大数据课程D5——hadoop的Sink
文章作者邮箱:yugongshiye@sina.cn 地址:广东惠州
▲ 本章节目的
⚪ 掌握Sink的HDFS Sink;
⚪ 掌握Sink的Logger Sink;
⚪ 掌握Sink的File Roll Sink;
⚪ 掌握Sink的Null Sink;
⚪ 掌握Sink的AVRO Sink;
⚪ 掌握Sink的Custom Sink;
一、HDFS Sink
1. 概述
1. HDFS Sink将收集到的数据写到HDFS中。
2. 在往HDFS上写的时候,支持三种文件类型:文本类型,序列类型以及压缩类型。如果不指定,那么默认使用使得序列类型。
3. 在往HDFS上写数据的时候,数据的存储文件会定时的滚动,如果不指定,那么每隔30s会滚动一次,生成一个文件,那么此时会生成大量的小文件。
2. 配置属性
| 属性 | 解释 |
| type | 必须是hdfs |
| hdfs.path | 数据在HDFS上的存储路径 |
| hdfs.rollInterval | 指定文件的滚动的间隔时间 |
| hdfs.fileType | 指定文件的存储类型:DataSteam(文本),SequenceFile(序列),CompressedStream(压缩) |
3. 案例
1. 编写格式文件,添加如下内容:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = netcat
a1.sources.s1.bind = hadoop01
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
# 配置HDFS Sink
# 类型必须是hdfs
a1.sinks.k1.type = hdfs
# 指定数据在HDFS上的存储路径
a1.sinks.k1.hdfs.path = hdfs://hadoop01:9000/flumedata
# 指定文件的存储类型
a1.sinks.k1.hdfs.fileType = DataStream
# 指定文件滚动的间隔时间
a1.sinks.k1.hdfs.rollInterval = 3600
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
2. 启动Flume:
../bin/flume-ng agent -n a1 -c ../conf -f hdfssink.conf -
Dflume.root.logger=INFO,console
二、Logger Sink
1. 概述
1. Logger Sink是将Flume收集到的数据打印到控制台上。
2. 在打印的时候,为了防止过多的数据将屏幕占满,所以要求body部分的数据不能超过16个字节,超过的部分不打印。
3. Logger Sink在打印的时候,对中文支持不好。
2. 配置属性
| 属性 | 解释 |
| type | 必须是logger |
| maxBytesToLog | 指定body部分打印的字节数 |
三、File Roll Sink
1. 概述
1. File Roll Sink将数据写到本地磁盘上。
2. 同HDFS Sink类似,File Roll Sink在往磁盘上写的时候,也有一个滚动的间隔时间,同样是30s,因此在磁盘上同样会形成大量的小文件。
2. 配置属性
| 属性 | 解释 |
| type | 必须是file_roll |
| sink.directory | 指定数据的存储目录 |
| sink.rollInterval | 指定文件滚动的间隔时间 |
3. 案例
1. 编写格式文件,添加如下内容:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = netcat
a1.sources.s1.bind = hadoop01
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
# 配置File Roll Sink
# 类型必须是file_roll
a1.sinks.k1.type = file_roll
# 指定数据在磁盘上的存储目录
a1.sinks.k1.sink.directory = /home/flumedata
# 指定文件的滚动间隔时间
a1.sinks.k1.sink.rollInterval = 3600
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
2. 启动Flume:
../bin/flume-ng agent -n a1 -c ../conf -f filerollsink.conf -
Dflume.root.logger=INFO,console
四、Null Sink
1. 概述
1. Null Sink会抛弃所有接收到的数据。
2. 配置属性
| 属性 | 解释 |
| type | 必须是null |
3. 案例
1. 编写格式文件,添加如下内容:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = netcat
a1.sources.s1.bind = hadoop01
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
# 配置Null Sink
# 类型必须是null
a1.sinks.k1.type = null
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1f
2. 启动Flume:
../bin/flume-ng agent -n a1 -c ../conf -f nullsink.conf -
Dflume.root.logger=INFO,console
五、AVRO Sink
1. 概述
1. AVRO Sink会将数据利用AVRO序列化之后写出到指定的节点的指定端口。
2. AVRO Sink结合AVRO Source实现多级、扇入、扇出流动效果。
2. 配置属性
| 属性 | 解释 |
| type | 必须是avro |
| hostname | 数据要发往的主机的主机名或者IP |
| port | 数据要发往的主机的接收端口 |
3. 多级流动
1. 第一个节点:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = netcat
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
# 配置多级流动
# 类型必须是avro
a1.sinks.k1.type = avro
# 指定主机名或者IP
a1.sinks.k1.hostname = hadoop02
# 指定端口
a1.sinks.k1.port = 8090
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
