【ViT系列(2)】ViT(Vision Transformer)代码超详细解读(Pytorch)

前言
上一篇我们一起读了ViT的论文(【ViT系列(1)】《AN IMAGE IS WORTH 16X16 WORDS:TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE》论文超详细解读(翻译+精读)),大致了解了这个模型,那么接下来这篇就来看一看代码是如何实现的。
本文会介绍两个版本,一个是论文源码,这个比较复杂,我也是看了很多大佬的讲解才读通(小菜鸡啦~),在文末会放上这些链接。后来又找到了大佬复现的简易版本,这个版本的代码比较受欢迎且易使用,对新手小白比较友好,那我们就来讲解一下第二个版本吧!

 🍀前期回顾
🍀前期回顾
【Transformer系列(1)】encoder(编码器)和decoder(解码器)
【Transformer系列(2)】注意力机制、自注意力机制、多头注意力机制、通道注意力机制、空间注意力机制超详细讲解
【Transformer系列(3)】 《Attention Is All You Need》论文超详细解读(翻译+精读)
【Transformer系列(4)】Transformer模型结构超详细解读
【Transformer系列(5)】Transformer代码超详细解读(Pytorch)
目录
前言
✨一、ViT网络结构讲解
✨二、简易版本
⚡️2.1 导入依赖库
⚡️2.2 pair函数
⚡️2.3 PreNorm层
⚡️2.4 FFN层
⚡️2.5 Attention层
⚡️2.6 构建Transformer
⚡️2.7 构建ViT
使用案例
完整代码
✨三、官方提供代码版本

✨一、ViT网络结构讲解
下图是ViT模型
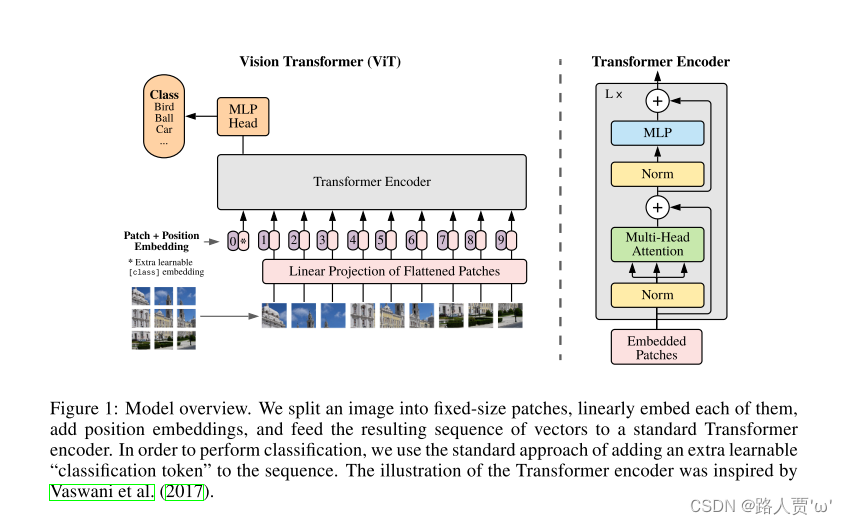
(1)第1部分:将图形转化为序列化数据
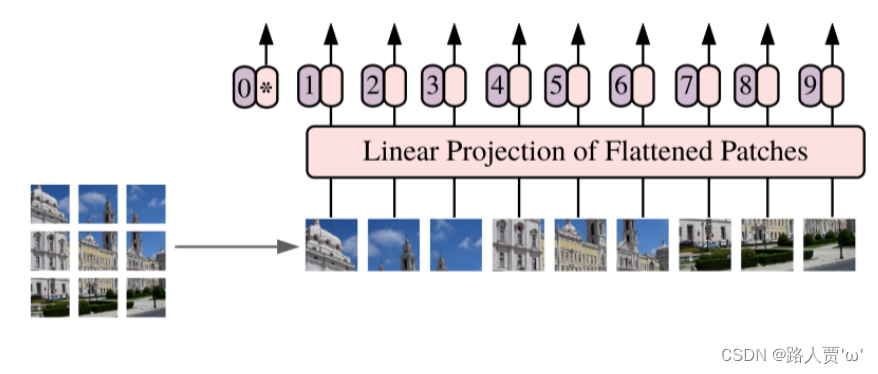
- 首先输入为一张图片,将图片划分成9个patch,然后将每个patch重组成一个向量,得到所谓的flattened patch。
- 如果图片是H×W×C维的,就用P×P大小的patch去分割图片可以得到N个patch,那么每个patch的大小就是P×P×C,将N个patch 重组后的向量concat在一起就得到了一个N×P×P×C的二维矩阵,相当于NLP中输入Transformer的词向量。
- patch大小变化时,重组后的向量维度也会变化,作者对上述过程得到的flattened patch向量做了Linear Projection,将不同长度的flattened patch向量转化为固定长度的向量(记作D维向量)。
综上,原本H×W×C 维的图片被转化为了N个D维的向量(或者一个N×D维的二维矩阵)。
(2)第2部分:Position embedding
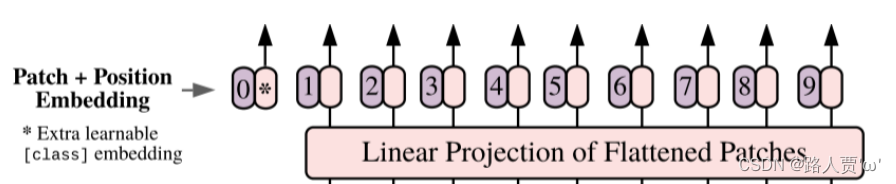
由于Transformer模型本身是没有位置信息的,和NLP中一样,我们需要用position embedding将位置信息加到模型中去。
如上图所示,编号有0-9的紫色框表示各个位置的position embedding,而紫色框旁边的粉色框则是经过linear projection之后的flattened patch向量。
