direct=1 --randrepeat=0 --norandommap --rw=randread --group_reporting --iodepth=512 --iodepth_batch=128 --iodepth_batch_complete=128 --gtod_reduce=1 --runtime=10
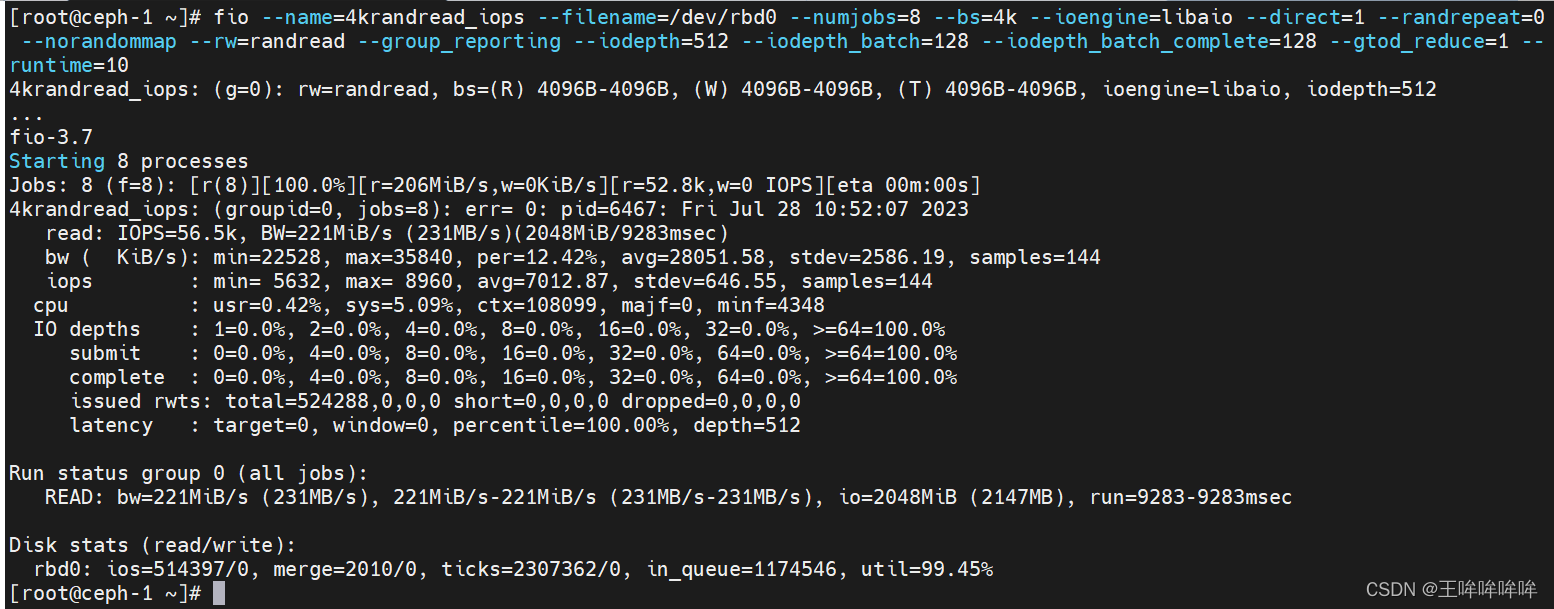
测试ceph rbd块设备的带宽
测试ceph rbd设备写4MB文件的极限带宽性能
fio --name=4mwrite_bw --filename=/dev/rbd0 --numjobs=8 --bs=4m --ioengine=libaio --direct=1 --randrepeat=0 --norandommap --rw=write --group_reporting --iodepth=512 --iodepth_batch=128 --iodepth_batch_complete=128 --gtod_reduce=1 --runtime=10
