client-go的Indexer三部曲之三:源码阅读
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
《client-go的Indexer三部曲》全部链接
- 基本功能
- 性能测试
- 源码阅读
本篇概览
- 本文是《client-go的Indexer三部曲》系列的终篇,主要任务是阅读和分析Indexer相关的源码,最终目的是深入理解Indexer原理,以及在各个典型场景的用法,如此一来,既抓住了细节,又能中整体上理解其存在的目的,相信您也会收获满满
- 接口源码位置:client-go/tools/cache/index.go
- 实现源码位置:client-go/tools/cache/store.go
强烈建议
- 建议您预先阅读过《client-go的Indexer三部曲之一》,此文内用多种pod的分类进行举例,今天的源码分析中依旧以此为例来说明,唯有如此才能避免读代码时的抽像和索然无味
- 回顾之前的pod分类,下面的表格说明了nginx、tomcat、mysql这些pod的两个label的具体值
| pod | 语言类型(language) | 服务类型(business-service-type) |
|---|---|---|
| nginx | c | web |
| tomcat | c | web |
| mysql | java | storage |
接口定义
- Indexer是个接口,咱们先看和它相关的源码
- 第一个要看的是Indexers的定义(注意,是Indexers,不是Indexer),其实就是map
type Indexers map[string]IndexFunc
- 在《client-go的Indexer三部曲之一》中,其实咱们已经用过Indexers了,回顾如下图,key是个字符串,其实就是分类方式的名称,例如按照语言分类就用indexer_language,value就是分类操作的具体实现,下图展示的是取出pod的label值,所以,不同的label值导致各个pod被分为不同类别(c语言类、java类等)
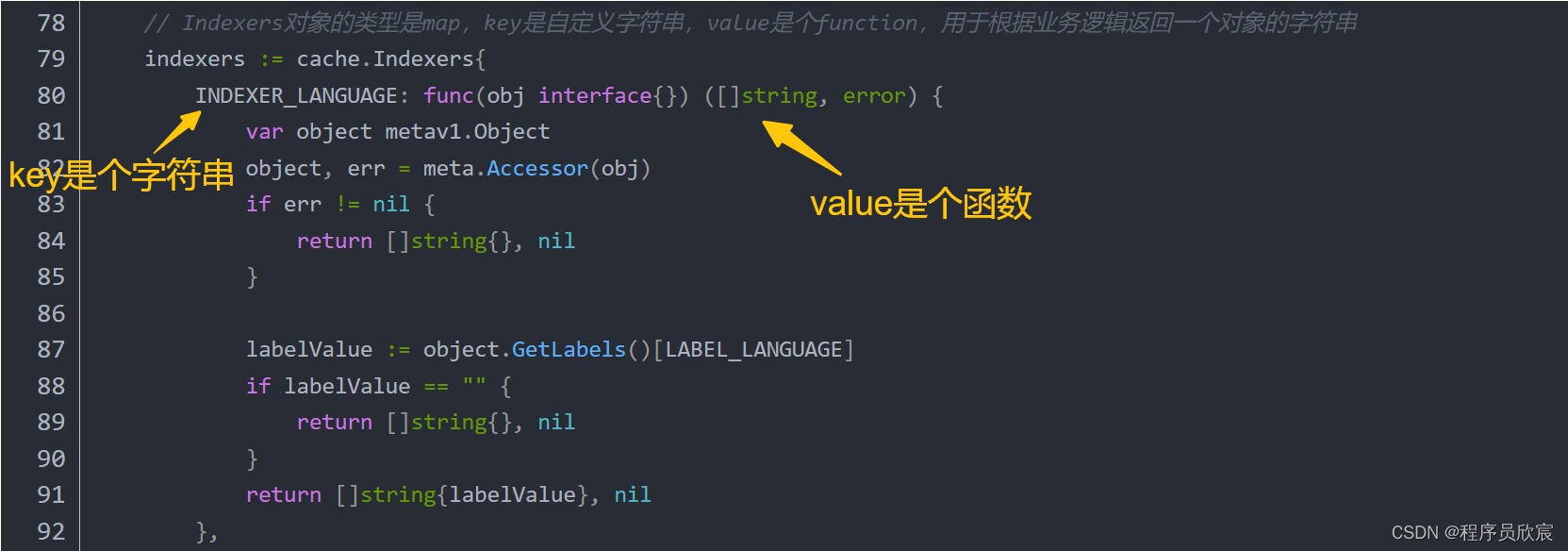
- 有Indexers撑起了完整的业务分类逻辑,接下来Indexer就能以此为基础实现各种功能了,该接口每个方法的分析分析如下
type Indexer interface {// 存储相关的,不在本章讨论Store// indexName表示分类方式,obj表示用来查询的对象,// 例如indexName等于BY_LANGUAGE,obj等于nginx的pod对象,// 那么Index方法就会根据BY_LANGUAGE去获取pod对象的语言类型,即c语言,再返回所有c语言类型的对象// 简而言之就是:查找和obj同一个语言类型的所有对象Index(indexName string, obj interface{}) ([]interface{}, error)// indexName表示分类方式,indexedValue表示分类的值,// 例如indexName等于BY_LANGUAGE,indexedValue等于c,// 那么IndexKeys方法就会返回所有语言类型等于c的对象的keyIndexKeys(indexName, indexedValue