2. 第二个节点:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = avro
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
# 配置多级流动
# 类型必须是avro
a1.sinks.k1.type = avro
# 指定主机名或者IP
a1.sinks.k1.hostname = hadoop03
# 指定端口
a1.sinks.k1.port = 8090
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
3. 第三个节点:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = avro
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
a1.sinks.k1.type = logger
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
4. 启动Flume,启动的时候,谁接收数据,就先启动谁:
../bin/flume-ng agent -n a1 -c ../conf -f duoji.conf -
Dflume.root.logger=INFO,console
4. 扇入流动
1. 第一个和第二个节点:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = netcat
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
# 配置多级流动
# 类型必须是avro
a1.sinks.k1.type = avro
# 指定主机名或者IP
a1.sinks.k1.hostname = hadoop03
# 指定端口
a1.sinks.k1.port = 8090
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
2. 第三个节点:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = avro
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
a1.sinks.k1.type = logger
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
3. 启动Flume:
../bin/flume-ng agent -n a1 -c ../conf -f shanru.conf -
Dflume.root.logger=INFO,console
5. 扇出流动
1. 第一个节点:
a1.sources = s1
a1.channels = c1 c2
a1.sinks = k1 k2
a1.sources.s1.type = netcat
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
a1.channels.c2.type = memory
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = hadoop02
a1.sinks.k1.port = 8090
a1.sinks.k2.type = avro
a1.sinks.k2.hostname = hadoop03
a1.sinks.k2.port = 8090
a1.sources.s1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2
2. 第二个和第三个节点::
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = avro
a1.sources.s1.bind = 0.0.0.0
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
a1.sinks.k1.type = logger
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
3. 启动Flume:
../bin/flume-ng agent -n a1 -c ../conf -f shanchu.conf -
Dflume.root.logger=INFO,console
六、Custom Sink
1. 概述
1. 定义一个类实现Sink接口,考虑到需要获取配置属性,所以同样需要实现Configurable接口。
2. 不同于自定义Source,自定Sink需要考虑事务问题。
2. 事务
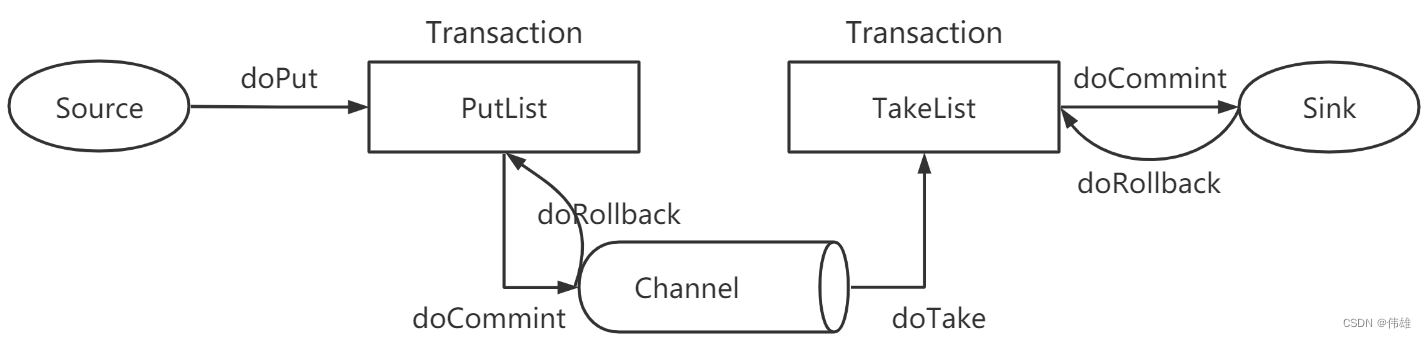
1. Source收集到数据之后,会通过doPut操作将树放到队列PutList(本质上是一个阻塞式队列)中。
2. PutList会试图将数据推送到Channel中。如果PutList成功将数据放到了Channel中,那么执行doCommit操作;反之执行doRollback操作。
3. Channel有了数据之后,会将数据通过doTake操作推送到TakeList中。
4. TakeList会将数据推送给Sink,如果Sink写出成功,那么执行doCommit;反之执行doRollvack。
3. 自定义Sink步骤
1. 构建Maven工程,导入对应的POM依赖。
2. 定义一个类继承AbstractSink,实现Sink接口和Configurable接口,覆盖configure,start,process和stop方法。
3. 完成之后打成jar包放到Flume安装目录的lib目录下。
4. 编写格式文件:
a1.sources = s1
a1.channels = c1
a1.sinks = k1
a1.sources.s1.type = netcat
a1.sources.s1.bind = hadoop01
a1.sources.s1.port = 8090
a1.channels.c1.type = memory
# 配置自定义Sink
# 类型必须是类的全路径名
a1.sinks.k1.type = cn.tedu.flume.sink.AuthSink
# 指定文件的存储路径
a1.sinks.k1.path = /home/flumedata
a1.sources.s1.channels = c1
a1.sinks.k1.channel = c1
5. 启动Flume:
../bin/flume-ng agent -n a1 -c ../conf -f authsink.conf -
Dflume.root.logger=INFO,console