elasticsearch使用记录
参考文章:https://elasticsearch-py.readthedocs.io/en/v8.8.2/
参考文章:https://cuiqingcai.com/6214.html
参考文章:https://www.cnblogs.com/cupleo/p/13953890.html
elasticsearch版本:8.8.2(软件包发行版)
python版本:3.10
目录
- 导入包
- 测试是否连接成功
- 测试数据
- 创建删除index
- 插入数据
- 查询数据
- 模糊搜索
- 精确搜索-使用keyword索引
- 精确搜索-多个词语
- 精确搜索-非中文可以直接使用
- 精确搜索-多列匹配
- id查询
- 更新数据
- 删除数据
- 简易封装
导入包
from elasticsearch import Elasticsearches = Elasticsearch(hosts=["https://192.168.1.1:9200"],basic_auth=['elastic', '123456'],verify_certs=False)
测试是否连接成功
>>> es.ping()
True
>>> es.info()
{ 'name' : 'qhdata-dev',
'cluster_name' : 'elasticsearch',
'cluster_uuid' : 'un55kUpqQ9iFGEfp5UUQ5g',
'version' : { 'number' : '8.8.2',
'build_flavor' : 'default',
'build_type' : 'deb',
'build_hash' : '98e1271edf932a480e4262a471281f1ee295ce6b',
'build_date' : '2023-06-26T05:16:16.196344851Z',
'build_snapshot' : FALSE,
'lucene_version' : '9.6.0',
'minimum_wire_compatibility_version' : '7.17.0',
'minimum_index_compatibility_version' : '7.0.0' },
'tagline' : 'You Know, for Search' }
测试数据
doc = [
{'org_id': 'qh0000016598985','org_name': '山东京博石油化工有限公司', # 精确搜索使用的字段'org_code': '167154095','org_usc_code': '913716251671540959'
},
{'org_id': 'qh0000017998348','org_name': '山东天宏新能源化工有限公司', # 精确搜索使用的字段'org_code': '670528461','org_usc_code': '913716256705284610'
},
{'org_id': 'qh0000017996506','org_name': '山东昆仑京博能源有限公司', # 精确搜索使用的字段'org_code': '577790166','org_usc_code': '913716255777901660'
},
{'org_id': 'qh0000018265983','org_name': '诺力昂化学品(博兴)有限公司', # 精确搜索使用的字段'org_code': '720705287','org_usc_code': '913716007207052873'
},
]
创建删除index
es_index = 'test_org_id'
es.indices.delete(index=es_index, ignore=[400, 404]) # 删除 Index
es.indices.create(index=es_index, ignore=400) # 创建 Index
es.indices.refresh()
# https://discuss.elastic.co/t/failed-to-parse-value-analyzed-as-only-true-or-false-are-allowed-es-upgrade-5-5-6-5/166473/2
mapping = {'properties': {'org_name': {'type': 'text','analyzer': 'ik_max_word', # 模糊搜索分析器'search_analyzer': 'ik_max_word',"fields": {"keyword": {"type": "keyword", # 相当于额外一重索引,类型为keyword,为精确搜索"ignore_above": 256 # 最多256个字符}}},'org_id': {'type': 'keyword', # 强行锁定仅进行精确搜索},}
}
es.indices.put_mapping(index=es_index, body=mapping)
创建好的效果