string) ([]string, error)// indexName表示分类方式,// 例如indexName等于BY_LANGUAGE,// ListIndexFuncValues返回的就是java和cListIndexFuncValues(indexName string) []string// indexName表示分类方式,indexedValue表示分类的值,// 例如indexName等于BY_LANGUAGE,indexedValue等于c,// 那么ByIndex方法就会返回所有语言类型等于c的对象ByIndex(indexName, indexedValue string) ([]interface{}, error)// Indexers是个map,key是分类方式,// 本文中key有两个,分别是BY_LANGUAGE和BY_SERVICE,// value则是个方法,// key等于BY_LANGUAGE的时候,该方法的入参是个对象pod,返回值是这个pod的语言,// key等于BY_SERVICE的时候,该方法的入参是个对象pod,返回值是这个pod的服务类型,GetIndexers() Indexers// 添加IndexersAddIndexers(newIndexers Indexers) error
}- 可见Indexer继承了Store接口,这个Store其实就是基础的增删改查,所以Indexer既能按照指定分类方式管理,也有最基础的增删改查能力
type Store interface {// Add adds the given object to the accumulator associated with the given object's keyAdd(obj interface{}) error// Update updates the given object in the accumulator associated with the given object's keyUpdate(obj interface{}) error// Delete deletes the given object from the accumulator associated with the given object's keyDelete(obj interface{}) error// List returns a list of all the currently non-empty accumulatorsList() []interface{}// ListKeys returns a list of all the keys currently associated with non-empty accumulatorsListKeys() []string// Get returns the accumulator associated with the given object's keyGet(obj interface{}) (item interface{}, exists bool, err error)// GetByKey returns the accumulator