并发编程-系统学习篇
并发编程的掌握过程并不容易。 我相信为了解决这个问题,你也听别人总结过:并发编程的第 一原则, 那就是不要写并发程序
这个原则在我刚毕业的那几年曾经是行得通的,那个时候多核服务器还是一种奢侈品,系统的并发量也很低,借助数据库和类似 Tomcat 这种中间 件,我们基本上不用写并发程序。 或者说, 并发问题基本上都被中间件和数据库解决了
Java 经过这些年的发展, Java SDK 并发包提供了非常丰富的功能,对于初学者来说 可谓是眼花缭乱,好多人觉得无从下手。 但是,Java SDK 并发包乃是并发大师 Doug Lea 出品堪称经典, 它内部一定是有章可循的。 那它的章法在哪里呢?
其实并发编程可以总结为三个核心问题:
- 分工
- 同步
- 互斥
分工,指的是如何高效地拆解任务并分配给线程
同步,指的是线程之间如何协作,
互斥 则是保证同一时刻只允许一个线程访问共享资源
Java SDK 并发包很大部分内容都是按照这三个维度组织的, 例如 Fork/Join 框架就是一种分工模式, CountDownLatch 就是一种 典型的同步方式, 而可重入锁则是一种互斥手段。
当把并发编程核心的问题搞清楚, 再回过头来看 Java SDK 并发包, 你会感觉豁然开朗, 它不过是针对并发问题开发出来的工具而已, 此时的 SDK 并发包可以任你 “盘” 了。 而且,这三个核心问题是跨语言的,你如果要学习其他语言的并发编程类库,完全可以顺着 这三个问题按图索骥。 Java SDK 并发包其余的一部分则是并发容器和原子类,这些比较容易理解,属于辅助工具, 其他语言里基本都能找到对应的
并发编程并不是一门相对独立的学科, 而是一个综合学科。并发编程相关的概念和技术看上 非常零散,相关度也很低, 总给你一种这样的感觉:我已经学习很多相关技术了,可还是搞 不定并发编程。 那如何才能学习好并发编程呢? 其实很简单, 只要你能从两个方面突破一下就可以了。 一个是“跳出来, 看全景” , 另一个是“钻进去,看本质” 。
跳出来,看全景
我们先说“跳出来” 。 你应该也知道,学习最忌讳的就是“盲人摸象” , 只看到局部, 而没有看到全局。 所以, 你需要从一个个单一的知识和技术中 “跳出来” , 高屋建瓴地看并发编 程。 当然,这首要之事就是你建立起一张全景图
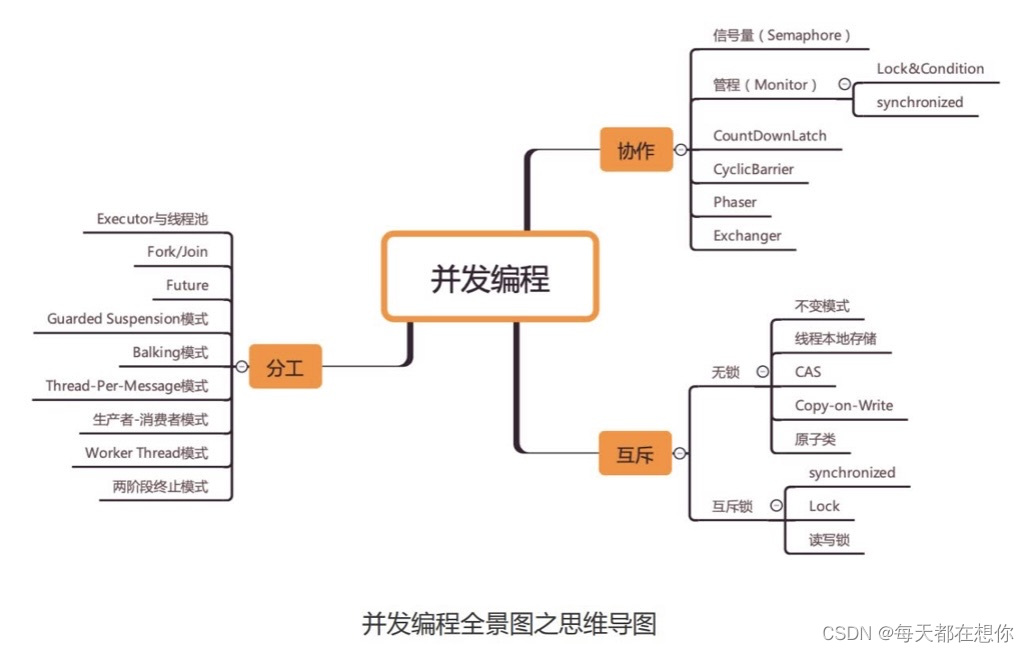
在我看来,并发编程领域可以抽象成 三个核心问题: 分工、同步和互斥 。
1. 分工
所谓分工,类似于现实中一个组织完成一个项目, 项目经理要拆分任务, 安排合适的成员去 完成。 在并发编程领域,你就是项目经理, 线程就是项目组成员。 任务分解和分工对于项目成败非 常关键, 不过在并发领域里, 分工更重要, 它直接决定了并发程序的性能。 在现实世界里, 分工是很复杂的, 著名数学家华罗庚曾用 “烧水泡茶” 的例子通俗地讲解了统筹方法(一种 安排工作进程的数学方法) , “烧水泡茶” 这么简单的事情都这么多说道, 更何况是并发编 程里的工程问题呢。
既然分工很重要又很复杂,那一定有前辈努力尝试解决过, 并且也一定有成果。的确,在并 发编程领域这方面的成果还是很丰硕的。 Java SDK 并发包里的 Executor、 Fork/Join、 Future 本质上都是一种分工方法。 除此之外, 并发编程领域还总结了一些设计模式, 基本 上都是和分工方法相关的, 例如生产者 - 消费者、 Thread-Per-Message、 Worker Thread 模式等都是用来指导你如何分工的。
学习这部分内容,最佳的方式就是和现实世界做对比。 例如生产者 - 消费者模式,可以类比一下餐馆里的大厨和服务员, 大厨就是生产者, 负责做菜, 做完放到出菜口, 而服务员就是消费者, 把做好的菜给你端过来。 不过, 我们经常会发现, 出菜口有时候一下子出了好几个菜, 服务员是可以把这一批菜同时端给你的。 其实这就是生产者 - 消费者模式的一个优点, 生产者一个一个地生产数据, 而消费者可以批处理, 这样就提高了性能。
2. 同步