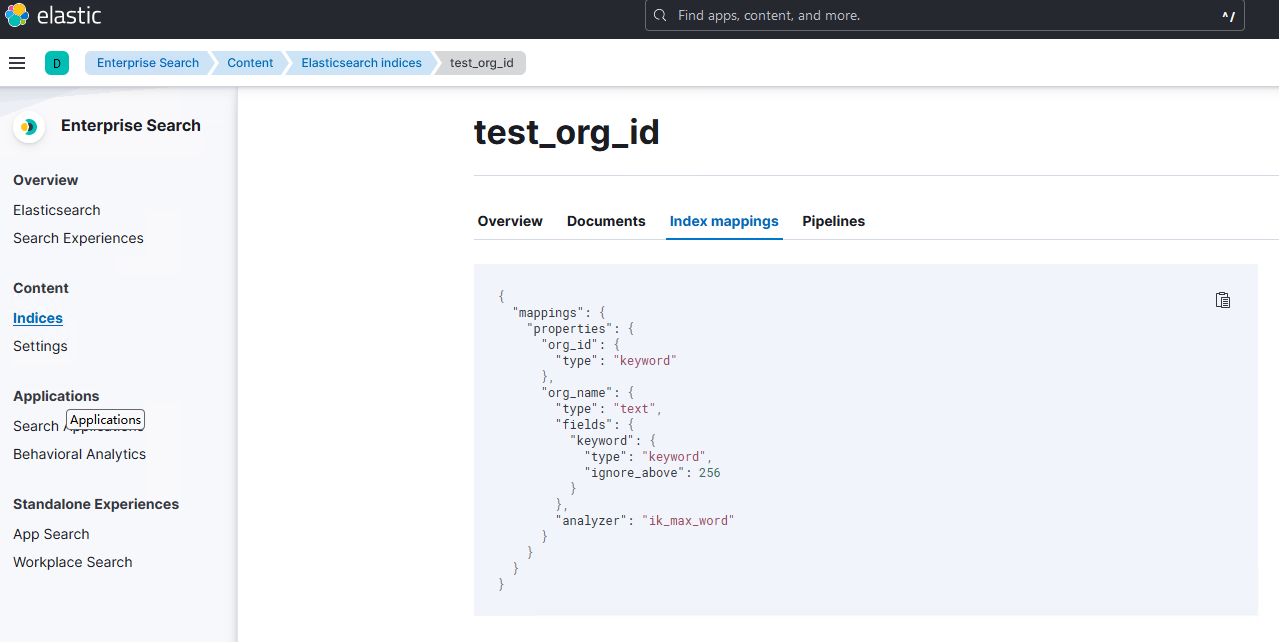
插入数据
for i in doc:es.index(index=es_index, document=i) # 自动随机生成唯一id,或者指定id
插入好的效果
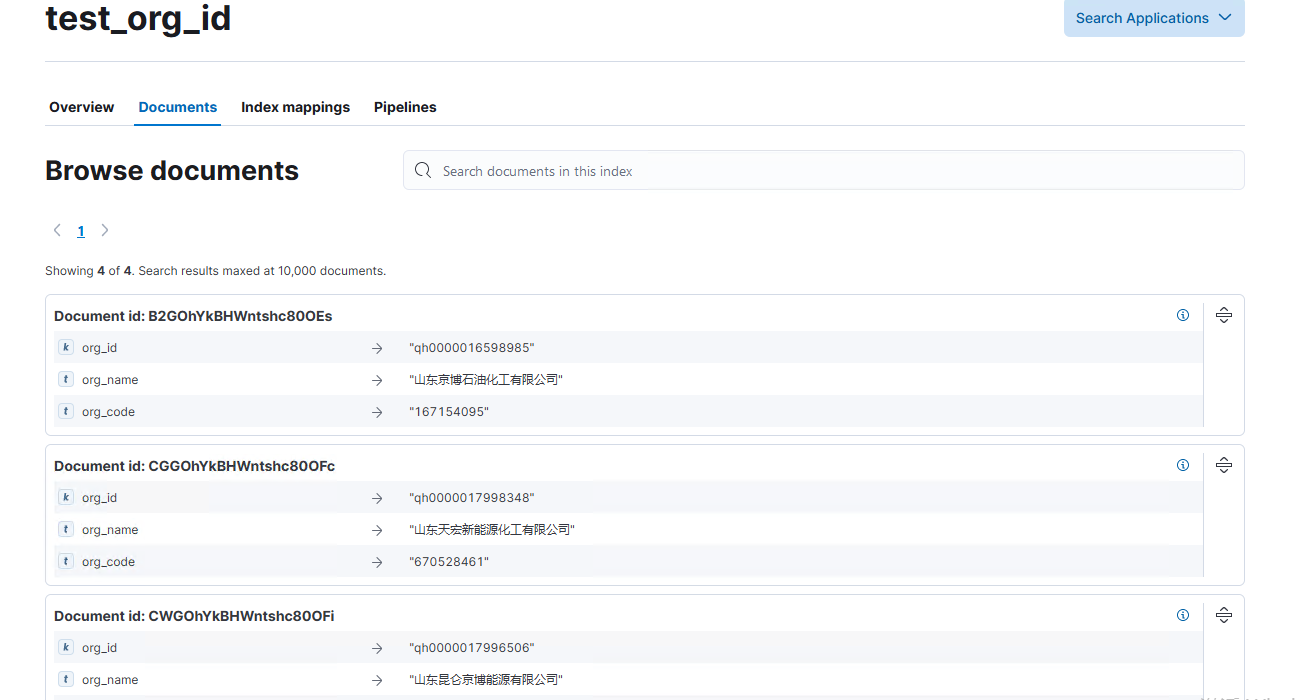
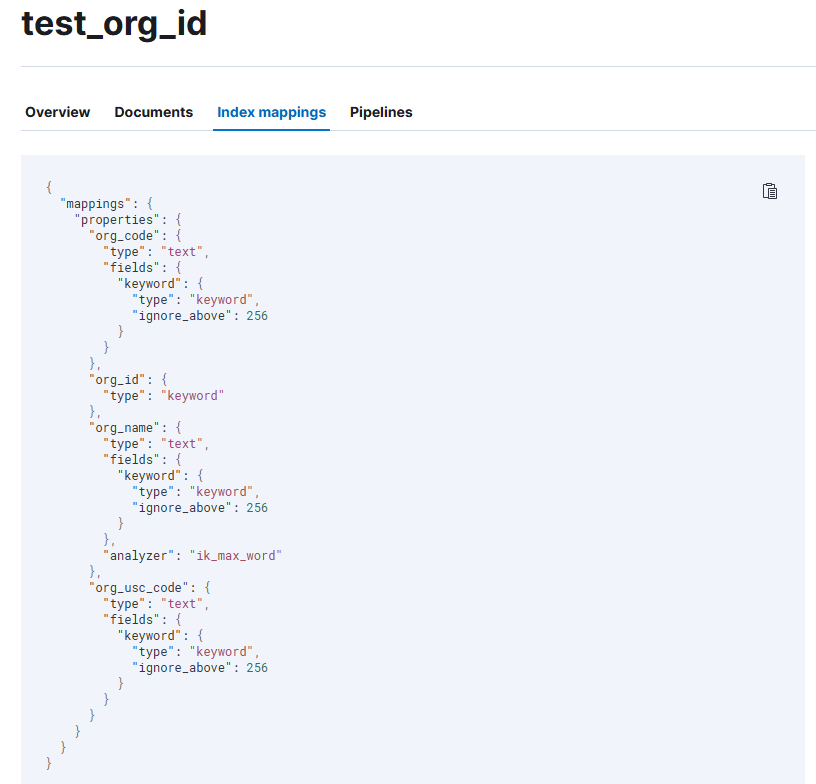
查询数据
参考文章:https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-get.html
模糊搜索
>>> es.search(index=es_index, query={"match": {'org_name': '山东'}}) # 模糊搜索
ObjectApiResponse ({ 'took' : 1,'timed_out' : FALSE,'_shards' : { 'total' : 1, 'successful' : 1, 'skipped' : 0, 'failed' : 0 },'hits' : { 'total' : { 'value' : 3, 'relation' : 'eq' },'max_score' : 0.37365946,'hits' : [{ '_index' : 'test_org_id','_id' : 'CWGOhYkBHWntshc80OFi','_score' : 0.37365946,'_source' : { 'org_id' : 'qh0000017996506', 'org_name' : '山东昆仑京博能源有限公司', 'org_code' : '577790166', 'org_usc_code' : '913716255777901660' }},{ '_index' : 'test_org_id','_id' : 'B2GOhYkBHWntshc80OEs','_score' : 0.35667494,'_source' : { 'org_id' : 'qh0000016598985', 'org_name' : '山东京博石油化工有限公司', 'org_code' : '167154095', 'org_usc_code' : '913716251671540959' }},{ '_index' : 'test_org_id','_id' : 'CGGOhYkBHWntshc80OFc',
'_score' : 0.35667494,
'_source' : { 'org_id' : 'qh0000017998348', 'org_name' : '山东天宏新能源化工有限公司', 'org_code' : '670528461', 'org_usc_code' : '913716256705284610' }}]}})
精确搜索-使用keyword索引
>>> es.search(index=es_index, query={"term": {'org_name.keyword': '山东昆仑京博能源有限公司'}}) # 精确搜索-使用keyword索引
ObjectApiResponse ({ 'took' : 1,'timed_out' : FALSE,'_shards' : { 'total' : 1, 'successful' : 1, 'skipped' : 0, 'failed' : 0 },'hits' : { 'total' : { 'value' : 1, 'relation' : 'eq' },'max_score' : 1.2039728,'hits' : [{ '_index' : 'test_org_id','_id' : 'CWGOhYkBHWntshc80OFi',
'_score' : 1.2039728,
'_source' : { 'org_id' : 'qh0000017996506', 'org_name' : '山东昆仑京博能源有限公司', 'org_code' : '577790166', 'org_usc_code' : '913716255777901660' }}]}})
精确搜索-多个词语
>>> es.search(index=es_index, query={"terms": {'org_name.keyword': ['山东昆仑京博能源有限公司', '山东京博石油化工有限公司']}}) # 精确搜索-多个词语
ObjectApiResponse ({ 'took' : 1,'timed_out' : FALSE,'_shards' : { 'total' : 1, 'successful' : 1, 'skipped' : 0, 'failed' : 0 },'hits' : { 'total' : { 'value' : 2, 'relation' : 'eq' },'max_score' : 1.0,'hits' : [{ '_index' : 'test_org_id','_id' : 'B2GOhYkBHWntshc80OEs','_score' : 1.0,'_source' : { 'org_id' : 'qh0000016598985', 'org_name' : '山东京博石油化工有限公司', 'org_code' : '167154095', 'org_usc_code' : '913716251671540959' }},{ '_index' : 'test_org_id','_id' : 'CWGOhYkBHWntshc80OFi',
