Apache Zeppelin系列教程第九篇——Zeppelin NoteBook数据缓存
背景
在使用Zeppelin JDBC Intercepter 对于Hive 数据进行查询过程中,如果遇到非常复杂的sql,查询效率是非常慢
比如:
select dt,count(*) from table group by dt
做过数据开发的同学都知道,在hive sql查询过程中,hive 会被转换为MapReduce,但是对于不是所有sql 都会有mapper和reducer 的过程,如果只是简单的查询不会涉及reducer,只有统计相关的查询会涉及到reducer,而其中的shuffle 和 reducer 是非常耗时
如果有有这样一些sql
sql1:
select * from ( select name,count(*) from table0 group name ) t where name=’xiaohong’sql2:
select * from ( select name,count(*) from table0 group name ) t where name=’xiaoli’
我们能看到sql1 和sql2 只是修改了一下查询条件,但是如果是单独执行,则需要对进行两次完整的查询,比如说:sql1需要花费10分钟,同样sql2也需要再花费10分钟
而adhoc 场景中,这种场景非常常见,只是简单修改一个sql 的查询条件就需要走多次一模一样的流程。
那我们有没有什么办法去优化下?
优化思路分析
无论是hive sql 还是spark sql,只要是复杂的sql,难免会涉及到shuffle或者reducer 过程,这两个过程恰恰是整个过程中非常耗时的过程。那我们现在分析哪些大数据的查询sql会导致查询非常慢呢?
(1)sql 里面含有group by、distinct
(2)sql含有order by,order by 是要根据数据全局排序
(3)含有count、join 这种需要统计和关联其他表数据的sql
上述sql 在大数据查询是都是比较慢的,相教育一些只是简单的过滤查询场景
优化思路流程:
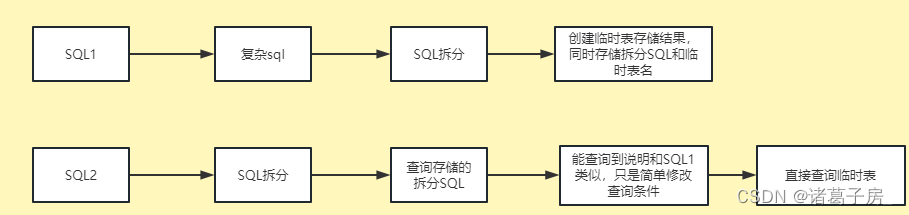
当然最后每天晚上要清除一下当天产生的所有临时表,避免表数据过多
非常遗憾的是Zeppelin Committer 认为这个功能可能会影响到项目的整体架构,而不进行合并,所以我在此进行阐述,详细设计和pr参考:https://github.com/apache/zeppelin/pull/4611