associated with the given keyGetByKey(key string) (item interface{}, exists bool, err error)// Replace will delete the contents of the store, using instead the// given list. Store takes ownership of the list, you should not reference// it after calling this function.Replace([]interface{}, string) error// Resync is meaningless in the terms appearing here but has// meaning in some implementations that have non-trivial// additional behavior (e.g., DeltaFIFO).Resync() error
}
- 此刻通过接口定义,已经了解了Indexer的大致功能,接下来可以看看具体实现
接口实现
- Indexer的实现是cache这个结构体,它的第一个字段容易理解,Indexer本质是个缓存功能,cacheStorage就是真正保存数据的地方,第二个keyFunc,就是往Indexers中添加记录的时候,为该记录生成对象主键的方法
type cache struct {// cacheStorage bears the burden of thread safety for the cachecacheStorage ThreadSafeStore// keyFunc is used to make the key for objects stored in and retrieved from items, and// should be deterministic.keyFunc KeyFunc
}
- 关于对象主键,就是这个对象在Indexer中的唯一身份,在《client-go的Indexer三部曲之一》中,basic/get_obj_keys_by_language_name?language=c这个接口返回的就是所有语言类型是c语言的pod的对象主键,接口返回内容如下所示,每个主键都是namespace和podName拼接出来的,而负责这个拼接逻辑的就是keyFunc(稍后咱们会去寻找找这个keyFunc的源码)
HTTP/1.1 200 OK
Content-Type: application/json; charset=utf-8
Date: Wed, 14 Jun 2023 22:56:37 GMT
Content-Length: 219
Connection: close{"language": ["indexer-tutorials/mysql-556b999fd8-22hqh","indexer-tutorials/nginx-deployment-696cc4bc86-2rqcg","indexer-tutorials/nginx-deployment-696cc4bc86-bkplx","indexer-tutorials/nginx-deployment-696cc4bc86-m7wwh"]
