论文笔记--Deep contextualized word representations
论文笔记--Deep contextualized word representations
- 1. 文章简介
- 2. 文章概括
- 3 文章重点技术
- 3.1 BiLM(Bidirectional Language Model)
- 3.2 ELMo
- 3.3 将ELMo用于NLP监督任务
- 4. 文章亮点
- 5. 原文传送门
1. 文章简介
- 标题:Deep contextualized word representations
- 作者:Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, Luke Zettlemoyer
- 日期:2018
- 期刊:arxiv preprint
2. 文章概括
文章提出了一种语言模型的预训练方法ELMo(Embeddings from Language Models)。与传统仅仅使用最顶层隐藏层的神经网络不同,ELMo将所有biLM隐藏层信息通过线性层汇总,从而使得模型同时将高级特征和低级特征输入到模型输出阶段。ELMo在文章实验的所有NLP任务上均达到或超过了SOTA。
3 文章重点技术
3.1 BiLM(Bidirectional Language Model)
给定序列 ( t 1 , … , t N ) (t_1, \dots, t_N) (t1,…,tN),前向语言模型(生成式)基于当前时刻前的token计算当前时刻的token概率,即在时刻 t t t,给定 ( t 1 , … t k − 1 ) (t_1, \dots t_{k-1}) (t1,…tk−1),计算 p ( t 1 , … , t N ) = ∏ k = 1 N p ( t k ∣ t 1 , … , t k − 1 ) . p(t_1,\dots, t_N) = \prod_{k=1}^N p(t_k|t_1, \dots, t_{k-1}). p(t1,…,tN)=k=1∏Np(tk∣t1,…,tk−1).
后向语言模型则相反,即通过当前时刻之后的token预测当前时刻token的概率 p ( t 1 , … , t N ) = ∏ k = 1 N p ( t k ∣ t k + 1 , … , t N ) . p(t_1,\dots, t_N) = \prod_{k=1}^N p(t_k|t_{k+1}, \dots, t_N). p(t1,…,tN)=k=1∏Np(tk∣tk+1,…,tN).
双向语言模型(biLM)将上述二者结合,最大对数似然 ∑ k = 1 N log p ( t k ∣ t 1 , … , t k − 1 ; Θ x , Θ ⃗ L S T M , Θ s ) + log p ( t k ∣ t k + 1 , … , t N ; Θ x , Θ ← L S T M , Θ s ) \sum_{k=1}^N \log p(t_k|t_1, \dots, t_{k-1};\Theta_x, \vec{\Theta}_{LSTM}, \Theta_s) +\hspace{.3cm} \\\log p(t_k|t_{k+1}, \dots, t_N;\Theta_x, \overleftarrow{\Theta}_{LSTM}, \Theta_s) k=1∑Nlogp(tk∣t1,…,tk−1;Θx,ΘLSTM,Θs)+logp(tk∣tk+1,…,tN;Θx,ΘLSTM,Θs),其中 Θ x \Theta_x Θx表示token的表征参数, Θ s \Theta_s Θs表示Softmax层的参数, Θ → L S T M , Θ ← L S T M \overrightarrow{\Theta}_{LSTM}, \overleftarrow{\Theta}_{LSTM} ΘLSTM,ΘLSTM分别表示前向和后向LSTM的参数。
3.2 ELMo
对于任意token t k t_k tk,L层的biLM会计算 R k = { h k , j L M ∣ j = 0 , … , L } R_k = \{\boldsymbol{h}_{k,j}^{LM}|j=0,\dots, L\} Rk={hk,jLM∣j=0,…,L},其中 h k , 0 L M {h}_{k,0}^{LM} hk,0LM表示token层, h k , j L M = [ h → k , j L M ; h ← k , j L M ] \boldsymbol{h}_{k,j}^{LM}=[\overrightarrow{\boldsymbol{h}}_{k,j}^{LM};\overleftarrow{\boldsymbol{h}}_{k,j}^{LM}] hk,jLM=[hk,jLM;hk,jLM]表示每一个LSTM层。
最终ELMo通过线性层将所有层的信息汇总: E L M o k t a s k = E ( R k ; Θ t a s k ) = γ t a s k ∑ j = 0 L s j t a s k ELMo_k^{task} = E(R_k;\Theta^{task})=\gamma^{task} \sum_{j=0}^L s_j^{task} ELMoktask=E(Rk;Θtask)=γtaskj=0∑Lsjtask,其中 s j t a s k s_j^{task} sjtask为softmax权重, γ t a s k \gamma^{task} γtask为标量参数,可以将ELMo向量放缩。
文章通过数值实验表明,高层和底层捕获到的信息有所区别,不同的下游任务可能用到高层或底层的特征:高层信息可用于依赖分析等语义分析任务,底层信息可用于POS等语法分析任务。从而文章选择将每一层的信息结合,一起输送给模型。
3.3 将ELMo用于NLP监督任务
给定NLP的监督任务,我们先不考虑标签,直接将biLM在数据集上训练,得到每个token的 E L M o k t a s k ELMo_k^{task} ELMoktask。然后冻结biLM的权重,将每个token的 x k x_k xk(通过字符CNN得到)连同 E L M o k t a s k ELMo_k^{task} ELMoktask一起输入到监督模型(RNN,CNN等),进行训练。此外,文章提出在输出阶段也可增加 E L M o k t a s k ELMo_k^{task} ELMoktask,即将 [ h k ; E L M o k t a s k ] [h_k; ELMo_k^{task}] [hk;ELMoktask]传入softmax层
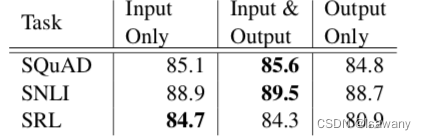
文章测试了将ELMo向量放入不同阶段的效果,如下表所示,将ELMo同时增加到输入和输出阶段的表现最好。
4. 文章亮点
文章提出了将bi-LSTM预训练向量用于NLP下游任务的方法,此外,文章通过线性层将biLM的所有层信息全部汇总,通过高级特征+低级特征共同完成训练。ELMo模型在多个任务上实现了SOTA,且显著提升了下游任务的收敛速率。
5. 原文传送门
Deep contextualized word representations