[NLP]LLM高效微调(PEFT)--LoRA
LoRA
背景
神经网络包含很多全连接层,其借助于矩阵乘法得以实现,然而,很多全连接层的权重矩阵都是满秩的。当针对特定任务进行微调后,模型中权重矩阵其实具有很低的本征秩(intrinsic rank),因此,论文的作者认为权重更新的那部分参数矩阵尽管随机投影到较小的子空间,仍然可以有效的学习,可以理解为针对特定的下游任务这些权重矩阵就不要求满秩。
技术原理
LoRA(论文:LoRA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS),该方法的核心思想就是通过低秩分解来模拟参数的改变量,从而以极小的参数量来实现大模型的间接训练。
在涉及到矩阵相乘的模块,在原始的PLM旁边增加一个新的通路,通过前后两个矩阵A,B相乘,第一个矩阵A负责降维,第二个矩阵B负责升维,中间层维度为r,从而来模拟所谓的本征秩(intrinsic rank)。
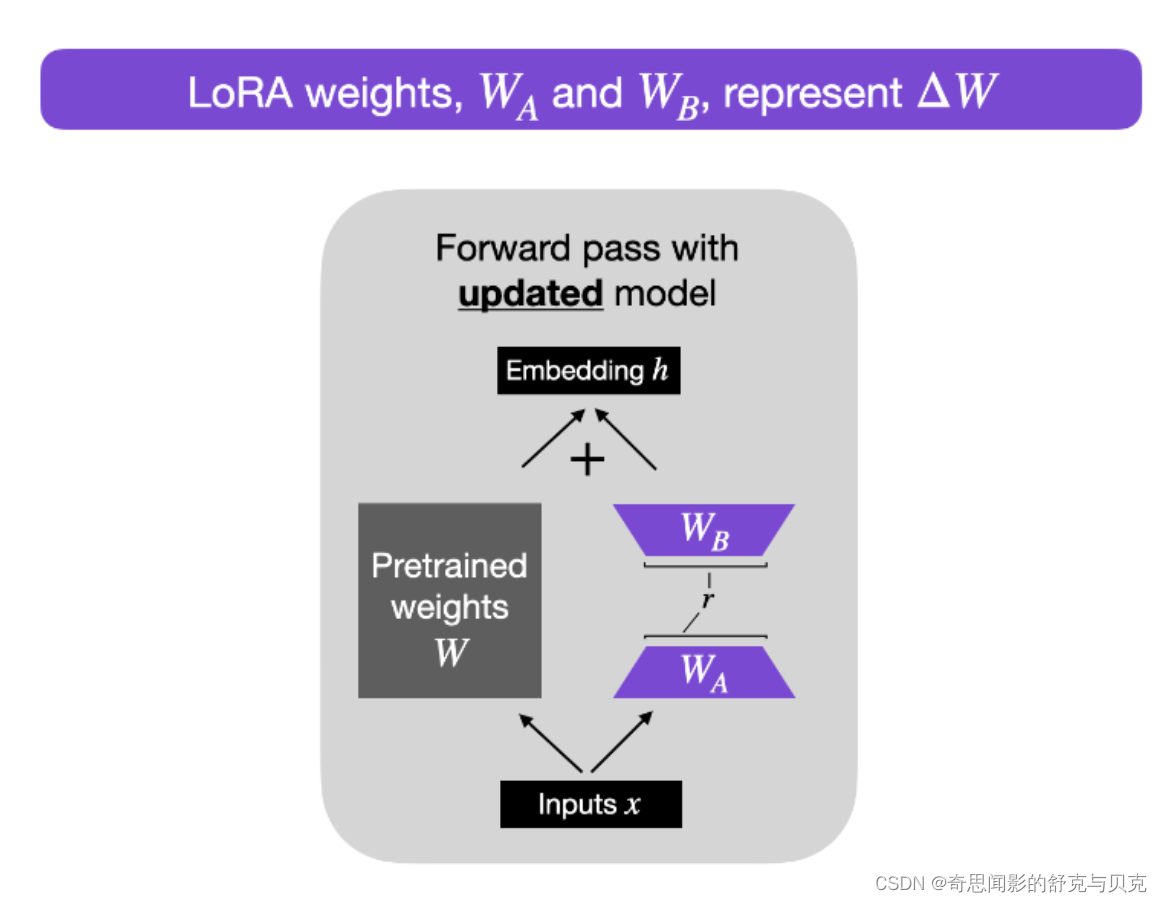
可训练层维度和预训练模型层维度一致为d,先将维度d通过全连接层降维至r,再从r通过全连接层映射回d维度,其中,r<<d,r是矩阵的秩,这样矩阵计算就从d x d变为d x r + r x d,参数量减少很多。
在下游任务训练时,固定模型的其他参数,只优化新增的两个矩阵的权重参数,将W跟新增的通路W1两部分的结果加起来作为最终的结果(两边通路的输入跟输出维度是一致的),即h=Wx+BAx。第一个矩阵的A的权重参数会通过高斯函数初始化,而第二个矩阵的B的权重参数则会初始化为零矩阵,这样能保证训练开始时新增的通路BA=0从而对模型结果没有影响。
