Spark(32)SparkSQL操作Mysql
(一)准备mysql环境
我们计划在hadoop001这台设备上安装mysql服务器,(当然也可以重新使用一台全新的虚拟机)。
以下是具体步骤:
- 使用finalshell连接hadoop001.
- 查看是否已安装MySQL。命令是: rpm -qa|grep mariadb
若已安装,需要先做卸载MySQL的操作命令是:rpm -e --nodeps mariadb-libs
3,把mysql的安装包上传到虚拟机。
4. 进入/opt/software/目录,解压上传的.tar文件。
cd /opt/software
解压文件
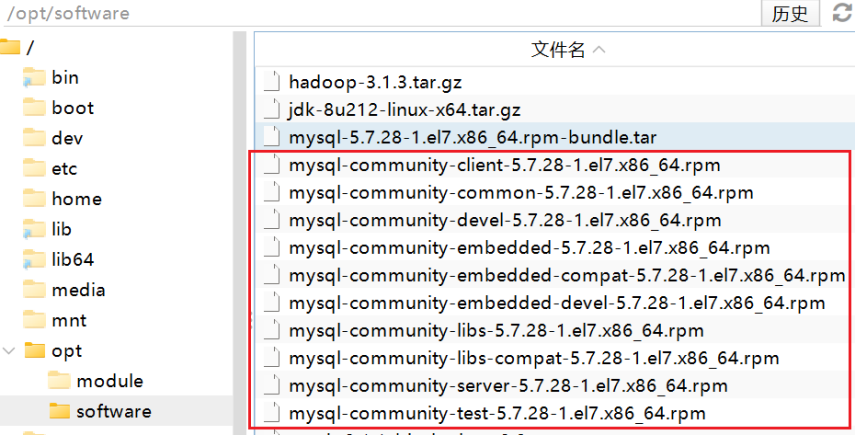
tar -xf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar得到的效果如下
- 安装工具包
yum install -y perl perl-Data-Dumper perl-Digest-MD5 net-tools libaio
如果安装成功,或者显示以下内容,即可继续安装步骤:
软件包 libaio-0.3.109-13.el7.x86_64 已安装并且是最新版本
无须任何处理
6.安装mysql。依次输入以下5条命令:
rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm
命令说明:
rpm -ivh 是 Linux 中用于安装 RPM(Red Hat Package Manager)软件包的命令。具体来说,rpm -ivh 中的每个选项都有特定的含义:
rpm:RPM 包管理工具,用于安装、查询、验证、更新和删除软件包。
-i:表示安装(install)软件包。
-v:表示显示详细(verbose)信息,提供更多安装过程中的输出信息。
-h:表示在安装过程中显示进度条,以 # 符号表示安装进度。
- 初始化数据库
使用的命令是: mysqld --initialize --user=mysql
- 查看临时密码
安装完成之后,它会在一个日志文件中保存临时密码,通过cat命令来查看这个密码。具体的操作是:cat /var/log/mysqld.log
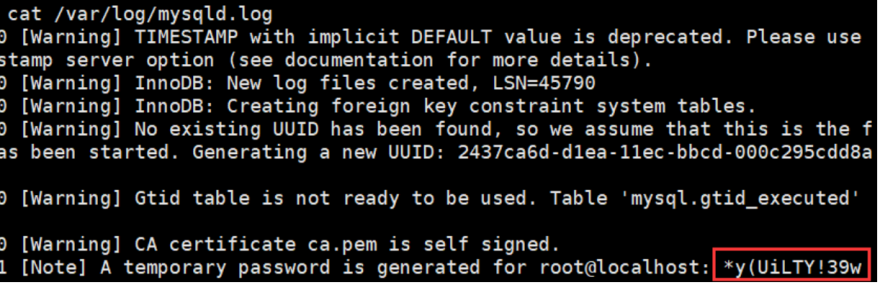
将临时密码复制,或者暂时存到某处
- 启动MySQL服务。对应的命令是:systemctl start mysqld
- 登录MySQL数据库。对应的命令是:mysql -uroot -p
- 输入临时密码。此时会要求输入密码。
Enter password: 临时密码。注意,在输入密码的过程中,密码并不可见。
4.登陆成功后,修改密码为123456。初始密码太难记了,我们先修改一下密码。
对应的命令如下:
mysql> set password = password("123456");
5.使root允许任意ip连接
mysql> update mysql.user set host='%' where user='root';
mysql> flush privileges;
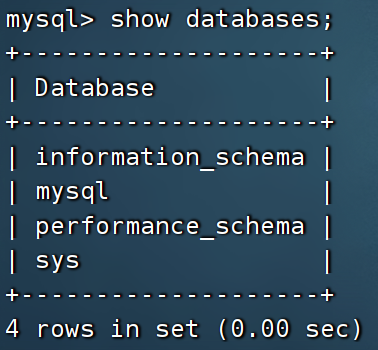
6.查看已有的数据库。通过命令:show databases;
(二)创建数据库和表
接下来,我们去创建一个新的数据库,数据表,并插入一条数据。
参考代码如下:
-- 创建数据库
CREATE DATABASE spark;
-- 使用数据库
USE spark;
-- 创建表
create table person(id int, name char(20), age int);
-- 插入示例数据
insert into person values(1, 'jam', 20), (2,'judi', 21);
-- 查看所有数据
select * from person;
-- 退出
quit
提醒:use spark;的作用是使用当前数据库;
(三)Spark连接MySQL数据库
- 新建项目,或者使用之前的项目也可以。
- 修改pom.xml文件。
【强调:可以删除spark-core这个包】
补充三个依赖:
(1)scala-library 是 Scala 语言的基础库,是编写 Scala 程序的必要条件。
(2)spark-sql_2.12 提供了 Spark SQL 的功能,用于高效的数据处理和分析。
(3)mysql-connector-java 提供了与 MySQL 数据库交互的能力。
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.15</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.3.1</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.33</version>
</dependency>
请注意,这里并没没有单独添加spark_core的依赖,因为在spark-sql中已经包含了spark_core。写Spark程序连接mysql
核心步骤:
- 创建Properties对象,设置数据库的用户名和密码
- 使用spark.read.jbdc方法,连接数据库
参考代码如下:
impport org.apache.spark.sql.SparkSession
import java.util.Properties
object SparkMySQL {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("SparkMySQL").master("local[*]").getOrCreate()
// 创建properties对象,设置连接mysql的用户名和密码
val prop = new Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "000000")
// 读取mysql数据
val df = spark.read.jdbc("jdbc:mysql://hadoop100:3306/spark", "person", prop)
df.show()
spark.stop()
}
(四)Spark添加数据到mysql
前面演示了数据的查询,现在来看看添加数据到mysql。
【演示】
核心方法:dataFrame.write.mode("append").jdbc()。
import org.apache.spark.sql.SparkSession
import java.util.Properties
object SparkMySQL {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().appName("SparkMySQL").master("local[*]").getOrCreate()
// 创建properties对象,设置连接mysql的用户名和密码
val prop = new Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "000000")
// 插入一条数据到数据库
val data = Seq(("3", "zhangsan", "30"))
val df2 = spark.createDataFrame(data).toDF("id", "name", "age")
df2.write.mode("append").jdbc("jdbc:mysql://hadoop100:3306/spark", "person", prop)
}
}
上面的代码运行完成之后,切换到finalshell中的mysql端,查看效果。