支持向量机(iris)
代码:
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn import svm
import numpy as np# 定义每一列的属性
colnames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']
# 读取数据
iris = pd.read_csv('data\\iris.data', names=colnames)# iris.head()是一个pandas库中的函数,用于显示数据集的前几行。默认情况下,它显示前5行数据。
"""sepal-length sepal-width petal-length petal-width class
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
"""
iris.head()# drop():删除行或列
X = iris.drop('class', axis=1) # 属性值
y = iris['class'] # 类别scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)clf = svm.SVC(kernel='linear')
clf.fit(X_scaled, y)# 随机生成3组测试数据,注意需要归一化处理
test_data = scaler.transform(np.array([[5.1, 3.5, 1.4, 0.2], [6.7, 3.1, 4.7, 1.5], [7.9, 3.8, 6.4, 2.0]]))# 获得模型预测结果
pred = clf.predict(test_data)print(pred)
对代码的解释:
因为iris.data中是这样的:
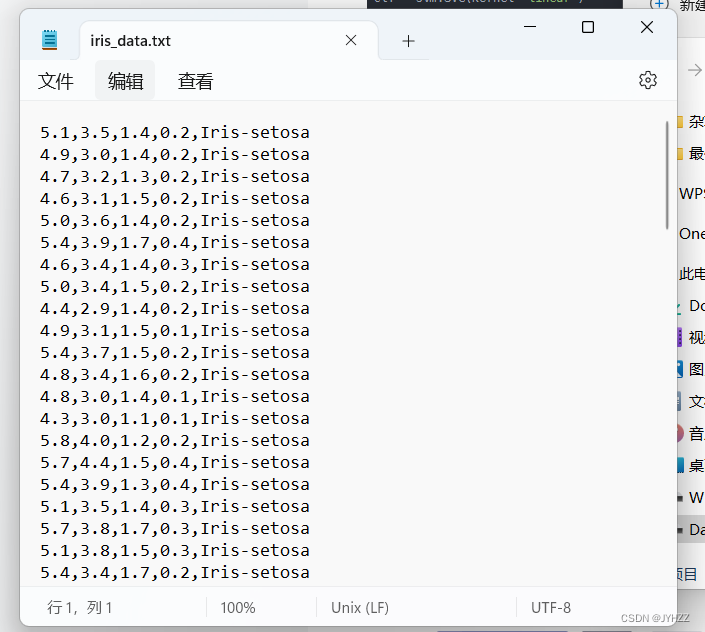
即前4列为属性,第5列为类别
定义属性与类别:
# 定义每一列的属性
colnames = ['sepal-length', 'sepal-width', 'petal-length', 'petal-width', 'class']读取数据,并给数据加上colnames:
# 读取数据
iris = pd.read_csv('data\\iris.data', names=colnames)print输出一下iris:
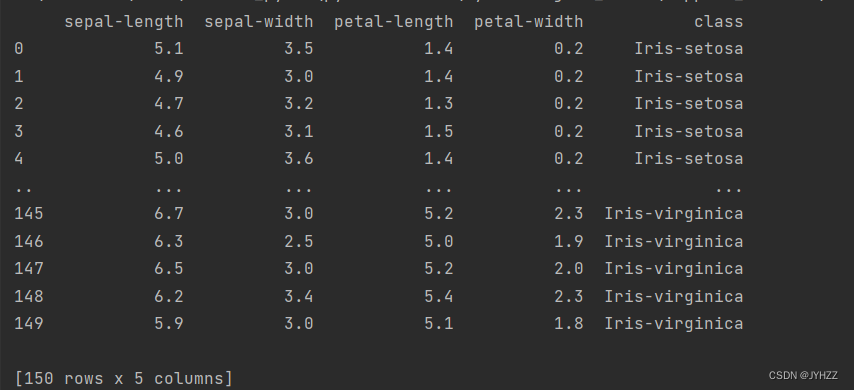
对于read_csv()方法:
(4条消息) 详解pandas的read_csv方法_小尛玮的博客-CSDN博客
对于head()函数:
# iris.head()是一个pandas库中的函数,用于显示数据集的前几行。默认情况下,它显示前5行数据。
"""sepal-length sepal-width petal-length petal-width class
0 5.1 3.5 1.4 0.2 Iris-setosa
1 4.9 3.0 1.4 0.2 Iris-setosa
2 4.7 3.2 1.3 0.2 Iris-setosa
3 4.6 3.1 1.5 0.2 Iris-setosa
4 5.0 3.6 1.4 0.2 Iris-setosa
"""
iris.head()对于drop()函数:
(3条消息) Pandas基本数据交互机制2-drop()方法_朱错错的哒哒哒的博客-CSDN博客
# drop():删除行或列
X = iris.drop('class', axis=1) # 属性值'class':去掉属性为class的一行或一列
axis=1:去掉某一行,加上参数axis就是去掉某一列
这行代码的返回值为去掉属性为class的那一列之后的数据集,即所有属性
y = iris['class'] # 类别这行代码返回值为类别那一列
对于StandardScaler()方法与fit_transform方法
(3条消息) sklearn中StandardScaler()_汽水配辣条的博客-CSDN博客
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)对于svm()方法
(3条消息) 【机器学习】svm.SVC参数详解_svm.svc中的参数以及作用_Xhfei1224的博客-CSDN博客
clf = svm.SVC(kernel='linear')
clf.fit(X_scaled, y)预测
# 随机生成3组测试数据,注意需要归一化处理
test_data = scaler.transform(np.array([[5.1, 3.5, 1.4, 0.2], [6.7, 3.1, 4.7, 1.5], [7.9, 3.8, 6.4, 2.0]]))# 获得模型预测结果
pred = clf.predict(test_data)print(pred)