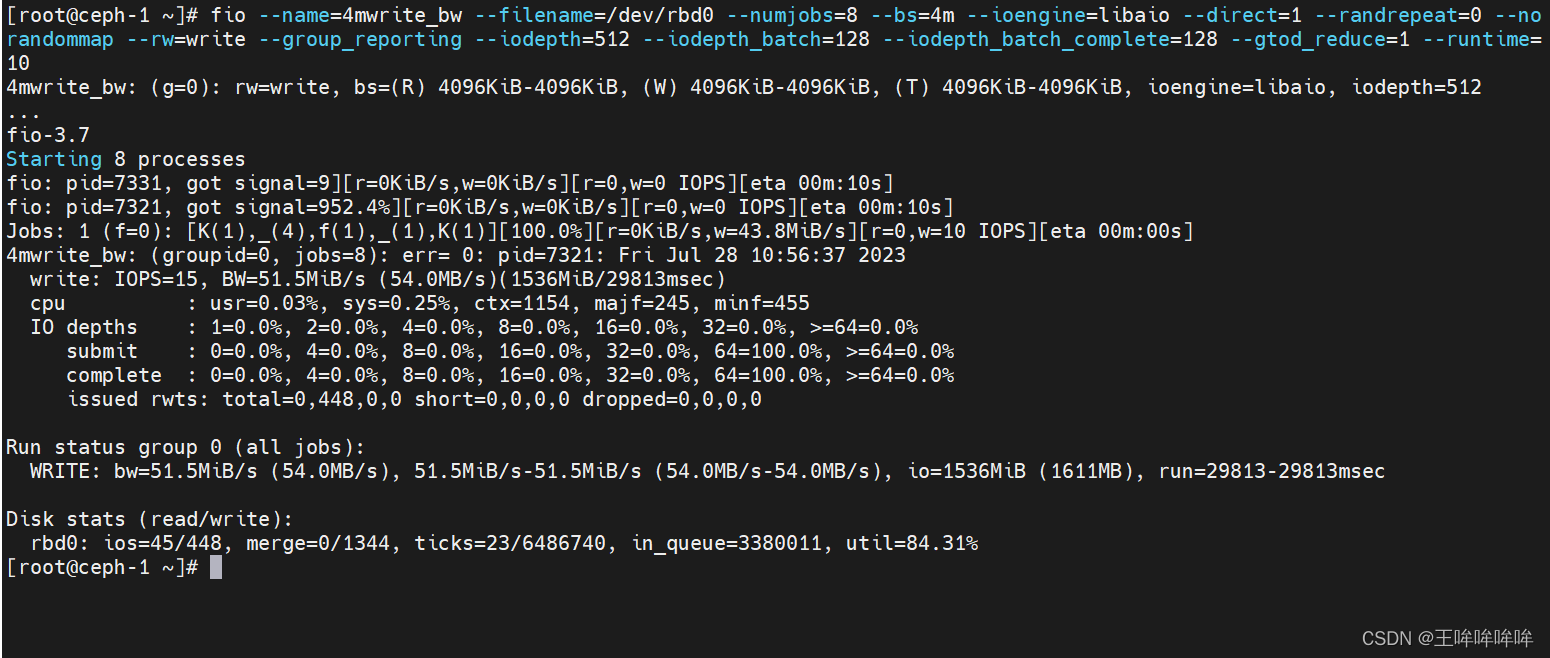
bw=这组进程的总带宽,每个线程的带宽
测试ceph rbd块设备的延迟
测试ceph rbd设备顺序写4kb文件的延迟性能
fio --name=4kwrite_lat --filename=/dev/rbd0 --numjobs=8 --bs=4k --ioengine=sync --direct=1 --randrepeat=0 --norandommap --rw=write --group_reporting --runtime=10
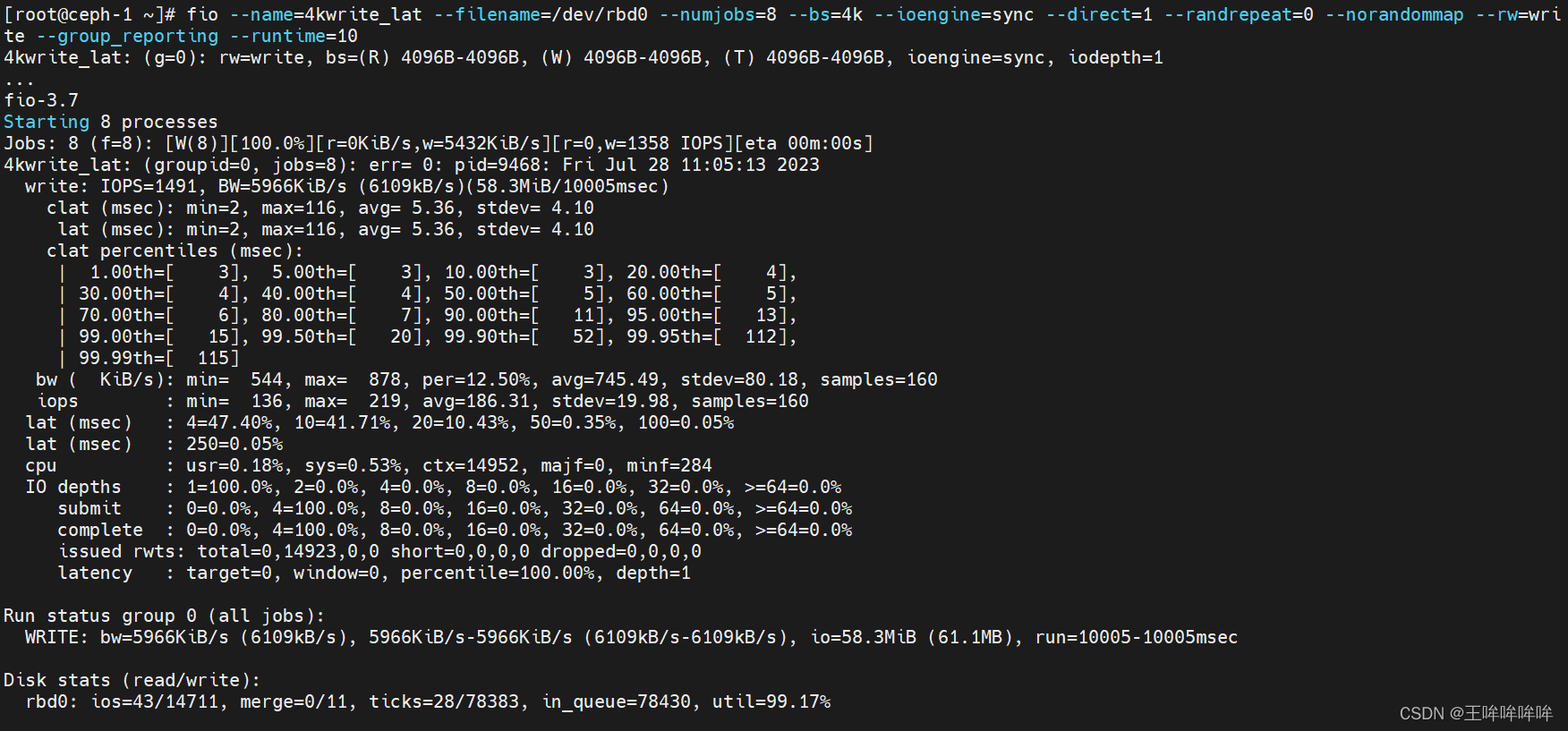
一些参数解释:
slat 表示fio 提交某个I/O的延迟(min为最小值,max为最大值,avg为平均值,stdev为标准偏差)。 对于同步I / O,不会显示该行。
clat 表示从提交到完成I / O的时间。
lat 表示从fio将请求提交给内核,再到内核完成这个I/O为止所需要的时间;
usec:微秒;msec:毫秒;1ms=1000us;
测试ceph rbd设备顺序读4kb文件的延迟性能