文中采用将position embedding(即图中紫色框)和patch embedding(即图中粉色框)相加的方式结合position信息。
(3)第3部分:Learnable embedding
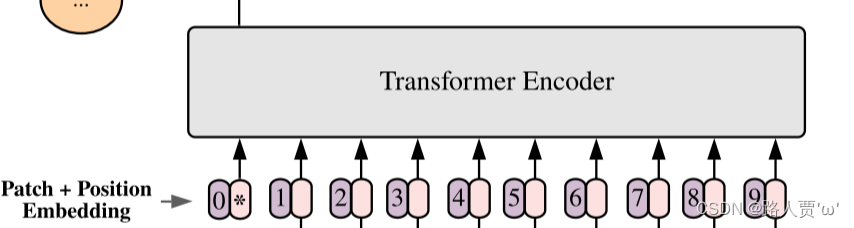
将 patch 输入一个 Linear Projection of Flattened Patches 这个 Embedding 层,就会得到一个个向量,通常就称作 tokens。tokens包含position信息以及图像信息。
紧接着在一系列 token 的前面加上加上一个新的 token,叫做class token,也就是上图带星号的粉色框(即0号紫色框右边的那个),注意这个不是通过某个patch产生的。其作用类似于BERT中的[class] token。在BERT中,[class] token经过encoder后对应的结果作为整个句子的表示;class token也是其他所有token做全局平均池化,效果一样。
(4)第4部分:Transformer encoder

最后输入到 Transformer Encoder 中,对应着右边的图,将 block 重复堆叠 L 次,整个模型也就包括 L 个 Transformer。Transformer Encoder结构和NLP中Transformer结构基本上相同,class embedding 对应的输出经过 MLP Head 进行类别判断。
关于encoder和decoder的详解,可以看这篇:【Transformer系列(1)】encoder(编码器)和decoder(解码器)
✨二、简易版本
大佬复现版本代码:https://github.com/lucidrains/vit-pytorch
ViT网络结构如下:

⚡️2.1 导入依赖库
#======================1.导入依赖库=============================#
import torch
from torch import nn, einsum
import torch.nn.functional as F
from einops import rearrange, repeat
from einops.layers.torch import Rearrange- torch: 这是主要的Pytorch库。它提供了构建、训练和评估神经网络的工具
- torch.nn: torch下包含用于搭建神经网络的modules和可用于继承的类的一个子包
- torch.einsum: 对输入元素 沿指定的维度、使用爱因斯坦求和符号的乘积求和
- torch.nn.functional: 这是函数,一般在_init_ 中初始化相应参数,在forward中传入
- einops: 灵活和强大的张量操作,可读性强和可靠性好的代码。支持numpy、pytorch、tensorflow等。有了他,研究者们可以自如地操作张量的维度,使得研究者们能够简单便捷地实现并验证自己的想法,在Vision Transformer等需要频繁操作张量维度的代码实现里极其有用。
- einops.layers.torch中的Rearrange: 用于搭建网络结构时对张量进行“隐式”的处理
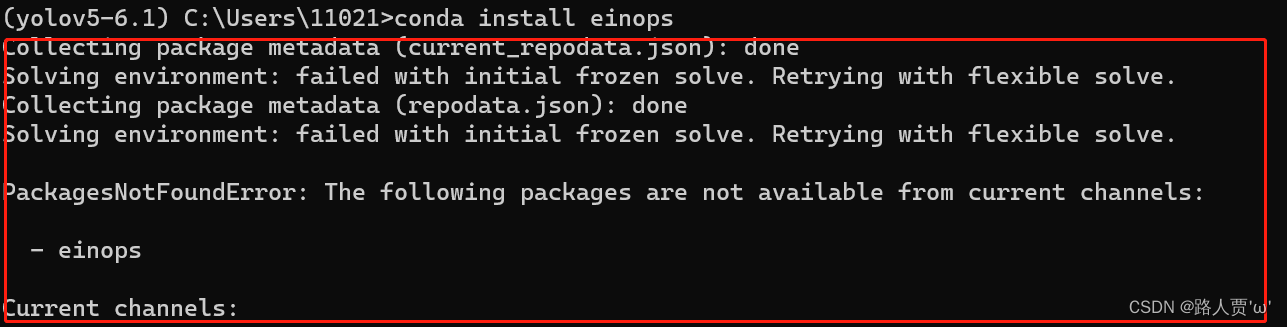
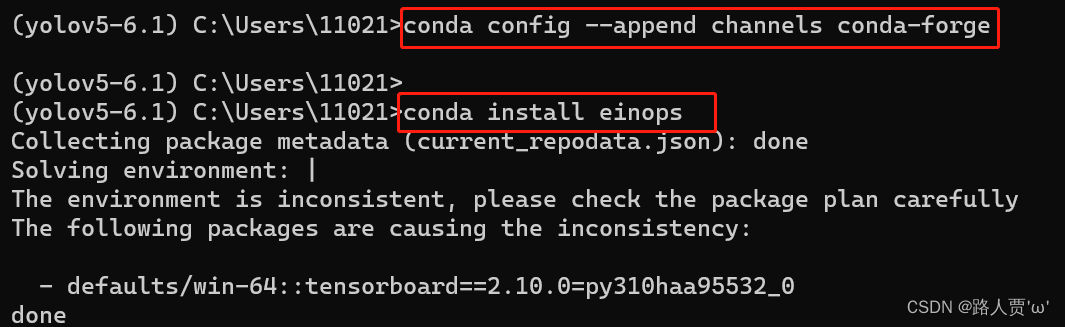
如何导入eionps?