}
- 来看cache是如何创建的,这里有个公共方法,可见cache的两个字段都是通过NewIndexer方法的入参来设置的,
func NewIndexer(keyFunc KeyFunc, indexers Indexers) Indexer {return &cache{cacheStorage: NewThreadSafeStore(indexers, Indices{}),keyFunc: keyFunc,}
}
- 上述NewIndexer是在controller.go的NewIndexerInformer方法中被调用的
func NewIndexerInformer(lw ListerWatcher,objType runtime.Object,resyncPeriod time.Duration,h ResourceEventHandler,indexers Indexers,
) (Indexer, Controller) {// This will hold the client state, as we know it.clientState := NewIndexer(DeletionHandlingMetaNamespaceKeyFunc, indexers)return clientState, newInformer(lw, objType, resyncPeriod, h, clientState)
}
- 这个NewIndexerInformer方法,咱们应该有印象吧,《client-go的Indexer三部曲之一》中正是用的这个方法来实例化Informer的,如下图
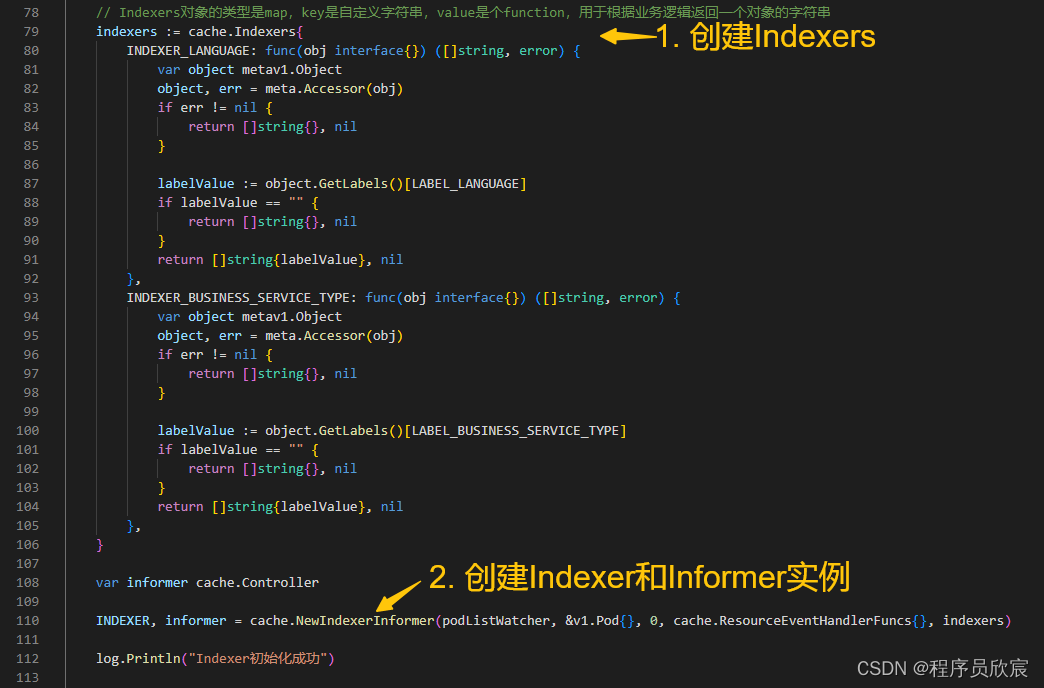
- 回到NewIndexerInformer,看看NewIndexer的两个入参,第二个参数indexers咱们已经熟悉了,是Indexers类型,刚刚已经分析过,现在要关注的是第一个参数DeletionHandlingMetaNamespaceKeyFunc,如下图黄色箭头所示
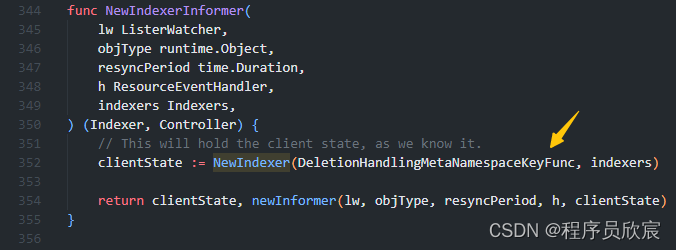
- 上述DeletionHandlingMetaNamespaceKeyFunc,对应的是方法MetaNamespaceKeyFunc,这就是生成对象key的具体逻辑了,用namespace和对象的name拼接而成,前面咱们曾调用接口返回的对象key,就是这里的代码生成的
func MetaNamespaceKeyFunc(obj interface{}) (string, error) {if key, ok := obj.(ExplicitKey); ok {return string(key), nil}meta, err := meta.Accessor(obj)if err != nil {return "", fmt.Errorf("object has no meta: %v", err)}if len(meta.GetNamespace()) > 0 {return meta.GetNamespace() + "/" + meta.GetName(), nil}return meta.GetName(), nil
