JPA 批量插入较大数据 解决性能慢问题
JPA 批量插入较大数据 解决性能慢问题
使用jpa saveAll接口的话需要了解原理:
@Transactional@Overridepublic <S extends T> List<S> saveAll(Iterable<S> entities) {Assert.notNull(entities, "Entities must not be null!");List<S> result = new ArrayList<>();// 使用for循环遍历for (S entity : entities) {result.add(save(entity));}return result;}@Transactional@Overridepublic <S extends T> S save(S entity) {Assert.notNull(entity, "Entity must not be null.");// 每条数据都会查询之后 做下判断if (entityInformation.isNew(entity)) {em.persist(entity);return entity;} else {return em.merge(entity);}}public boolean isNew(T entity) {ID id = getId(entity);Class<ID> idType = getIdType();if (!idType.isPrimitive()) {// 如果id有值,则认为不是新数据,则更新操作,否则就是写入操作return id == null;}if (id instanceof Number) {return ((Number) id).longValue() == 0L;}throw new IllegalArgumentException(String.format("Unsupported primitive id type %s", idType));}
以上是jpa源码,所以导致写入数据很慢。因为for遍历一行一行数据写入,而且还要判断;
以下为亲测两种解决方案:
第一种: 自己编写写入逻辑,引入 EntityManager entityManager,代码如下
批量写入一批数据。一次事务提交一批。
@Value("${spring.jpa.properties.hibernate.jdbc.batch_size:1000}")private int batchSize;@PersistenceContextprivate EntityManager entityManager;public <T> void batchInsert(List<T> list) {if (!ObjectUtils.isEmpty(list)){for (int i = 1; i <= list.size(); i++) {// 写入操作entityManager.persist(list.get(i - 1));if (i % batchSize == 0) {entityManager.flush();entityManager.clear();}}if (list.size() % batchSize != 0) {//flush() 同步持久上下文环境,即将持久上下文环境的所有未保存实体的状态信息保存到数据库中。entityManager.flush();//clear() 清除持久上下文环境,断开所有关联的实体。如果这时还有未提交的更新则会被撤消。entityManager.clear();}}}public <T> void batchUpdate(List<T> list) {if (!ObjectUtils.isEmpty(list)){for (int i = 1; i < list.size(); i++) {entityManager.merge(list.get(i - 1));if (i % batchSize == 0) {entityManager.flush();entityManager.clear();}}if (list.size() % batchSize != 0) {entityManager.flush();entityManager.clear();}}}
第二种:不需要自己编写逻辑,使用jpa saveAll()方法
开启JPA批处理
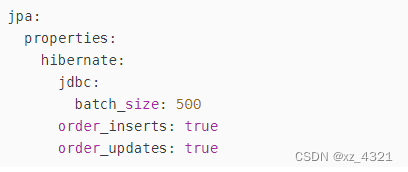
jpa 表映射@Table 下对主键使用序列,postgre支持创建序列,可以使用,其他数据源不一定。
@GeneratedValue(strategy = SEQUENCE, generator = "seqGen")@SequenceGenerator(name = "seqGen", sequenceName = "seq", initialValue = 1)
这样做的逻辑saveAll()不需要判断isNew,直接走em.persist(entity);
两种的性能差不多,记录下