conda install einops这时可能会报错
我们需要先输入
conda config--append channels conda-forge然后再输入上面的命令就好了
⚡️2.2 pair函数
#======================2.pair函数=============================#
# 辅助函数,生成元组
def pair(t):return t if isinstance(t, tuple) else (t, t)这段代码的作用是:判断t是否是元组,如果是,直接返回t;如果不是,则将t复制为元组(t, t)再返回。
用来处理当给出的图像尺寸或块尺寸是int类型(如224)时,直接返回为同值元组(如(224, 224))。
⚡️2.3 PreNorm层
#======================3.PreNorm=============================#
# 规范化层的类封装
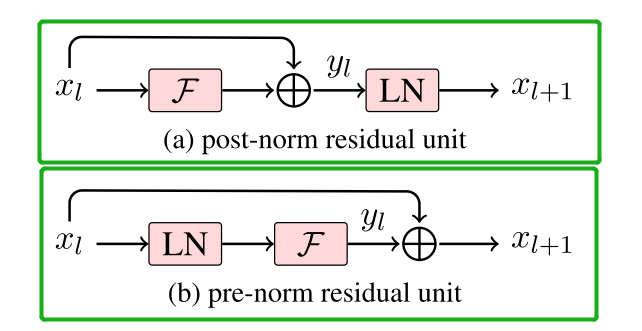
class PreNorm(nn.Module):''':param dim 输入和输出维度fn 前馈网络层,选择Multi-Head Attn和MLP二者之一'''def __init__(self, dim, fn):super().__init__()# LayerNorm: ( a - mean(last 2 dim) ) / sqrt( var(last 2 dim) )# 数据归一化的输入维度设定,以及保存前馈层self.norm = nn.LayerNorm(dim)self.fn = fn# 前向传播就是将数据归一化后传递给前馈层def forward(self, x, **kwargs):return self.fn(self.norm(x), **kwargs)PreNorm对应框图中最下面的黄色的Norm层。
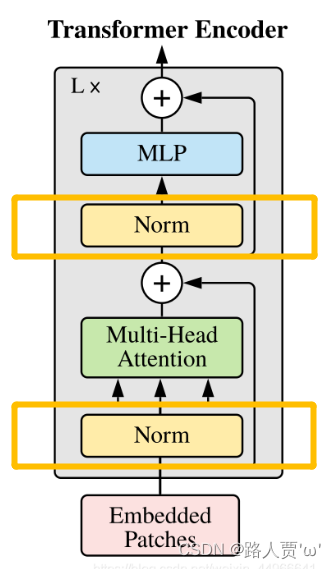
结构往往更容易训练,可以在反向时防止梯度爆炸或者梯度消失。
包含两个参数:
- dim: 输入和输出维度
- fn: 前馈网络层,选择Multi-Head Attn和MLP二者之一
⚡️2.4 FFN层
#======================4.FeedForward=============================#
# FFN
class FeedForward(nn.Module):def __init__(self, dim, hidden_dim, dropout=0.):super().__init__()self.net = nn.Sequential(nn.Linear(dim, hidden_dim),nn.GELU(),nn.Dropout(dropout),nn.Linear(hidden_dim, dim),nn.Dropout(dropout))def forward(self, x):return self.net(x)
FeedForward层由线性层,配合激活函数GELU和Dropout实现,对应框图中蓝色的MLP。
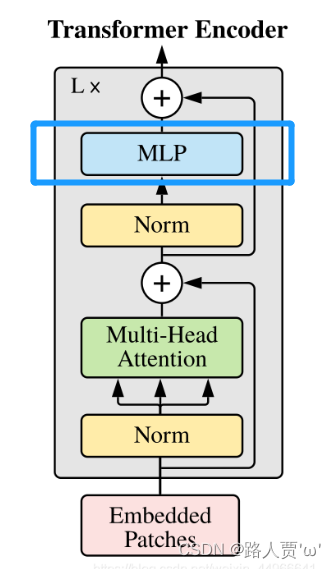
Multi-Head Attention的输出做了残差连接和Norm之后得数据,然后FeedForward做了两次线性变换,目的是更加深入的提取特征。
包含三个参数:
- dim: 输入和输出维度
- hidden_dim: 中间层的维度
- dropout: dropout操作的概率参数p
FeedForward层共有2个全连接层,整个结构是:
- 首先过一个全连接层
- 经过GELU()激活函数进行处理
- nn.Dropout(),以一定概率丢失掉一些神经元,防止过拟合
- 再过一个全连接层
- nn.Dropout()
注意:GELU(x) = x * Φ(x), 其中,Φ(x)是高斯分布的累积分布函数 。
⚡️2.5 Attention层
#======================5.Attention=============================#
# Attention
class Attention(nn.Module):def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):super().__init__()inner_dim = heads * dim_headproject_out = not (heads == 1 and dim_head == dim)self.heads = heads# 表示1/(sqrt(dim_head))用于消除误差,保证方差为1,避免向量内积过大导致的softmax将许多输出置0的情况# 可以看原文《attention is all you need》中关于Scale Dot-Product Attention如何抑制内积过大self.scale = dim_head ** -0.5# dim = > 0 时,表示mask第d维度,对相同的第d维度,进行softmax# dim = < 0 时,表示mask倒数第d维度,对相同的倒数第d维度,进行softmaxself.attend = nn.Softmax(dim = -1)# 生成qkv矩阵,三个矩阵被放在一起,后续会被分开self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)# 如果是多头注意力机制则需要进行全连接和防止过拟合,否则输出不做更改self.to_out = nn.Sequential(nn.Linear(inner_dim, dim),nn.Dropout(dropout)) if project_out else nn.Identity()def forward(self, x):# 分割成q、k、v三个矩阵# qkv为 inner_dim * 3,其中inner_dim = heads * dim_headqkv = self.to_qkv(x).chunk(3, dim = -1)# qkv的维度是(3, inner_dim = heads * dim_head)# 'b n (h d) -> b h n d' 重新按思路分离出8个头,一共8组q,k,v矩阵# rearrange后维度变成 (3, heads, dim, dim_head)# 经过map后,q、k、v维度变成(1, heads, dim, dim_head)q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)# query * key 得到对value的注意力预测,并通过向量内积缩放防止softmax无效化部分参数# heads * dim * dimdots = torch.matmul(q, k.transpose(-1, -2)) * self.scale# 对最后一个维度进行softmax后得到预测的概率值attn = self.attend(dots)# 乘积得到预测结果# out -> heads * dim * dim_headout = torch.matmul(attn, v)# 重组张量,将heads维度重新还原out = rearrange(out, 'b h n d -> b n (h d)')return self.to_out(out)Attention是Transformer中的核心部件,对应框图中的绿色的Multi-Head Attention。
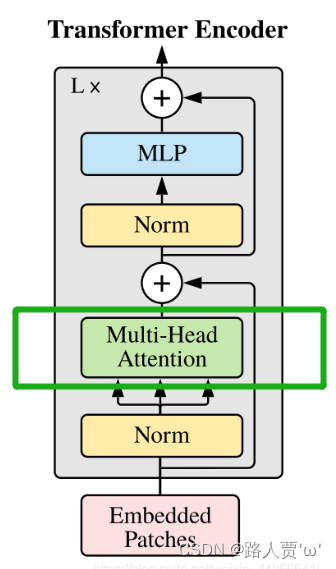
包含四个参数:
- dim: 输入和输出维度
- heads: 多头自注意力的头的数目
- dim_head: 每个头的维度
- dropout: dropout操作的概率参数p
Attention操作的整体流程:
- 首先对输入生成query, key和value,这里的“输入”有可能是整个网络的输入,也可能是某个hidden layer的output。在这里,生成的qkv是个长度为3的元组,每个元组的大小为(1, 65, 1024)
- 对qkv进行处理,重新指定维度,得到的q, k, v维度均为(1, 16, 65, 64)
- q和k做点乘,得到的dots维度为(1, 16, 65, 65)
- 对dots的最后一维做softmax,得到各个patch对其他patch的注意力得分
- 将attention和value做点乘
- 对各个维度重新排列,得到与输入相同维度的输出 (1, 65, 1024)
⚡️2.6 构建Transformer
#======================7.构建Transformer=============================#
# Transformer
class Transformer(nn.Module):def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):super().__init__()# 设定depth个encoder相连,并添加残差结构self.layers = nn.ModuleList([])for _ in range(depth):self.layers.append(nn.ModuleList([PreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))]))def forward(self, x):# 每次取出包含Norm-attention和Norm-mlp这两个的ModuleList,实现残差结构for attn, ff in self.layers:x = attn(x) + xx = ff(x) + xreturn x把上面的层定义好之后,我们就可以构建整个Transformer Block了。
