双重差分模型学习笔记4(理论)
【DID最全总结】90分钟带你速通双重差分!_哔哩哔哩_bilibili
目录
总结:双重差分法(DID)在社会科学中的应用:理论、发展与前沿分析
一、DID的基本原理与核心思想
二、经典DID:标准模型与应用案例
三、交错DID(Staggered DID)与动态效应
四、DID的拓展与应用前沿
五、DID在论文中的应用架构
六、总结与展望
编辑
思维导图
一、引言
二、DID基本原理
三、标准DID(Standard DID)
四、交错DID(Staggered DID)
五、DID的拓展方法
六、DID的挑战与前沿
七、论文架构建议
八、总结
总结:双重差分法(DID)在社会科学中的应用:理论、发展与前沿分析
一、DID的基本原理与核心思想
-
因果识别需求
双重差分法(Difference-in-Differences, DID)的核心目标是识别因果关系,而非相关关系。在政策评估中,需明确政策干预(如最低工资调整、运河关闭)对结果变量(就业率、叛乱数量)的净效应,避免混淆因素干扰。
-
单重差分的局限性
-
截面比较:仅对比同一时点处理组与对照组的差异,但无法排除组间固有差异。
-
时间序列比较:仅对比处理组政策前后的变化,但忽略其他时间相关因素(如经济周期)。
-
DID的改进:通过两次差分(组间差异和时间差异)控制不可观测的固定效应,更干净地识别因果效应。
-
-
平行趋势假设
-
核心假设:若处理组未受干预,其变化趋势应与对照组平行。
-
检验方法:通过事件研究法(Event Study)验证政策前处理组与对照组的趋势是否一致。若政策前系数不显著,则假设成立。
-
二、经典DID:标准模型与应用案例
-
标准DID模型
-
:处理组虚拟变量(1=受政策影响,0=未影响)。
-
:时间虚拟变量(1=政策后,0=政策前)。
-
交互项系数(
)为平均处理效应(ATE)。
-
-
经典案例:最低工资对就业的影响(Card & Krueger, 1994)
-
政策背景:1992年新泽西州提高最低工资,宾夕法尼亚州未调整。
-
DID设计:对比两州快餐店就业变化,发现最低工资提升未显著减少就业。
-
局限性:样本量小,未控制双向固定效应,平行趋势检验不足。
-
-
双向固定效应模型(TWFE)的改进
-
控制个体固定效应