在推理时,将左右两部分的结果加到一起即可,h=Wx+BAx=(W+BA)x,所以只要将训练完成的矩阵乘积BA跟原本的权重矩阵W加到一起作为新权重参数替换原本PLM的W即可,对于推理来说,不会增加额外的计算资源。
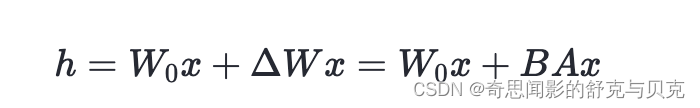
为什么更新ΔW只需要更新较少的参数呢?
现在,让我们解决房间里的大问题:如果我们引入新的权重矩阵,这个参数的效率如何?新矩阵WA和WB可以非常小。例如,假设A=100且B=500 ,则ΔW的大小为100 × 500 = 50,000。现在,如果我们将其分解为两个较小的矩阵,一个100×5维矩阵WA和一个5×500维矩阵WB。这两个矩阵总共只有5×100+5×500=3000个参数。
作者也在摘要中明确表示,他们采用lora方法微调,相比于GPT-3全量参数微调,可训练参数下降了10000倍,GPU显存需求下降了3倍,而lora微调后的效果,在特定任务上甚至可以媲美全量微调的模型。
为什么一直强调特定任务呢?因为lora基于的假设就是在特定任务上微调时,更新的参数矩阵具有较低的内在维度。可以把lora想象成一个特定能力的装备,而预训练模型是游戏角色本身。在预训练模型(游戏角色)的基础上,特定lora(装备)可以增强对于某一特定任务的表现,但是在其他不相关任务上该lora模块并不会起到作用。如果想同时在多个任务上有媲美全量参数微调模型的表现的话,就得需要针对不同的任务训练不同的ΔW模块(多个装备),最后整合在一起。但是,如果想模型(游戏角色)本身整体变强大,还是全量参数微调更合适。
至于是否适合作为通用指令微调的解决方案,有个问题我也没有搞懂,就是通用的指令样本是否真的有统一的低秩空间表征?这个表征又是什么含义?因为指令微调阶段的样本其实是混合的多任务指令样本,这种情况下lora是否合适,感觉需要更全面的评估.