⚡️2.7 构建ViT
#======================8.构建ViT=============================#
# ViT
class ViT(nn.Module):def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):super().__init__()# image_size就是每一张图像的长和宽,通过pair函数便捷明了的表现# patch_size就是图像的每一个patch的长和宽image_height, image_width = pair(image_size)patch_height, patch_width = pair(patch_size)# 保证图像可以整除为若干个patchassert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'# 计算出每一张图片会被切割为多少个patch# 假设输入维度(64, 3, 224, 224), num_patches = 49num_patches = (image_height // patch_height) * (image_width // patch_width)# 每一个patch数组大小, patch_dim = 3*32*32=3072patch_dim = channels * patch_height * patch_width# cls就是分类的Token, mean就是均值池化assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'# embeding操作:假设输入维度(64, 3, 224, 224),那么经过Rearange层后变成了(64, 7*7=49, 32*32*3=3072)self.to_patch_embedding = nn.Sequential(# 将图片分割为b*h*w个三通道patch,b表示输入图像数量Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),# 经过线性全连接后,维度变成(64, 49, 128)nn.Linear(patch_dim, dim),)# dim张图像,每张图像需要num_patches个向量进行编码# 位置编码(1, 50, 128) 本应该为49,但因为cls表示类别需要增加一个self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim))# CLS类别token,(1, 1, 128)self.cls_token = nn.Parameter(torch.randn(1, 1, dim))# 设置dropoutself.dropout = nn.Dropout(emb_dropout)# 初始化Transformerself.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout)# pool默认是cls进行分类self.pool = poolself.to_latent = nn.Identity()# 多层感知用于将最终特征映射为2个类别self.mlp_head = nn.Sequential(nn.LayerNorm(dim),nn.Linear(dim, num_classes))def forward(self, img):# 第一步,原始图像ebedding,进行了图像切割以及线性变换,变成x->(64, 49, 128)x = self.to_patch_embedding(img)# 得到原始图像数目和单图像的patches数量, b=64, n=49b, n, _ = x.shape# (1, 1, 128) -> (64, 1, 128) 为每一张图像设置一个cls的tokencls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)# 将cls token加入到数据中 -> (64, 50, 128)x = torch.cat((cls_tokens, x), dim=1)# x(64, 50, 128)添加位置编码(1, 50, 128)x += self.pos_embedding[:, :(n + 1)]# 经过dropout层防止过拟合x = self.dropout(x)x = self.transformer(x)# 进行均值池化x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]x = self.to_latent(x)# 最终进行分类映射return self.mlp_head(x)ViT就是图中的右边部分。
包含参数:
- *: input data
- image_size: 等边图像尺寸
- patch_size: patch的尺寸
- num_classes: 分类类别
- dim: 为每一个patch编码的长度
- depth: Encoder的深度,也就是连接encoder的数目
- heads: 多头注意力中头的数目
- mlp_dim: 多层感知器中隐含层的维度
- pool: 使用cls token还是使用均值池化
- channel: 图像的通道数
- dim_head: 注意力机制中一个头的输入维度
- dropout: NormLayer中dropout的参数比例
- emb_dropout: Embedding中的dropout比例
ViT操作的整体流程:
- 首先对输入进来的img(256*256大小),划分为32*32大小的patch,共有8*8个。并将patch转换成embedding。
- 生成cls_tokens
- 将cls_tokens沿dim=1维与x进行拼接
- 生成随机的position embedding,每个embedding都是1024维
- 对输入经过Transformer进行编码
- 如果是分类任务的话,截取第一个可学习的class embedding
- 最后过一个MLP Head用于分类。
以上就是ViT模型的定义啦~
使用案例
在训练脚本中实例化一个ViT模型来进行训练即可,以下脚本是大佬给的案例,可验证ViT模型正常运作。
import torch
from vit_pytorch import ViTv = ViT(image_size = 256, # 图像大小patch_size = 32, # patch大小(分块的大小)num_classes = 1000, # imagenet数据集1000分类dim = 1024, # position embedding的维度depth = 6, # encoder和decoder中block层数是6heads = 16, # multi-head中head的数量为16mlp_dim = 2048,dropout = 0.1, # emb_dropout = 0.1
)img = torch.randn(1, 3, 256, 256)preds = v(img) # (1, 1000)
完整代码
## from https://github.com/lucidrains/vit-pytorch
import torch
from torch import nnfrom einops import rearrange, repeat
from einops.layers.torch import Rearrangedef pair(t):return t if isinstance(t, tuple) else (t, t)class PreNorm(nn.Module):# 在执行fn之前执行一个Layer Normdef __init__(self, dim, fn):super().__init__()self.norm = nn.LayerNorm(dim)self.fn = fndef forward(self, x, **kwargs):return self.fn(self.norm(x), **kwargs)class FeedForward(nn.Module):def __init__(self, dim, hidden_dim, dropout = 0.):super().__init__()# 前馈神经网络 = 2个全连接层self.net = nn.Sequential(nn.Linear(dim, hidden_dim),nn.GELU(),nn.Dropout(dropout),nn.Linear(hidden_dim, dim),nn.Dropout(dropout))def forward(self, x):return self.net(x)class Attention(nn.Module):def __init__(self, dim, heads = 8, dim_head = 64, dropout = 0.):super().