}
新增对象到缓存的逻辑
- 接下来看个关键逻辑:新增对象到缓存时执行了哪些代码
- 首先还是要从NewInformer方法开始,可见Indexer接口的实现对象作为入参被传入了newInformer方法
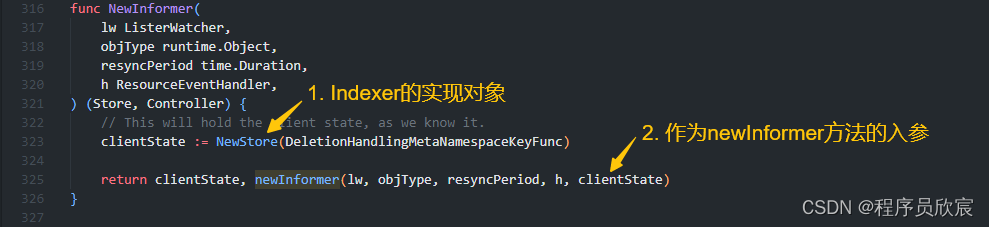
- 展开newInformer方法,源码和分析如下图所示,此刻只剩下感慨了:代码写得真好,不用层层展开,所有重要逻辑一目了然

- 这里对着上面的图,把逻辑捋一下:假设咱们用kubectl apply -f xxx.yml命令新增了一个pod,此刻client-go就会收到api-server发来的事件,类型是pod新增,该事件进入先入先出队列fifo,然后应该会有段逻辑从队列中取出数据(记住这句话,稍后要验证的),再调用processor依次处理这些从队列中取出来的数据,具体的处理逻辑就是上图的4和5:d.Object就是新增的对象,拿到后调用clientState.Add方法,把对象添加到缓存中
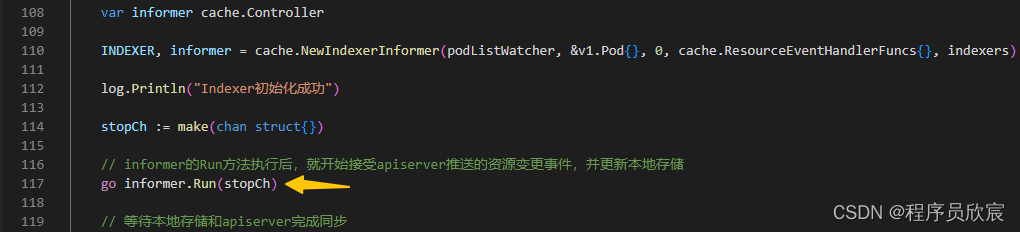
- 上面提到一句然后应该会有段逻辑从队列中取出数据,是时候找到这段逻辑了,回到《client-go的Indexer三部曲之一》中的例子,咱们当时初始化Indexer的时候,有一段关键代码如下图黄色箭头所示,也就是informer.Run方法
- 展开informer.Run,如下图黄色箭头所示,关键代码在processLoop方法中(看名字就像)
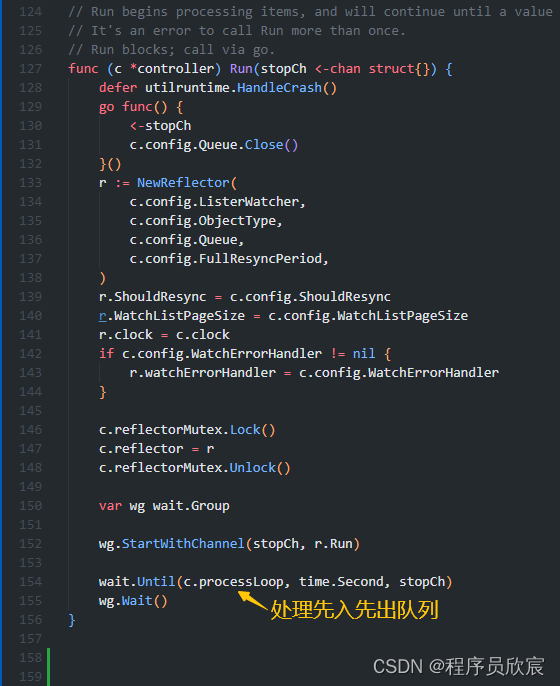
- 展开processLoop方法,如下所示,这里会不断从队列中取出数据,交给c.config.Process处理,而这个c.config.Process就是newInformer方法中的Process对象,里面是写入Indexer的逻辑
func (c *controller) processLoop() {for {obj, err := c.config.Queue.Pop(PopProcessFunc(c.config.Process))if err != nil {if err == ErrFIFOClosed {return}if c.config.RetryOnError {// This is the safe way to re-enqueue.c.config.Queue.AddIfNotPresent(obj)}}}
}
- 至此,新增对象时client-go将数据输入存入Indexer的代码已经看过了,再进入Indexer实现类的内部,看看Store.Add方法具体做了什么
存入缓存的具体逻辑
- 实现Store接口的Add方法是由Controller来完成的,在阅读代码前,咱们先结合《client-go的Indexer三部曲之一》中的例子做个分析,再去看真实代码来印证这个分析,这学习效果比抽象的阅读代码要好很多
- 在前面的例子中,咱们在Indexer缓存中对pod做了两种分类:按编程语言分类(有c和java两种)、还有按照服务类型分类(有存储和web两种),在这种前提下,一旦有新资源加入Indexer,此时的Indexer应该要做什么操作呢?