'_score' : 1.0,
'_source' : { 'org_id' : 'qh0000017996506', 'org_name' : '山东昆仑京博能源有限公司', 'org_code' : '577790166', 'org_usc_code' : '913716255777901660' }}]}})
精确搜索-非中文可以直接使用
>>> es.search(index=es_index, query={"term": {'org_code': '670528461'}}) # 精确搜索-非中文可以直接使用
ObjectApiResponse ({ 'took' : 1,'timed_out' : FALSE,'_shards' : { 'total' : 1, 'successful' : 1, 'skipped' : 0, 'failed' : 0 },'hits' : { 'total' : { 'value' : 1, 'relation' : 'eq' },'max_score' : 1.2039728,'hits' : [{ '_index' : 'test_org_id','_id' : 'CGGOhYkBHWntshc80OFc',
'_score' : 1.2039728,
'_source' : { 'org_id' : 'qh0000017998348', 'org_name' : '山东天宏新能源化工有限公司', 'org_code' : '670528461', 'org_usc_code' : '913716256705284610' }}]}})
精确搜索-多列匹配
参考文章:https://stackoverflow.com/questions/43633472/how-to-simulate-multiple-fields-in-a-terms-query
>>> a = es.search(index=es_index, query={"bool":{'must':[{"term": {'org_code': '577790166'}},{"term": {'org_name.keyword': '山东昆仑京博能源有限公司'}}]}}) # 关系should是or的意思,must是and的意思
>>> a = es.search(index=es_index, query={"bool":{'should':[{"term": {'org_code': '577790166'}},{"terms": {'org_name.keyword': ['山东昆仑京博能源有限公司', '山东京博石油化工有限公司']}}]}}) # 关系should是or的意思,must是and的意思
id查询
>>> es.get(index=es_index, id='CGGOhYkBHWntshc80OFc', ignore=[404]) # id查询
ObjectApiResponse ({ '_index' : 'test_org_id','_id' : 'CGGOhYkBHWntshc80OFc','_version' : 1,'_seq_no' : 1,'_primary_term' : 1,
'found' : TRUE,
'_source' : { 'org_id' : 'qh0000017998348', 'org_name' : '山东天宏新能源化工有限公司', 'org_code' : '670528461', 'org_usc_code' : '913716256705284610' }})
>>> es.mget(index=es_index, ids=['CGGOhYkBHWntshc80OFc','CWGOhYkBHWntshc80OFi',] , ignore=[404])
ObjectApiResponse ({ 'docs' : [{ '_index' : 'test_org_id','_id' : 'CGGOhYkBHWntshc80OFc','_version' : 1,'_seq_no' : 1,'_primary_term' : 1,'found' : TRUE,'_source' : { 'org_id' : 'qh0000017998348', 'org_name' : '山东天宏新能源化工有限公司', 'org_code' : '670528461', 'org_usc_code' : '913716256705284610' }},{ '_index' : 'test_org_id','_id' : 'CWGOhYkBHWntshc80OFi','_version' : 1,'_seq_no' : 2,'_primary_term' : 1,