fio --name=4kread_lat --filename=/dev/rbd0 --numjobs=8 --bs=4k --ioengine=sync --direct=1 --randrepeat=0 --norandommap --rw=read --group_reporting --runtime=10
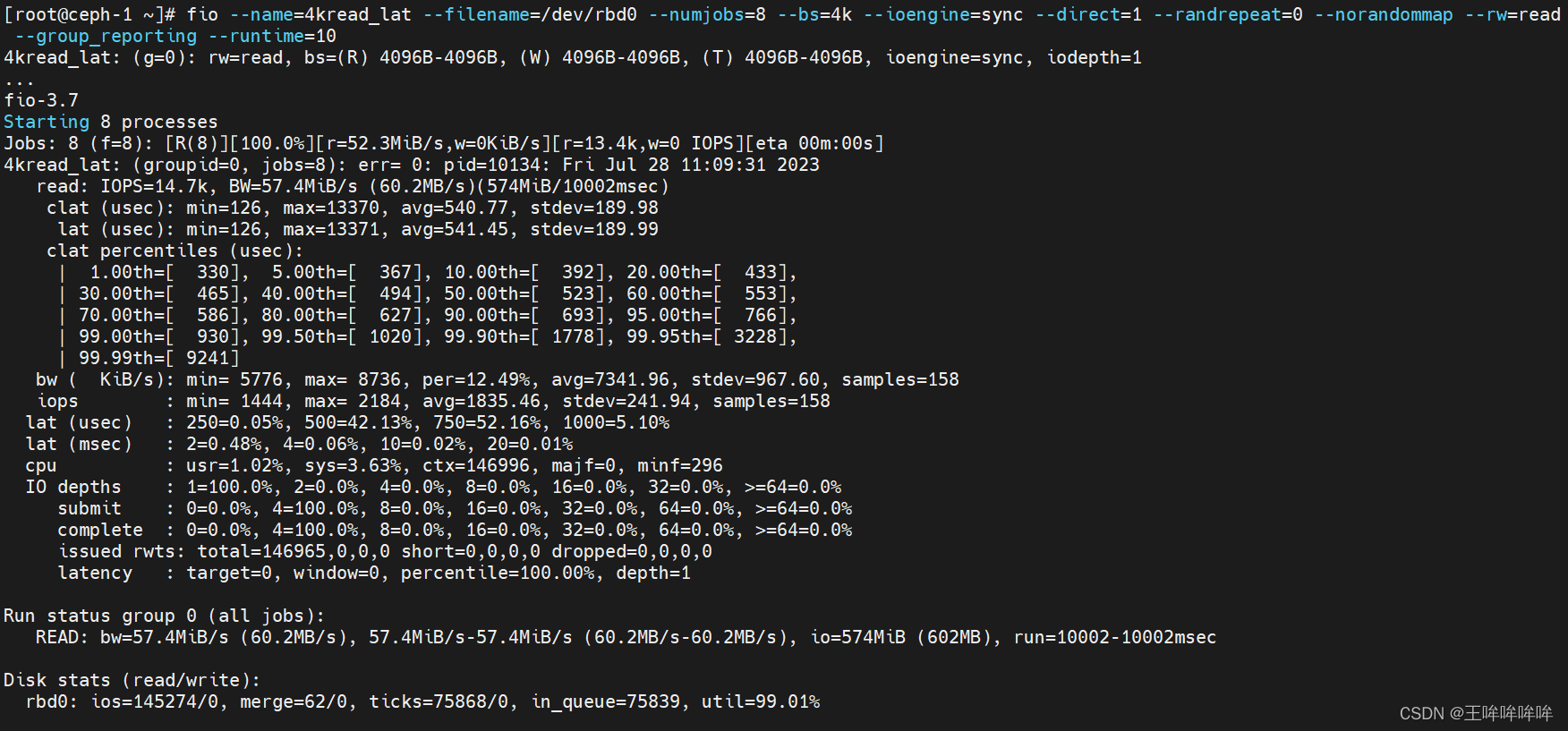
测试ceph rbd设备随机读4kb文件的延迟性能
fio --name=4krandread_lat --filename=/dev/rbd0 --numjobs=8 --bs=4k --ioengine=sync --direct=1 --randrepeat=0 --norandommap --rw=randread --group_reporting --runtime=10
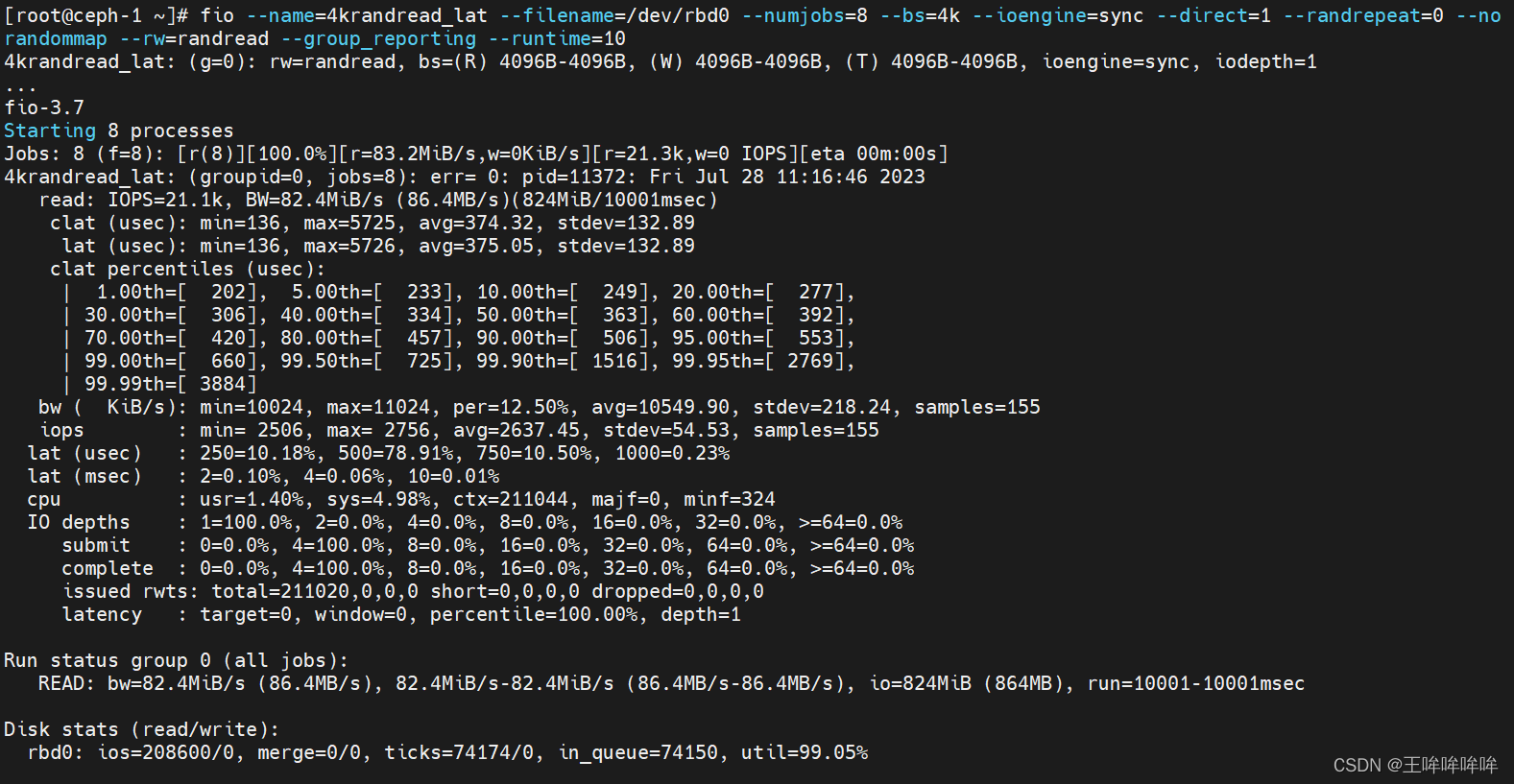
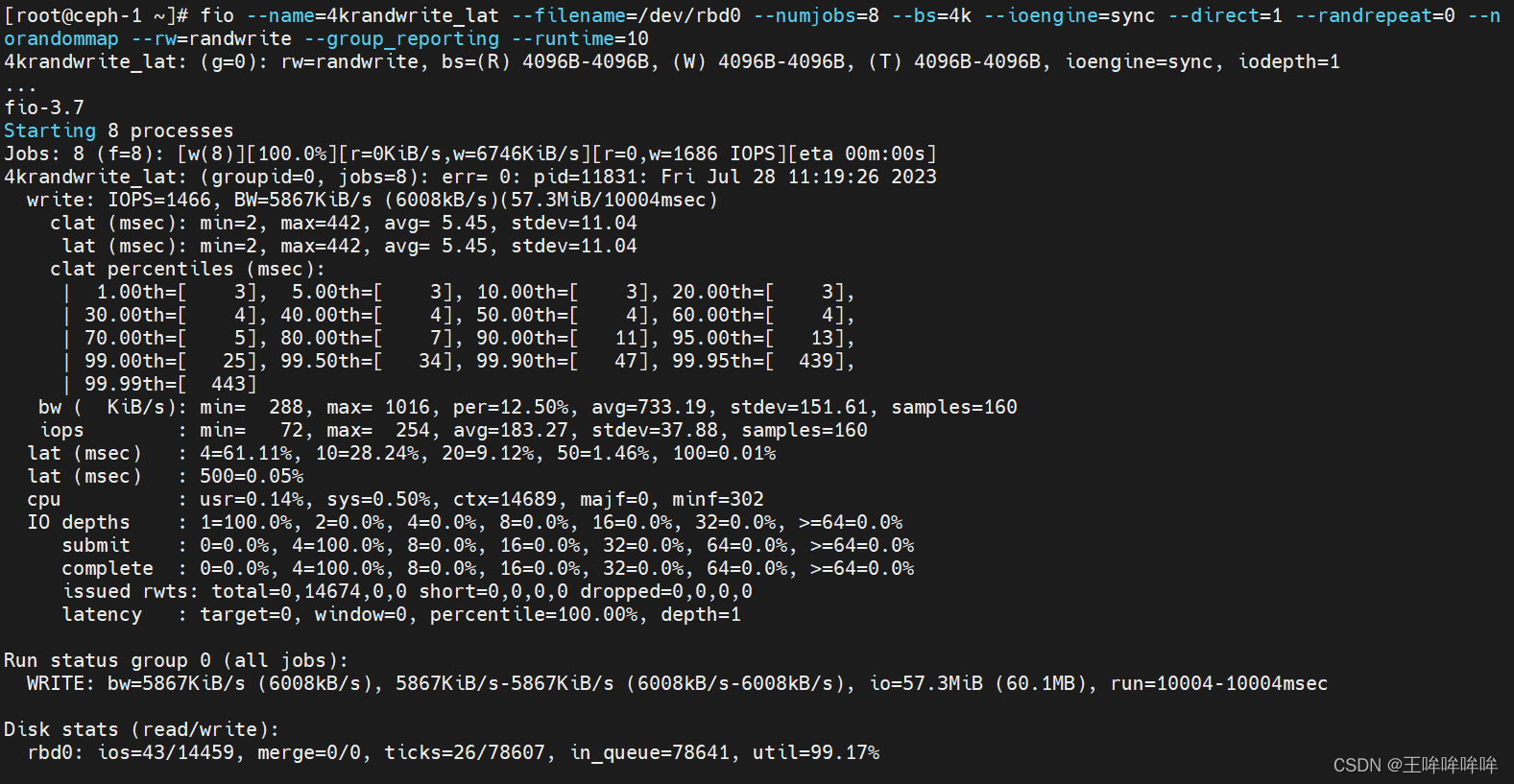
测试ceph rbd设备随机写4kb文件的延迟性能