和时间固定效应
,缓解遗漏变量问题。
-
案例:大运河关闭对叛乱的影响(2020年AER),通过面板数据与TWFE模型验证政策效应。
-
三、交错DID(Staggered DID)与动态效应
-
多时点政策的应用
-
现实背景:政策常分批次实施(如中国改革开放试点)。
-
模型调整:将绝对时间转化为相对时间(
),允许不同个体在不同时点进入处理组。
-
-
动态DID与事件研究法
-
动态效应检验:估计政策实施前后各期的处理效应,验证效应持续性。
-
案例:通商口岸的长期经济影响(贾瑞雪)
-
分四批开放口岸,利用相对时间模型和事件研究法,显示通商促进人口增长与经济发展。
-
平行趋势检验:政策前系数不显著,支持假设。
-
-
-
交错DID的挑战
-
处理效应异质性:不同批次政策效应可能不同,TWFE模型隐含同质性假设,导致估计偏误。
-
解决方案:前沿估计量(如Sun & Abraham的队列加权法、Callaway & Sant’Anna的插补法)缓解偏误。
-
四、DID的拓展与应用前沿
-
广义DID(Generalized DID)
-
处理强度差异:政策影响程度因个体而异(如不同地区受运河关闭冲击不同)。
-
模型引入处理强度变量,增强灵活性。
-
-
队列DID(Cohort DID)
-
截面数据应用:通过出生队列或历史事件队列构造“准面板”。
-
案例:知青下乡对农村教育的影响(周黎安)
- 利用截面数据中不同出生队列受政策影响的差异,识别知青对农村人力资本的提升效应。
-
-
合成控制法(SCM)
-
无自然对照组的替代方案:通过加权构造“合成控制组”(如评估单一国家政策)。
-
案例:加州烟草税改革的影响,合成未改革州的对照。
-
五、DID在论文中的应用架构
-
标准分析框架
-
基准回归:报告TWFE模型的核心系数及显著性。
-
平行趋势检验:通过事件研究图展示政策前趋势。
-
稳健性检验:更换估计量、控制变量、样本范围等。
-
-
前沿方法的应用
-
异质性处理效应:使用Sun & Abraham或Callaway & Sant’Anna方法。
-
绘图展示:将传统TWFE与前沿估计量结果对比,增强结果可信度。
-
六、总结与展望
-
DID的优势与局限
-
优势:直观、易实现、控制固定效应。
-
局限:依赖平行趋势假设,处理效应异质性可能导致偏误。