__init__()inner_dim = dim_head * headsproject_out = not (heads == 1 and dim_head == dim)self.heads = headsself.scale = dim_head ** -0.5 # 缩放因子self.attend = nn.Softmax(dim = -1)self.to_qkv = nn.Linear(dim, inner_dim * 3, bias = False)self.to_out = nn.Sequential(nn.Linear(inner_dim, dim),nn.Dropout(dropout)) if project_out else nn.Identity()def forward(self, x):# x: [bs, 197, 1024] 197 = 1个Cls + 196个patch 1024就是每一个patch需要转为1024长度的向量# self.to_qkv(x)将x向量映射到长度为1024*3# chunk: qkv 最后是一个元祖,tuple,长度是3,每个元素形状:[1, 197, 1024]# 直接用x配合一个Linear生成qkv,再切分为3块qkv = self.to_qkv(x).chunk(3, dim = -1)# 再把qkv分别拆分开来# q: [1, 16, 197, 64] k: [1, 16, 197, 64] v: [1, 16, 197, 64]q, k, v = map(lambda t: rearrange(t, 'b n (h d) -> b h n d', h = self.heads), qkv)# q * k转置 除以根号d_kdots = torch.matmul(q, k.transpose(-1, -2)) * self.scale# softmax得到每个token对于其他token的attention系数attn = self.attend(dots)# * v [1, 16, 197, 64]out = torch.matmul(attn, v)# [1, 197, 1024]out = rearrange(out, 'b h n d -> b n (h d)')return self.to_out(out)class Transformer(nn.Module):def __init__(self, dim, depth, heads, dim_head, mlp_dim, dropout = 0.):super().__init__()self.layers = nn.ModuleList([])for _ in range(depth): # 堆叠多个Encoder depth个self.layers.append(nn.ModuleList([# 每个encoder = Attention(Multi-Head Attention) + FeedForward(MLP)# PreNorm:指在fn(Attention/FeedForward)之前执行一个Layer NormPreNorm(dim, Attention(dim, heads = heads, dim_head = dim_head, dropout = dropout)),PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))]))def forward(self, x):for attn, ff in self.layers:x = attn(x) + xx = ff(x) + xreturn xclass ViT(nn.Module):def __init__(self, *, image_size, patch_size, num_classes, dim, depth, heads, mlp_dim, pool = 'cls', channels = 3, dim_head = 64, dropout = 0., emb_dropout = 0.):super().__init__()image_height, image_width = pair(image_size) # 224*224patch_height, patch_width = pair(patch_size) # 16 * 16assert image_height % patch_height == 0 and image_width % patch_width == 0, 'Image dimensions must be divisible by the patch size.'num_patches = (image_height // patch_height) * (image_width // patch_width) # 得到多少个token 14x14=196patch_dim = channels * patch_height * patch_width # 3x16x16 = 768 patch展平后的维度assert pool in {'cls', 'mean'}, 'pool type must be either cls (cls token) or mean (mean pooling)'self.to_patch_embedding = nn.Sequential(Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width), # 把所有的patch拉平->768维nn.Linear(patch_dim, dim), # 映射到encoder需要的维度768->1024)self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim)) # 生成所有token和Cls的位置编码self.cls_token = nn.Parameter(torch.randn(1, 1, dim)) # 生成Cls的初始化参数self.dropout = nn.Dropout(emb_dropout) # embedding后面一般会接的一个Dropoutself.transformer = Transformer(dim, depth, heads, dim_head, mlp_dim, dropout) # encoderself.pool = poolself.to_latent = nn.Identity()self.mlp_head = nn.Sequential( # CLS多分类输出部分nn.LayerNorm(dim),nn.Linear(dim, num_classes))def forward(self, img):# img: [1, 3, 224, 224] x = [1, 196, 1024]# 生成每张图片的Patch Embedding# 图片的每一个通道切分为Token + 将3个channel的所有Token拉直,拉到一个1维,长度为768的向量 + 接一个线性层映射到encoder需要的维度768->1024x = self.to_patch_embedding(img)b, n, _ = x.shape # b = 1 n = 196# 为每张图片生成一个Cls符号 [1, 1, 1024]cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b)# [1, 197, 1024] 将每张图片的Cls符号和Patch Embedding进行拼接x = torch.cat((cls_tokens, x), dim=1)# 初始化位置编码 再和(Cls和Patch Embedding)对应位置相加x += self.pos_embedding[:, :(n + 1)]# embedding后接一个Dropoutx = self.dropout(x)# 将最终的Embedding输入Encoder x: [1, 197, 1024] -> [1, 197, 1024]x = self.transformer(x)# self.pool = 'cls' 所以取第一个输出直接进行多分类 [1, 1024]x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]x = self.to_latent(x) # 恒等映射 [1, 1024]# Cls Head 多分类 [1, cls_num]return self.mlp_head(x)if __name__ == '__main__':v = ViT(image_size=224, # 输入图像的大小patch_size=16, # 每个token/patch的大小16x16num_classes=1000, # 多分类dim=1024, # encoder规定的输入的维度depth=6, # Encoder的个数heads=16, # 多头注意力机制的head个数mlp_dim=2048, # mlp的维度dropout=0.1, #emb_dropout=0.1 # embedding一半会接一个dropout)img = torch.randn(1, 3, 224, 224)preds = v(img) # (1, 1000)
以上参考:
Vision Transformer(ViT)PyTorch代码全解析(附图解) Vision Transformer——ViT代码解读
