GPT-3(Language Models are Few-shot Learners)简介
GPT-3(Language Models are Few-shot Learners)
一、GPT-2
1. 网络架构:
GPT系列的网络架构是Transformer的Decoder,有关Transformer的Decoder的内容可以看我之前的文章。
简单来说,就是利用Masked multi-head attention来提取文本信息,之后利用MLP和softmax来预测当前序列后应该接什么字符,以此来生成长的文本。注意:与传统的softmax不同,GPT会根据生成字符的概率,随机在概率高的几个字符中进行挑选,这就保证了同一个问题每次的回答都不相同。
对于不同版本的GPT的架构,无非就是在Decoder的基础上提高Masked multi-head attention layer的”多头“数与层数来增大模型的参数量以提高模型的拟合能力。
2. 核心思想:
使用无监督的预训练模型做有监督的任务。
作者认为,当一个语言模型的容量足够大时,它就足以覆盖所有的有监督任务,也就是说所有的有监督学习都是无监督语言模型的一个子集。这一点在之后的chatGPT中得到了很好的体现。
简单理解就是,在大量的训练样本中肯定存在某些样本是关于英语到法语翻译的。在训练完GPT-2后,模型本身已经凭借海量的训练数据学会了英语到法语的翻译,这时只要向模型发出”英语翻译成法语“这个任务指令,模型就可以进行翻译任务而不需要对模型进行微调。这便有了GPT-3中"In-context learning"的雏形。
3. 总结:
GPT-2最大的贡献是提出了通过海量的数据进行大规模的无监督训练,可以使模型直接完成下游任务而不需要对模型本身进行任何调整。在不少语言模型任务中仅仅通过向GPT-2”发出指令“,模型就有良好的性能。但是,很多实验表明,GPT-2的无监督学习还远没有头达到瓶颈,这就诞生了模型更大、数据集更”海量“的GPT-3。
二、GPT-3—力大砖飞
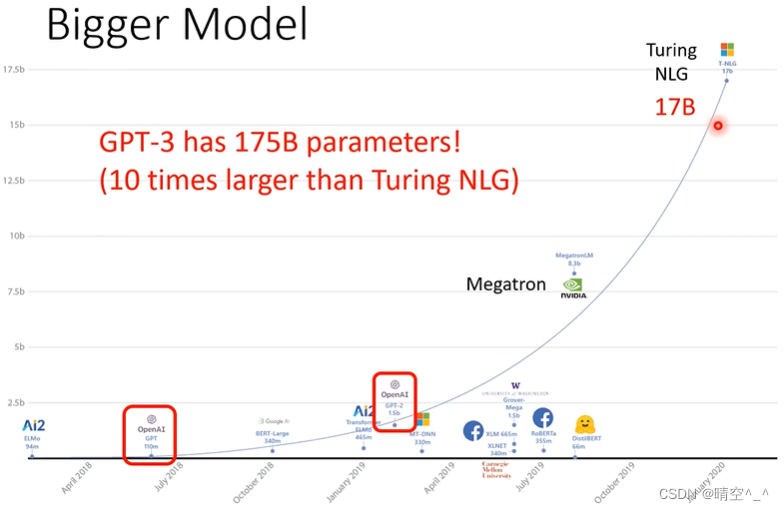