fio --name=4krandwrite_lat --filename=/dev/rbd0 --numjobs=8 --bs=4k --ioengine=sync --direct=1 --randrepeat=0 --norandommap --rw=randwrite --group_reporting --runtime=10
性能调优
CPU调优:
ceph是使用软件定义的存储,因此其性能很大程度上依赖于OSD节点的CPU速度。CPU主频越高,则运行代码的速度就越快,同时处理io请求的时间就越短。
磁盘调优:
在磁盘参数和硬件配置相同的情况下,大量的io请求会向ceph osd写入数据,同时会向其他osd节点写入数据副本。如果OSD节点数量过少,那么会导致性能不高,因此增加osd数量,在某种程度上能提升写操作性能。
系统配置参数调优:
设置磁盘的预读缓存:【该参数通过预读取数据并将其加载到随机存取存储器中加快磁盘读操作,设置为较高的值有助于客户端顺序读取操作】
echo "8192" > /sys/block/vdc/queue/read_ahead_kb
设置系统的进程数量
echo 4194303 > /proc/sys/kernel/pid_max
ceph集群的配置参数:
为集群定义内部网络:
[global]
cluster network = {cluster network/netmask}
设置最大文件打开数:
[global]
max open files = 131072
ceph启用rbd缓存,默认的缓存机制是write-back
[client]
rbd cache = true
rbd cache size = 268435456 #rbd缓存大小
rbd cache max dirty = 134217728 #rbd缓存脏数据最大字节数,超过这个值之后,数据会写回备用存储。如果这个值设置为0,那么ceph使用的缓存模式是write-through
为了创建一个一致的提交操作,文件系统需要先静默写操作,并执行一次sync操作。然后将日志中的数据写到数据分区,再释放日志。如果同步操作太频繁,会导致日志中存放的数据很少,日志没有得到重复的利用。配置不那么频繁的同步操作,将有助于文件系统更好的合并写操作。有助于提升性能。
下面的参数定义了两次同步之间最小和最大的时间间隔。
[OSD]
filestore min sync interval = 10
filestore max sync interval = 15
文件存储队列的最大操作数:
[OSD]
filestore queue max ops = 25000
filestore queue max bytes = 10485760 #每个操作的最大字节数
文件系统最大操作线程数:
[OSD]
filestore op threads = 32
其他的一些参数有:
关于journal的参数:
比如可以设置一次性写入的最大字节数 journal max write bytes 、
一次性在队列中的操作数 journal queue max ops等
关于osd config tuning:
osd一次可写入的最大值,osd max write size
osd进程的最大线程数,osd op threads
关于osd client tuning:
rbd 缓存大小,rbd cache size
具体参数描述可以参考文章。