## 初始化低秩矩阵A和B
self.lora_A.update(nn.ModuleDict({adapter_name: nn.Linear(self.in_features, r, bias=False)}))
self.lora_B.update(nn.ModuleDict({adapter_name: nn.Linear(r, self.out_features, bias=False)}))
self.scaling[adapter_name] = lora_alpha / r## 向前计算
result = F.linear(x, transpose(self.weight, self.fan_in_fan_out), bias=self.bias)
result += (self.lora_B[self.active_adapter](self.lora_A[self.active_adapter](self.lora_dropout[self.active_adapter](x)))* self.scaling[self.active_adapter]
)
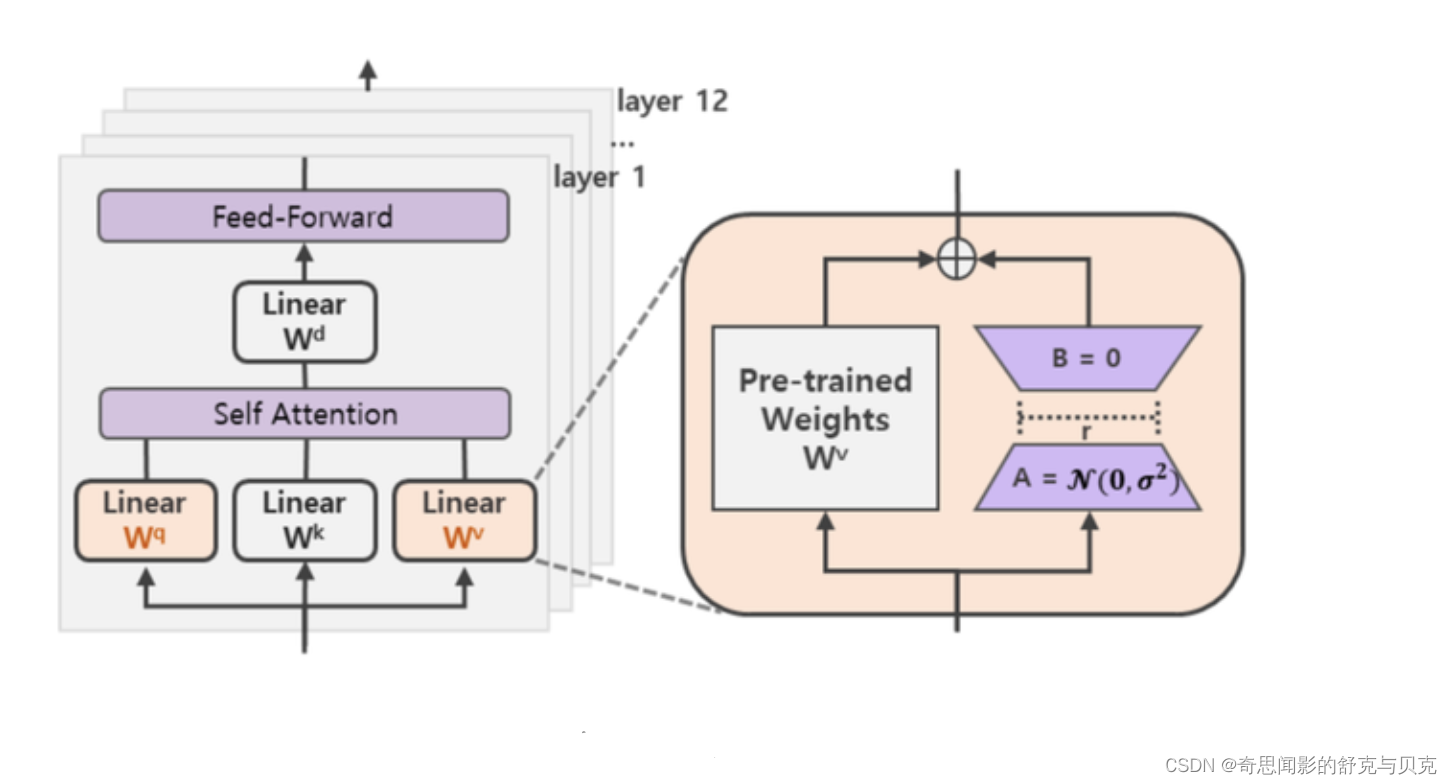
此外,Transformer的权重矩阵包括Attention模块里用于计算query, key, value的Wq,Wk,Wv以及多头attention的Wo,以及MLP层的权重矩阵,LoRA只应用于Attention模块中的4种权重矩阵,而且通过消融实验发现同时调整 Wq 和 Wv 会产生最佳结果。
input_dim = 768 # e.g., the hidden size of the pre-trained model
output_dim = 768 # e.g., the output size of the layer