✨三、官方提供代码版本
官方代码:GitHub - google-research/vision_transformer
完整代码
"""
original code from rwightman:
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/vision_transformer.py
"""
from functools import partial
from collections import OrderedDictimport torch
import torch.nn as nndef drop_path(x, drop_prob: float = 0., training: bool = False):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).This is the same as the DropConnect impl I created for EfficientNet, etc networks, however,the original name is misleading as 'Drop Connect' is a different form of dropout in a separate paper...See discussion: https://github.com/tensorflow/tpu/issues/494#issuecomment-532968956 ... I've opted forchanging the layer and argument names to 'drop path' rather than mix DropConnect as a layer name and use'survival rate' as the argument."""if drop_prob == 0. or not training:return xkeep_prob = 1 - drop_probshape = (x.shape[0],) + (1,) * (x.ndim - 1) # work with diff dim tensors, not just 2D ConvNetsrandom_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)random_tensor.floor_() # binarizeoutput = x.div(keep_prob) * random_tensorreturn outputclass DropPath(nn.Module):"""Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks)."""def __init__(self, drop_prob=None):super(DropPath, self).__init__()self.drop_prob = drop_probdef forward(self, x):return drop_path(x, self.drop_prob, self.training)class PatchEmbed(nn.Module):"""2D Image to Patch Embedding"""def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None):super().__init__()img_size = (img_size, img_size)patch_size = (patch_size, patch_size)self.img_size = img_sizeself.patch_size = patch_sizeself.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1])self.num_patches = self.grid_size[0] * self.grid_size[1]self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size)self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity()def forward(self, x):B, C, H, W = x.shapeassert H == self.img_size[0] and W == self.img_size[1], \f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})."# flatten: [B, C, H, W] -> [B, C, HW]# transpose: [B, C, HW] -> [B, HW, C]x = self.proj(x).flatten(2).transpose(1, 2)x = self.norm(x)return xclass Attention(nn.Module):def __init__(self,dim, # 输入token的dimnum_heads=8,qkv_bias=False,qk_scale=None,attn_drop_ratio=0.,proj_drop_ratio=0.):super(Attention, self).__init__()self.num_heads = num_headshead_dim = dim // num_headsself.scale = qk_scale or head_dim ** -0.5self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)self.attn_drop = nn.Dropout(attn_drop_ratio)self.proj = nn.Linear(dim, dim)self.proj_drop = nn.Dropout(proj_drop_ratio)def forward(self, x):# [batch_size, num_patches + 1, total_embed_dim]B, N, C = x.shape# qkv(): -> [batch_size, num_patches + 1, 3 * total_embed_dim]# reshape: -> [batch_size, num_patches + 1, 3, num_heads, embed_dim_per_head]# permute: -> [3, batch_size, num_heads, num_patches + 1, embed_dim_per_head]qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)# [batch_size, num_heads, num_patches + 1, embed_dim_per_head]q, k, v = qkv[0], qkv[1], qkv[2] # make torchscript happy (cannot use tensor as tuple)# transpose: -> [batch_size, num_heads, embed_dim_per_head, num_patches + 1]# @: multiply -> [batch_size, num_heads, num_patches + 1, num_patches + 1]attn = (q @ k.transpose(-2, -1)) * self.scaleattn = attn.softmax(dim=-1)attn = self.attn_drop(attn)# @: multiply -> [batch_size, num_heads, num_patches + 1, embed_dim_per_head]# transpose: -> [batch_size, num_patches + 1, num_heads, embed_dim_per_head]# reshape: -> [batch_size, num_patches + 1, total_embed_dim]x = (attn @ v).transpose(1, 2).reshape(B, N, C)x = self.proj(x)x = self.proj_drop(x)return xclass Mlp(nn.Module):"""MLP as used in Vision Transformer, MLP-Mixer and related networks"""def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):super().