RL - 强化学习 马尔可夫奖励过程 (MRP) 的状态价值
欢迎关注我的CSDN:https://spike.blog.csdn.net/
本文地址:https://blog.csdn.net/caroline_wendy/article/details/131084795
GitHub 源码: https://github.com/SpikeKing/Reinforcement-Learning-Algorithm
马尔可夫奖励过程 (MRP) 的状态价值是指在某个状态下,从该状态开始,按照某个策略执行动作所能获得的累积奖励的期望值。状态价值反映了状态的优劣,越高的状态价值意味着越好的长期收益。MRP 的状态价值可以通过贝尔曼方程递归地定义和计算。
马尔可夫奖励过程,即MRP,Markov Reward Process;而马尔可夫决策过程,即MDP,Markov Decision Process。
1. 马尔可夫过程 (Markov Process)
随机过程(Stochastic Process)即 P ( S t + 1 ∣ S 1 , . . . , S t ) P(S_{t+1}|S_{1},...,S_{t}) P(St+1∣S1,...,St),马尔可夫过程(Markov Process),即 P ( S t + 1 ∣ S t ) = P ( S t + 1 ∣ S 1 , . . . , S t ) P(S_{t+1}|S_{t}) = P(S_{t+1}|S_{1},...,S_{t}) P(St+1∣St)=P(St+1∣S1,...,St)。
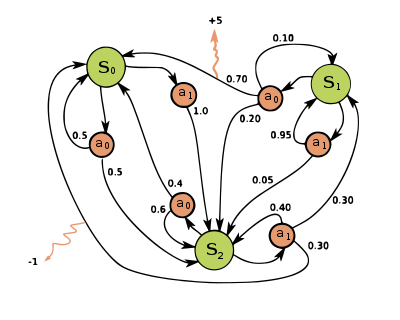
马尔可夫过程: S = s 1 , s 2 , . . s n \mathcal{S}={s_{1},s_{2},..s_{n}} S=s1,s2,..sn 状态集合(State), P \mathcal{P} P 状态转移矩阵(Probability)。给定一个马尔可夫过程,从一个状态出发,可以获得状态序列(episode),即采样(sampling)。
2. 马尔可夫奖励过程 (Markov Reward Process)
马尔可夫奖励过程(Markov Reward Process)由 < S , P , r , γ > <\mathcal{S},\mathcal{P},r,\gamma> <S,P,r,γ> 组成,即增加 r ( s ) r(s) r(s) 表示每个状态的奖励(Return), γ \gamma γ 是折扣因子,随着时间逐渐减弱。
所有奖励的衰减之和,作为 G G G,即 Gain。
G t = R t + γ R t + 1 + γ 2 R t + 2 + . . . = ∑ k = 0 ∞ γ k R t + k G_{t} = R_{t} + \gamma R_{t+1} + \gamma^{2} R_{t+2} + ... = \sum_{k=0}^{\infty}\gamma^{k} R_{t+k} Gt=Rt+γRt+1+γ2Rt+2+...=k=0∑∞γkRt+k
源码:
def compute_return(start_index, chain, gamma, rewards):G = 0for i in reversed(range(start_index, len(chain))):# chain是从1开始,之前奖励G * 折扣因子gamma,再加上当前奖励RG = gamma * G + rewards[chain[i] - 1] return G
3. 贝尔曼方程 (Bellman Equation) 与 状态价值
状态的期望回报,就是这个状态的价值(Value),价值函数:
V ( s ) = E [ G t ∣ S t = s ] V ( s ) = E [ R t + γ V ( S t − 1 ) ∣ S t = s ] V ( s ) = E [ R t ∣ S t = s ] + E [ γ V ( S t − 1 ) ∣ S t = s ] V ( s ) = r ( s ) + γ ∑ s ′ ∈ S P ( s ′ ∣ s ) V ( s ′ ) V(s)=E[G_{t}|S_{t}=s] \\ V(s)=E[R_{t}+\gamma V(S_{t-1})|S_{t}=s] \\ V(s)=E[R_{t}|S_{t}=s]+E[\gamma V(S_{t-1})|S_{t}=s] \\ V(s)=r(s)+\gamma \sum_{s'\in{S}}P(s'|s)V(s') V(s)=E[Gt∣St=s]V(s)=E[Rt+γV(St−1)∣St=s]V(s)=E[Rt∣St=s]+E[γV(St−1)∣St=s]V(s)=r(s)+γs′∈S∑P(s′∣s)V(s′)
即:贝尔曼方程(Bellman Equation)。求解各个状态的价值 V \mathcal{V} V 如下:
V = R + γ P V V = ( I − γ P ) − 1 R \mathcal{V} = \mathcal{R} + \gamma \mathcal{P} \mathcal{V} \\ \mathcal{V} = (\mathcal{I}-\gamma \mathcal{P})^{-1} \mathcal{R} V=R+γPVV=(I−γP)−1R
计算复杂度是 O ( n 3 ) O(n^3) O(n3) ,改进算法包括 动态规划(Dynamic Programming)、蒙特卡洛方法(Monte Carlo Method)、时序差分(Temporal Difference)等。
源码:
def compute(P, rewards, gamma, states_num):"""利用 贝尔曼方程 解析"""rewards = np.array(rewards).reshape((-1, 1)) # 转换成列向量# V = (I - gamma*P)^(-1) * Rvalue = np.dot(np.linalg.inv(np.eye(states_num, states_num) - gamma * P), rewards)return value