GPT-3的模型非常巨大,如图,GPT-1的模型大小为第一个红色矩形,GPT-2的模型大小为第二个红色矩形,而GPT-3的模型大小为175B的参数。对一般实验室来说训练是不可能的。
三、zero-shot / few-shot learning
1. 预训练—微调
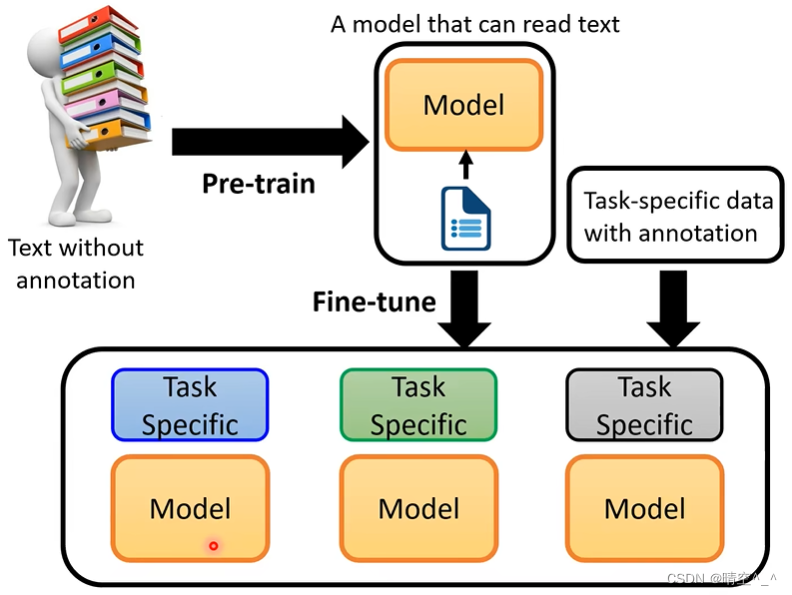
如图,对于普通的NLP模型如BERT和GPT-1,模型的使用方法是:
- 对成熟的NLP模型进行有监督的预训练。
- 根据特定的下游任务(文本分类、问答等)对当前NLP添加MLP。
- 根据特性下游任务的数据集对整个模型进行微调。
2. “In-context” learning
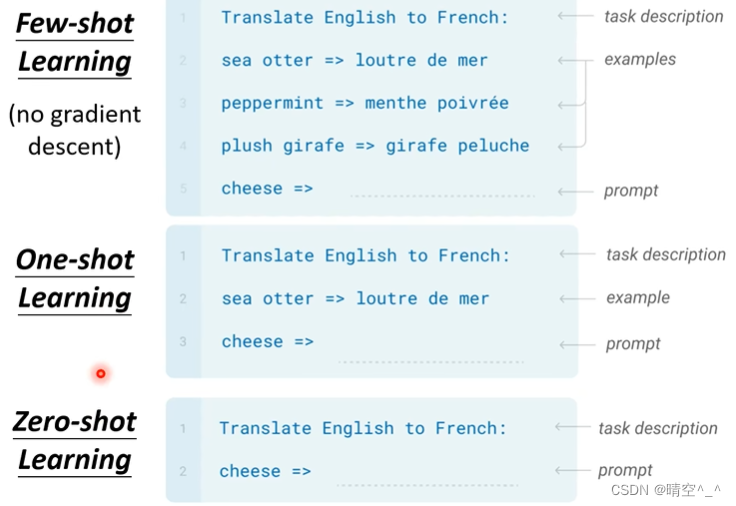
GPT-3采用"In-context" learning来完成特定的下游任务。简单来说,用户通过对话向GPT-3发出任务描述,GPT-3在”理解“用户的任务后直接就可以完成任务而无需对模型进行微调。整个过程都是在与用户的对话中完成的,模型本身没有任何改变。
如图,
-
给GPT进行任务说明,如图为:Translate English to French.
-
few-shot learning中,给GPT不止一个样例,在one-shot learning中,给GPT一个样例,在zero-shot learning中,不给GPT样例。样例是在对话框中由用户直接给出的。
注意:在此过程中,GPT不进行梯度下降(无fine tune)。直观的理解就是GPT理解了你发出的任务的目的而不是对GPT本身进行模型优化。
-
输入一个英文单词,之后输入一个
=>。该符号的意思是:符号前的内容是我输入的,符号后的内容是GPT输出的。
3. 总结:
GPT的1、2和3系列都是采用Transformer的Decoder架构,在模型结构上没有新意,但是凭借微软平台的支持,其可以对普通人无法想象的巨大模型与海量的训练数据进行训练从而产生令人惊叹的效果。甚至在训练GPT-3时出现了一个bug,OpenAI自己也没有资金重新训练了。
但是,GPT-3也不是万能的,其在一些任务上也存在不少问题,这就催生了InstructGPT和最近爆火的ChatGPT。