rank = 8 # The rank 'r' for the low-rank adaptationW = ... # from pretrained network with shape input_dim x output_dimW_A = nn.Parameter(torch.empty(input_dim, rank)) # LoRA weight A
W_B = nn.Parameter(torch.empty(rank, output_dim)) # LoRA weight B# Initialization of LoRA weights
nn.init.kaiming_uniform_(W_A, a=math.sqrt(5))
nn.init.zeros_(W_B)def regular_forward_matmul(x, W):h = x @ W
return hdef lora_forward_matmul(x, W, W_A, W_B):h = x @ W # regular matrix multiplicationh += x @ (W_A @ W_B)*alpha # use scaled LoRA weights
return h在上面的伪代码中,alpha是一个缩放因子,用于调整组合结果(原始模型输出加上低秩自适应)的大小。这平衡了预训练模型的知识和新的特定于任务的适应——默认情况下,alpha通常设置为 1。另请注意,虽然W A被初始化为小的随机权重,但W B被初始化为 0,因此
训练开始时ΔW = W AW B = 0 ,这意味着我们以原始权重开始训练。
实验还发现,保证权重矩阵的种类的数量比起增加隐藏层维度r更为重要,增加r并不一定能覆盖更加有意义的子空间。
Rank r 的设置
一个很直接的问题就是:在实践中,rank 应该设为多少比较合适呢?
作者做了几组实验进行比较,结果发现 rank 可以很低,不超过8就很 OK 了,甚至是1也挺好..