-
-
未来方向
-
更灵活的估计量:如异质性时间效应模型、机器学习结合DID。
-
数据创新:结合大数据与历史数据,扩展DID在复杂政策评估中的应用。
-
参考文献
-
Card, D., & Krueger, A. B. (1994). Minimum Wages and Employment. AER.
-
Huang, W. (2020). 从双重差分法到事件研究法.
-
Jia, R. (2013). The Legacies of Forced Freedom: China’s Treaty Ports. REStat.
-
Goodman-Bacon, A. (2021). Difference-in-Differences with Variation in Treatment Timing. JBES.
本报告系统梳理了DID的理论基础、经典应用、多时点政策分析及前沿进展,结合实例展示了方法的核心思想与实操要点,为政策评估研究提供了方法论参考。
AI对视频的总结

思维导图
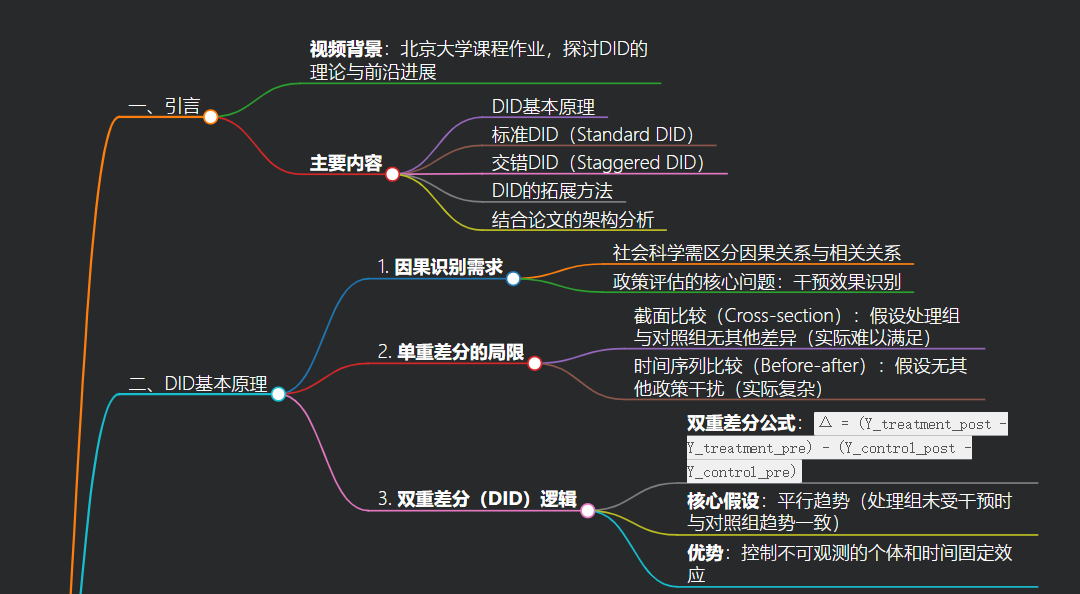
一、引言
- 视频背景:北京大学课程作业,探讨DID的理论与前沿进展
- 主要内容
- DID基本原理
- 标准DID(Standard DID)
- 交错DID(Staggered DID)
- DID的拓展方法
- 结合论文的架构分析
二、DID基本原理
- 因果识别需求
- 社会科学需区分因果关系与相关关系
- 政策评估的核心问题:干预效果识别
- 单重差分的局限
- 截面比较(Cross-section):假设处理组与对照组无其他差异(实际难以满足)
- 时间序列比较(Before-after):假设无其他政策干扰(实际复杂)
- 双重差分(DID)逻辑
- 双重差分公式:
Δ = (Y_treatment_post - Y_treatment_pre) - (Y_control_post - Y_control_pre) - 核心假设:平行趋势(处理组未受干预时与对照组趋势一致)
- 优势:控制不可观测的个体和时间固定效应
- 双重差分公式:
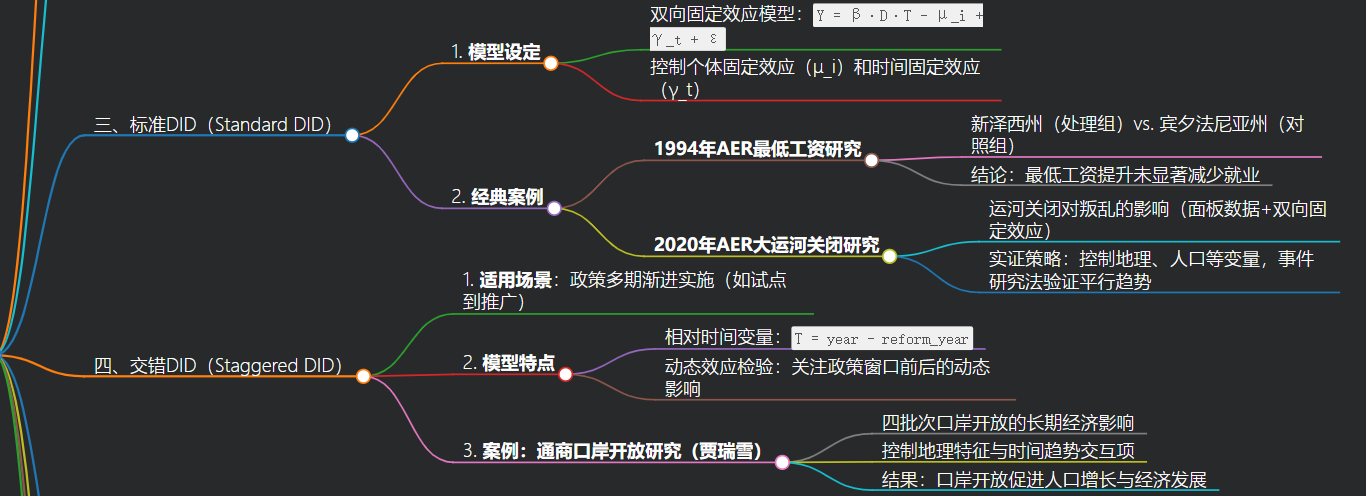
三、标准DID(Standard DID)