- 每个对象都有对象key,这是它在Indexer缓存中的唯一身份,这个必须要生成
- 提取出这个pod的语言类型和服务类型,例如语言类型是java,服务类型是web
- 在语言类型分类的映射关系中,建立java和此pod的映射关系,这样通过按语言分类 + java这个组合,就能找到这个pod
- 在服务类型分类的映射关系中,建立web和此pod的映射关系,这样通过按服务类型分类 + web这个组合,就能找到这个pod
- 维护好语言类型具体有哪些,这里应该是c和java
- 维护好服务类型具体有哪些,这里应该是存储和web
-
只有把上述事情都做了,Indexer接口定义的那些方法才能正常工作,例如IndexKeys方法,输入按语言分类和java这两个参数,返回的就是所有符合条件的pod的对象key
-
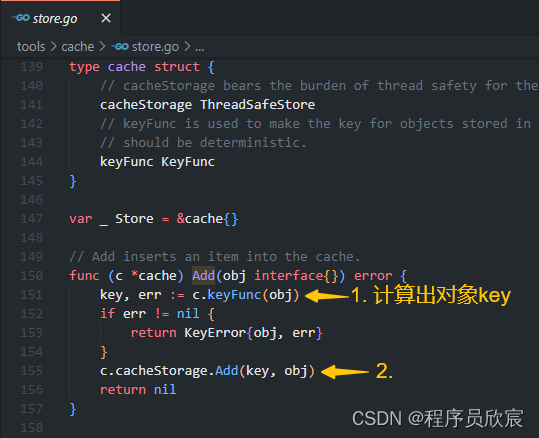
猜到Indexer在新增对象时要做的事情,接下来读代码就非常轻松了,代码入口位置如下图所示,先算出对象key,然后调用方法
-
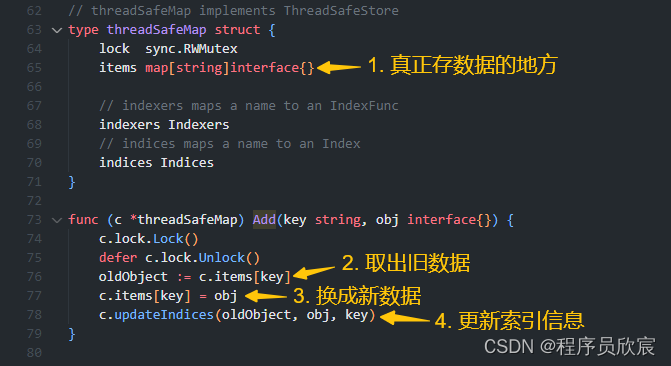
再打开上图中的c.cacheStorage.Add方法的源码,我滴个乖乖,真的好清晰整齐:先把旧数据暂存在一个变量中,再把新数据放入真正存数据的地方items,然后才去更新各种和该数据有关的索引信息,这么简洁清晰的代码读起来是享受
-
展开updateIndices方法,一切都是那么顺理成章,前面的推测都在此被印证
// updateIndices modifies the objects location in the managed indexes, if this is an update, you must provide an oldObj
// updateIndices must be called from a function that already has a lock on the cache
func (c *threadSafeMap) updateIndices(oldObj interface{}, newObj interface{}, key string) {// if we got an old object, we need to remove it before we add it again// 如果有旧数据,那么此刻应该也有旧数据的索引信息(例如java对应的pod的对象key),此处应该清理掉if oldObj != nil {c.deleteFromIndices(oldObj, key)}// c.indexers就是所有分类方式,在本文中就是按语言和按服务类型两种方式分类,// 这里用每一种分类方式分别对新增的对象做处理for name, indexFunc := range c.indexers {// indexFunc是我们按照业务需求自己写的,例如按照语言分类的时候,就是取出pod的language这个label的值indexValues, err := indexFunc(newObj)if err != nil {panic(fmt.Errorf("unable to calculate an index entry for key %q on index %q: %v", key, name, err))}// c.indices是个map,key是分类方式(例如按语言分类,indexer_language),value是Index对象// Index对象也是个map,key是该分类下的某个值,例如java,value是个集合,所有pod语言类型是java的pod,它们的对象key组成了这个集合index := c.indices[name]if index == nil {index = Index{}c.indices[name] = index}// 每一种分类方式都有一个index,例如按语言分类,有自己的index,// 在语言分类的index中,每种语言都有一个集合,这里面是所有该语言的pod的对象key,// 这里的index应该有c和java两个key,c这个key对应的集合里面有nginx和mysql的pod的对象key,jva这个key对应的集合里面有tomcat这个pod的对象key,// 下面的代码就是把pod的对象key放入对应的集合中for _, indexValue := range indexValues {set := index[indexValue]if set == nil {set = sets.String{}index[indexValue] = set}set.Insert(key)}}