'found' : TRUE,
'_source' : { 'org_id' : 'qh0000017996506', 'org_name' : '山东昆仑京博能源有限公司', 'org_code' : '577790166', 'org_usc_code' : '913716255777901660' }}]})
更新数据
tmp_doc = {'org_id': 'qh0000016598985','org_name': '山东京博石油化工有限公司', # 精确搜索使用的字段'org_code': '167154095','org_usc_code': '913716251671540959'
}
es.update(index=es_index, id='_WFwd4kBHWntshc80-AY', doc=tmp_doc)
tmp_doc = {"script": { # 更新内容"source": "ctx._source['org_code']='123123123123'","lang": "painless"},"query": { # 查询匹配"term": {"org_name.keyword": "山东天宏新能源化工有限公司"}}
}
es.update_by_query(index=es_index, body=tmp_doc)
删除数据
es.delete(index=es_index, id='_WFwd4kBHWntshc80-AY', ignore=[404])
es.delete_by_query(index=es_index, query={"term": {'org_name.keyword': '山东昆仑京博能源有限公司'}})
ps:这里的删除,是指直接把数据标记为待删除,等系统后续从index中删除。
简易封装
from elasticsearch import Elasticsearch
import time
import reclass ConnectElasticSearch(object):def __init__(self, **kwargs):self.hosts = kwargs.get("hosts", ["https://192.168.1.1:9200"])self.basic_auth = kwargs.get("basic_auth", ['elastic', '123456'])self.conn = Elasticsearch(hosts=self.hosts,basic_auth=self.basic_auth,verify_certs=False,retry_on_timeout=True)def cleanSearchResult(self, source, item:str = 'origin'):'''清理/解析查询回来的数据:param source: 查询的结果:param item: 需要的内容:return:'''assert item in ['origin', 'raw', 'max_score', 'max_score_source', '_source', '_id', '_index', '_score']hits = source.body['hits']max_score = hits['max_score']raw = hits['hits']if item == 'origin':return hitsif item == 'raw':return rawif item == 'max_score':return [i for i in raw if i['_score'] == max_score]if item == 'max_score_source':return [i['_source'] for i in raw if i['_score'] == max_score]if item == '_source':return [i['_source'] for i in raw]if item == '_id':return [i['_id'] for i in raw]if item == '_index':return [i['_index'] for i in raw]if item == '_score':return [i['_score'] for i in raw]def insert(self, index: str, source: pd.DataFrame) -> None:'''插入数据,模仿sql中的[insert]逻辑:param index: str,索引:param source: DataFrame,待入库数据:return: None'''source = source.to_dict(orient='records')for i in source:self.conn.index(index=index, document=i)def ignore(self, index: str, source: pd.DataFrame, primary_key: list[str]):'''插入数据,模仿sql中的[insert ignore]逻辑,当有相同主键数据时后忽略不插入:param index: str,索引:param source: DataFrame,待入库数据:param primary_key: list[str],主键所在列名:return: None'''source = source.to_dict(orient='records')for i in source:query = {'bool': {'must': []}}for pk in primary_key:tmp = re.sub('\.keyword$', '', pk)query['bool']['must'].append({"term": {pk: i.get(tmp)}})tmp = self.conn.search(index=index, query=query)raw = self.cleanSearchResult(tmp, 'raw')if raw == []: # es中没有该条数据self.conn.index(index=index, document=i)def update(self, index: str, source: pd.DataFrame, primary_key: list[str]):'''插入数据,模仿sql中的[insert into on duplicate key update]逻辑,当有相同主键数据时后忽略不插入:param index: str,索引:param source: DataFrame,待入库数据:param primary_key: list[str],主键所在列名:return: None'''source = source.to_dict(orient='records')for i in source:query = {'bool': {'must': []}}for pk in primary_key:tmp = re.sub('\.keyword$', '', pk)query['bool']['must'].append({"term": {pk: i.get(tmp)}})tmp = self.conn.search(index=index, query=query)id = self.cleanSearchResult(tmp, '_id')if id == []: # es中没有该条数据self.conn.index(index=index, document=i)else:for k in id:self.conn.update(index=index, id=k, doc=i)def only_update(self, index: str, source: pd.DataFrame, primary_key: list[str]):'''插入数据,模仿sql中的[update]逻辑,当有相同主键数据时后忽略不插入:param index: str,索引:param source: DataFrame,待入库数据:param primary_key: list[str],主键所在列名:return: None'''source = source.to_dict(orient='records')for i in source:query = {'bool': {'must': []}}for pk in primary_key:tmp = re.sub('\.keyword$', '', pk)query['bool']['must'].append({"term": {pk: i.get(tmp)}})tmp = self.conn.search(index=index, query=query)id = self.cleanSearchResult(tmp, '_id')if id == []: # es中没有该条数据continueelse:for k in id:self.conn.update(index=index, id=k, doc=i)def delete(self, index: str, source: pd.DataFrame, primary_key: list[str]):'''插入数据,模仿sql中的[delete]逻辑,当有相同主键数据时后忽略不插入:param index: str,索引:param source: DataFrame,待入库数据:param primary_key: list[str],主键所在列名:return: None'''source = source.to_dict(orient='records')for i in source:query = {'bool': {'must': []}}for pk in primary_key:tmp = re.sub('\.keyword$', '', pk)query['bool']['must'].append({"term": {pk: i.get(tmp)}})self.conn.delete_by_query(index=index, query=query)