- 模型设定
- 双向固定效应模型:
Y = β·D·T - μ_i + γ_t + ε - 控制个体固定效应(μ_i)和时间固定效应(γ_t)
- 双向固定效应模型:
- 经典案例
- 1994年AER最低工资研究
- 新泽西州(处理组)vs. 宾夕法尼亚州(对照组)
- 结论:最低工资提升未显著减少就业
- 2020年AER大运河关闭研究
- 运河关闭对叛乱的影响(面板数据+双向固定效应)
- 实证策略:控制地理、人口等变量,事件研究法验证平行趋势
- 1994年AER最低工资研究
四、交错DID(Staggered DID)
- 适用场景:政策多期渐进实施(如试点到推广)
- 模型特点
- 相对时间变量:
T = year - reform_year - 动态效应检验:关注政策窗口前后的动态影响
- 相对时间变量:
- 案例:通商口岸开放研究(贾瑞雪)
- 四批次口岸开放的长期经济影响
- 控制地理特征与时间趋势交互项
- 结果:口岸开放促进人口增长与经济发展
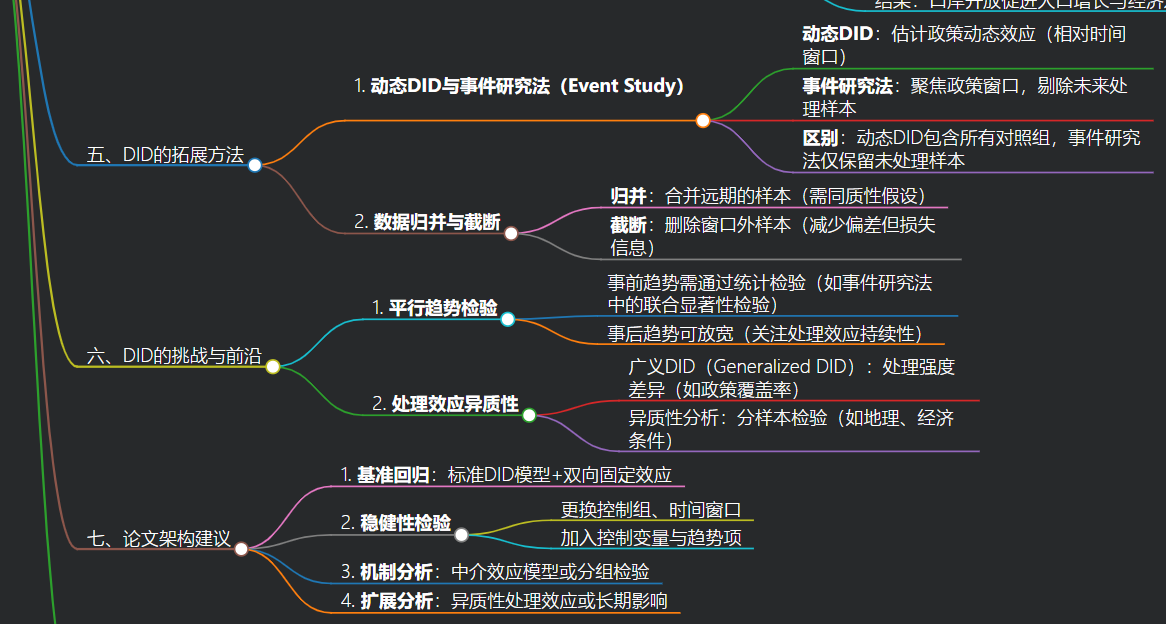
五、DID的拓展方法
- 动态DID与事件研究法(Event Study)
- 动态DID:估计政策动态效应(相对时间窗口)
- 事件研究法:聚焦政策窗口,剔除未来处理样本
- 区别:动态DID包含所有对照组,事件研究法仅保留未处理样本
- 数据归并与截断
- 归并:合并远期的样本(需同质性假设)
- 截断:删除窗口外样本(减少偏差但损失信息)
六、DID的挑战与前沿
- 平行趋势检验
- 事前趋势需通过统计检验(如事件研究法中的联合显著性检验)
- 事后趋势可放宽(关注处理效应持续性)
- 处理效应异质性
- 广义DID(Generalized DID):处理强度差异(如政策覆盖率)
- 异质性分析:分样本检验(如地理、经济条件)
七、论文架构建议
- 基准回归:标准DID模型+双向固定效应
- 稳健性检验
- 更换控制组、时间窗口
- 加入控制变量与趋势项
- 机制分析:中介效应模型或分组检验
- 扩展分析:异质性处理效应或长期影响
八、总结
- DID优势:因果识别强、适用面板数据、可检验平行趋势
- 局限:依赖平行趋势假设、政策冲击外生性要求高
- 前沿方向:交错DID的估计方法改进、大数据下的动态效应分析