}
- 上述代码清晰的展现了如何通过map和set将pod的对象key进行管理,以便查询时可以通过这些map快速查到对应的pod对象,中文注释对map和sets都做了详细说明,不过Index对象需要再细说一下
- c.indices是个map,这个map的key是分类方式,例如按语言分类,key就是indexer_language,按服务类型分类,key就是indexer_business_service_type,这都是《client-go的Indexer三部曲之一》中咱们自己写的代码,而这个map的value则是Index对象,也就是说每种分类方式都有一个Index对象
- 来看看按语言分类时,对应的Index对象到底是啥,如下图,index对象自己也是个map,里面的key是所有的语言,value是sets集合,c语言对应的sets里就是mysql和nginx这些pod的对象key

- 现在咱们已经看完了新增对象时Indexer的内部逻辑,简单的说就是:先保存对象,再更新Index
缓存的使用
- 既然已经详细分析了缓存更新的代码,那么使用缓存的逻辑也就很明白了,无非就是Indexer对象的使用呗,咱们挑一个接口的实现代码看看是否如此
- 就看Indexer.IndexKeys方法吧,指定分类方式是按语言分类,指定语言是java,看IndexKeys如何找到tomcat这个pod的对象key
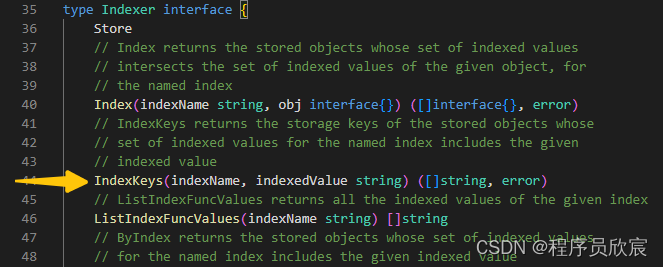
- 以下是IndexKeys方法的源码,可见真实逻辑在c.cacheStorage.IndexKeys
func (c *cache) IndexKeys(indexName, indexKey string) ([]string, error) {return c.cacheStorage.IndexKeys(indexName, indexKey)
}
- 打开c.cacheStorage.IndexKeys方法,如下所示,没有任何意外,只要找到Index就算成功了
func (c *threadSafeMap) IndexKeys(indexName, indexedValue string) ([]string, error) {c.lock.RLock()defer c.lock.RUnlock()indexFunc := c.indexers[indexName]// 通过indexFunc来判断这个分类方式是否存在if indexFunc == nil {return nil, fmt.Errorf("Index with name %s does not exist", indexName)}// 拿到按照语言分类的Index对象index := c.indices[indexName]// index对象中有每一种语言对于的pod的对象key,取出来直接返回即可set := index[indexedValue]return set.List(), nil
}
- 轻轻松松,Indexer的源码阅读就算完成了,总的来说代码并不复杂,把涉及到的几个map梳理清楚,基本上就能弄明白完整的逻辑了,现在咱们已经掌握了Indexer的底层实现,在今后的开发中,相信您就能根据这些map的关系,巧妙的设计出与业务匹配的定制化Indexer,让这个优秀的缓存工具在云开发中充分的发挥作用
- 至此《client-go的Indexer三部曲》系列也到了结束的时候,然而client-go大系列不会结束,后面欣宸还会更新client-go相关的原创,与大家一起继续学习这个优秀的框架
你不孤单,欣宸原创一路相伴
- Java系列
- Spring系列
- Docker系列
- kubernetes系列
- 数据库+中间件系列
- DevOps系列