__init__()out_features = out_features or in_featureshidden_features = hidden_features or in_featuresself.fc1 = nn.Linear(in_features, hidden_features)self.act = act_layer()self.fc2 = nn.Linear(hidden_features, out_features)self.drop = nn.Dropout(drop)def forward(self, x):x = self.fc1(x)x = self.act(x)x = self.drop(x)x = self.fc2(x)x = self.drop(x)return xclass Block(nn.Module):def __init__(self,dim,num_heads,mlp_ratio=4.,qkv_bias=False,qk_scale=None,drop_ratio=0.,attn_drop_ratio=0.,drop_path_ratio=0.,act_layer=nn.GELU,norm_layer=nn.LayerNorm):super(Block, self).__init__()self.norm1 = norm_layer(dim)self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio)# NOTE: drop path for stochastic depth, we shall see if this is better than dropout hereself.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity()self.norm2 = norm_layer(dim)mlp_hidden_dim = int(dim * mlp_ratio)self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop_ratio)def forward(self, x):x = x + self.drop_path(self.attn(self.norm1(x)))x = x + self.drop_path(self.mlp(self.norm2(x)))return xclass VisionTransformer(nn.Module):def __init__(self, img_size=224, patch_size=16, in_c=3, num_classes=1000,embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=True,qk_scale=None, representation_size=None, distilled=False, drop_ratio=0.,attn_drop_ratio=0., drop_path_ratio=0., embed_layer=PatchEmbed, norm_layer=None,act_layer=None):"""Args:img_size (int, tuple): input image sizepatch_size (int, tuple): patch sizein_c (int): number of input channelsnum_classes (int): number of classes for classification headembed_dim (int): embedding dimensiondepth (int): depth of transformernum_heads (int): number of attention headsmlp_ratio (int): ratio of mlp hidden dim to embedding dimqkv_bias (bool): enable bias for qkv if Trueqk_scale (float): override default qk scale of head_dim ** -0.5 if setrepresentation_size (Optional[int]): enable and set representation layer (pre-logits) to this value if setdistilled (bool): model includes a distillation token and head as in DeiT modelsdrop_ratio (float): dropout rateattn_drop_ratio (float): attention dropout ratedrop_path_ratio (float): stochastic depth rateembed_layer (nn.Module): patch embedding layernorm_layer: (nn.Module): normalization layer"""super(VisionTransformer, self).__init__()self.num_classes = num_classesself.num_features = self.embed_dim = embed_dim # num_features for consistency with other modelsself.num_tokens = 2 if distilled else 1norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)act_layer = act_layer or nn.GELUself.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_c=in_c, embed_dim=embed_dim)num_patches = self.patch_embed.num_patchesself.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else Noneself.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))self.pos_drop = nn.Dropout(p=drop_ratio)dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, depth)] # stochastic depth decay ruleself.blocks = nn.Sequential(*[Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i],norm_layer=norm_layer, act_layer=act_layer)for i in range(depth)])self.norm = norm_layer(embed_dim)# Representation layerif representation_size and not distilled:self.has_logits = Trueself.num_features = representation_sizeself.pre_logits = nn.Sequential(OrderedDict([("fc", nn.Linear(embed_dim, representation_size)),("act", nn.Tanh())]))else:self.has_logits = Falseself.pre_logits = nn.Identity()# Classifier head(s)self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()self.head_dist = Noneif distilled:self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity()# Weight initnn.init.trunc_normal_(self.pos_embed, std=0.02)if self.dist_token is not None:nn.init.trunc_normal_(self.dist_token, std=0.02)nn.init.trunc_normal_(self.cls_token, std=0.02)self.apply(_init_vit_weights)def forward_features(self, x):# [B, C, H, W] -> [B, num_patches, embed_dim]x = self.patch_embed(x) # [B, 196, 768]# [1, 1, 768] -> [B, 1, 768]cls_token = self.cls_token.expand(x.shape[0], -1, -1)if self.dist_token is None:x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]else:x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)x = self.pos_drop(x + self.pos_embed)x = self.blocks(x)x = self.norm(x)if self.dist_token is None:return self.pre_logits(x[:, 0])else:return x[:, 0], x[:, 1]def forward(self, x):x = self.forward_features(x)if self.head_dist is not None:x, x_dist = self.head(x[0]), self.head_dist(x[1])if self.training and not torch.jit.is_scripting():# during inference, return the average of both classifier predictionsreturn x, x_distelse:return (x + x_dist) / 2else:x = self.head(x)return xdef _init_vit_weights(m):"""ViT weight initialization:param m: module"""if isinstance(m, nn.Linear):nn.init.trunc_normal_(m.weight, std=.01)if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode="fan_out")if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, nn.LayerNorm):nn.init.zeros_(m.bias)nn.init.ones_(m.weight)def vit_base_patch16_224(num_classes: int = 1000):"""ViT-Base model (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:链接: https://pan.baidu.com/s/1zqb08naP0RPqqfSXfkB2EA 密码: eu9f"""model = VisionTransformer(img_size=224,patch_size=16,embed_dim=768,depth=12,num_heads=12,representation_size=None,num_classes=num_classes)return modeldef vit_base_patch16_224_in21k(num_classes: int = 21843, has_logits: bool = True):"""ViT-Base model (ViT-B/16) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_patch16_224_in21k-e5005f0a.pth"""model = VisionTransformer(img_size=224,patch_size=16,embed_dim=768,depth=12,num_heads=12,representation_size=768 if has_logits else None,num_classes=num_classes)return modeldef vit_base_patch32_224(num_classes: int = 1000):"""ViT-Base model (ViT-B/32) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:链接: https://pan.baidu.com/s/1hCv0U8pQomwAtHBYc4hmZg 密码: s5hl"""model = VisionTransformer(img_size=224,patch_size=32,embed_dim=768,depth=12,num_heads=12,representation_size=None,num_classes=num_classes)return modeldef vit_base_patch32_224_in21k(num_classes: int = 21843, has_logits: bool = True):"""ViT-Base model (ViT-B/32) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_base_patch32_224_in21k-8db57226.pth"""model = VisionTransformer(img_size=224,patch_size=32,embed_dim=768,depth=12,num_heads=12,representation_size=768 if has_logits else None,num_classes=num_classes)return modeldef vit_large_patch16_224(num_classes: int = 1000):"""ViT-Large model (ViT-L/16) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-1k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:链接: https://pan.baidu.com/s/1cxBgZJJ6qUWPSBNcE4TdRQ 密码: qqt8"""model = VisionTransformer(img_size=224,patch_size=16,embed_dim=1024,depth=24,num_heads=16,representation_size=None,num_classes=num_classes)return modeldef vit_large_patch16_224_in21k(num_classes: int = 21843, has_logits: bool = True):"""ViT-Large model (ViT-L/16) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_patch16_224_in21k-606da67d.pth"""model = VisionTransformer(img_size=224,patch_size=16,embed_dim=1024,depth=24,num_heads=16,representation_size=1024 if has_logits else None,num_classes=num_classes)return modeldef vit_large_patch32_224_in21k(num_classes: int = 21843, has_logits: bool = True):"""ViT-Large model (ViT-L/32) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.weights ported from official Google JAX impl:https://github.com/rwightman/pytorch-image-models/releases/download/v0.1-vitjx/jx_vit_large_patch32_224_in21k-9046d2e7.pth"""model = VisionTransformer(img_size=224,patch_size=32,embed_dim=1024,depth=24,num_heads=16,representation_size=1024 if has_logits else None,num_classes=num_classes)return modeldef vit_huge_patch14_224_in21k(num_classes: int = 21843, has_logits: bool = True):"""ViT-Huge model (ViT-H/14) from original paper (https://arxiv.org/abs/2010.11929).ImageNet-21k weights @ 224x224, source https://github.com/google-research/vision_transformer.NOTE: converted weights not currently available, too large for github release hosting."""model = VisionTransformer(img_size=224,patch_size=14,embed_dim=1280,depth=32,num_heads=16,representation_size=1280 if has_logits else None,num_classes=num_classes)return model比较不错的大佬解读:
CSDN:Vision Transformer(VIT)代码分析——保姆级教程
【深度学习】详解 Vision Transformer (ViT)
【计算机视觉】ViT:代码逐行解读
知乎:ViT源码阅读-PyTorch - 知乎 (zhihu.com)
全网最强ViT (Vision Transformer)原理及代码解析 - 知乎 (zhihu.com)
B站:【VIT (Vision Transformer) 模型论文+代码(源码)从零详细解读,看不懂来打我】