关于秩的选择,通常情况下,rank为4,8,16即可。
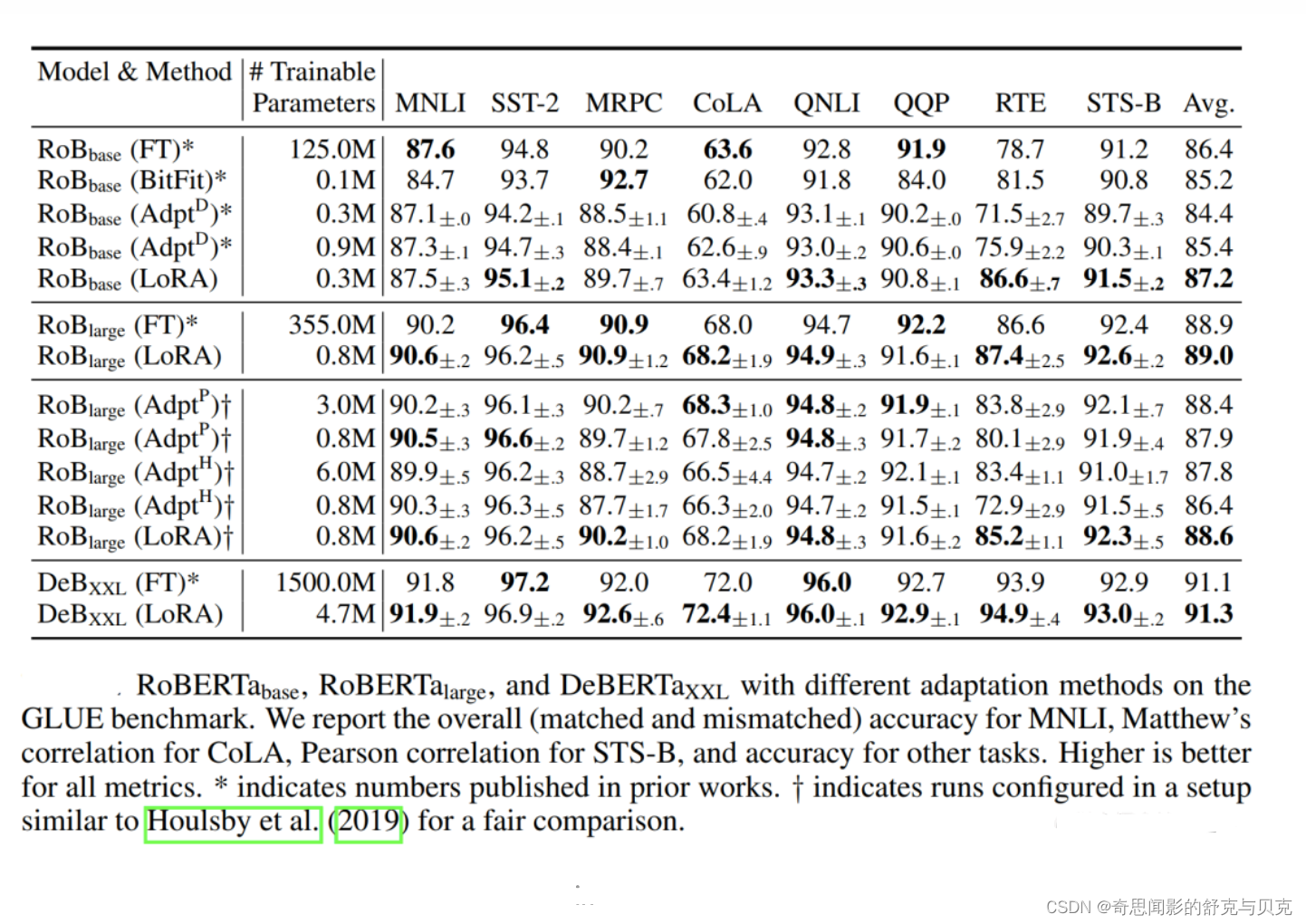
通过实验也发现,在众多数据集上LoRA在只训练极少量参数的前提下,最终在性能上能和全量微调匹配,甚至在某些任务上优于全量微调。
减少推理开销
请注意,在实践中,如果我们在训练后保持原始权重W和矩阵W A和W B分开,如上所示,我们将在推理过程中产生小的效率损失,因为这引入了额外的计算步骤。相反,我们可以在训练后通过W' = W + WA WB更新权重,这类似于前面提到的W' = W + ΔW。
然而,将权重矩阵W A和W B分开可能具有实际优势。例如,假设我们希望将我们的预训练模型作为各种客户的基础模型,并且我们希望从基础模型开始为每个客户创建一个经过微调的 LLM。在这种情况下,我们不需要为每个客户存储完整的权重矩阵W',其中存储模型的所有权重W' = W + WA WB对于 LLM 来说可能非常大,因为 LLM 通常有数十亿到数万亿个权重参数。因此,我们可以保留原始模型W,只需要存储新的轻量级矩阵WA和WB。
为了用具体数字说明这一点,一个完整的 7B LLaMA 检查点需要 23GB 的存储容量,而如果我们选择r=8的等级,LoRA 权重可以小到 8MB 。
利用 LoRA可以如下优点:
- 在面对不同的下游任务时,仅需训练参数量很少的低秩矩阵,而预训练权重可以在这些任务之间共享;
- 省去了预训练权重的梯度和相关的 optimizer states,大大增加了训练效率并降低了硬件要求;
- 训练好的低秩矩阵可以合并(merge)到预训练权重中,多分支结构变为单分支,从而达到没有推理延时的效果;
- 与之前的一些参数高效的微调方法(如 Adapter, Prefix-Tuning 等)互不影响,并且可以相互结合
QLoRA和AdaLoRA
当红炸子鸡 LoRA,是当代微调 LLMs 的正确姿势? - 知乎 (zhihu.com)