分好工之后, 就是具体执行了。 在项目执行过程中, 任务之间是有依赖的, 一个任务结束 后, 依赖它的后续任务就可以开工了, 后续工作怎么知道可以开工了呢?这个就是靠沟通协作,在并发编程领域里的同步,主要指的就是线程间的协作, 本质上和现实生活中的协作没区别, 不过是 一个线程执行完了一个任务,如何通知执行后续任务的线程开工而已。 协作一般是和分工相关的。 Java SDK 并发包里的 Executor、 Fork/Join、 Future 本质上都是分工方法,但同时也能解决线程协作的问题。 例如, 用 Future 可以发起一个异步调用, 当主线程通过 get() 方法取结果时,主线程就会等待,当异步执行的结果返回时, get() 方法就自动返回了。 主线程和异步线程之间的协作, Future 工具类已经帮我们解决了。 除此之外, Java SDK 里提供的 CountDownLatch、 CyclicBarrier、 Phaser、 Exchanger 也都是用来解决线程协作问题的。 不过还有很多场景, 是需要你自己来处理线程之间的协作的。 工作中遇到的线程协作问题, 基本上都可以描述为这样的一个问题: 当某个条件不满足时,线程需要等待,当某个条件满足时, 线程需要被唤醒执行 。 例如, 在生产者 - 消费者模型 里, 也有类似的描述, “当队列满时, 生产者线程等待, 当队列不满时, 生产者线程需要被 唤醒执行; 当队列空时, 消费者线程等待, 当队列不空时, 消费者线程需要被唤醒执行。 ”
在 Java 并发编程领域, 解决协作问题的核心技术是 管程 , 上面提到的所有线程协作技术底层都是利用管程解决的。 管程是一种解决并发问题的通用模型, 除了能解决线程协作问题,还能解决下面我们将要介绍的互斥问题。 可以这么说,管程是解决并发问题的万能钥匙 。
所以说, 这部分内容的学习, 关键是理解管程模型, 学好它就可以解决所有问题。 其次是了 解 Java SDK 并发包提供的几个线程协作的工具类的应用场景, 用好它们可以妥妥地提高你 的工作效率。
3. 互斥
分工、 同步主要强调的是性能, 但并发程序里还有一部分是关于正确性的, 用专业术语 叫 “ 线程安全 ” 。 并发程序里, 当多个线程同时访问同一个共享变量的时候, 结果是不确定的。 不确定, 则意味着可能正确, 也可能错误,事先是不知道的。 而导致不确定的主要源头是可见性问题、 有序性问题和原子性问题, 为了解决这三个问题, Java 语言引入了内存模型, 内存模型提供了一系列的规则, 利用这些规则, 我们可以避免可见性问题、 有序性问题, 但是还不足以完全解决线程安全问题。 解决线程安全问题的核心方案还是互斥。 所谓互斥,指的是同一时刻, 只允许一个线程访问共享变量
实现互斥的核心技术就是锁, Java 语言里 synchronized、 SDK 里的各种 Lock 都能解决互 斥问题。 虽说锁解决了安全性问题, 但同时也带来了性能问题, 那如何保证安全性的同时又 尽量提高性能呢?可以分场景优化, Java SDK 里提供的 ReadWriteLock、 StampedLock 就可以优化读多写少场景下锁的性能。 还可以使用无锁的数据结构, 例如 Java SDK 里提供 的原子类都是基于无锁技术实现的。 除此之外, 还有一些其他的方案, 原理是不共享变量或者变量只允许读。 这方面, Java 提 供了 Thread Local 和 final 关键字, 还有一种 Copy-on-write 的模式。
使用锁除了要注意性能问题外,还需要注意死锁问题。
这部分内容比较复杂, 往往还是跨领域的, 例如要理解可见性, 就需要了解一些 CPU 和缓 存的知识; 要理解原子性, 就需要理解一些操作系统的知识; 很多无锁算法的实现往往也需 要理解 CPU 缓存。 这部分内容的学习, 需要博览群书, 在大脑里建立起 CPU、 内存、 I /O 执行的模拟器。 这样遇到问题就能得心应手了。 跳出来, 看全景, 可以让你的知识成体系, 所学知识也融汇贯通起来, 由点成线,由线及面, 画出自己的知识全景图。
钻进去,看本质
但是光跳出来还不够, 还需要下一步, 就是在某个问题上钻进去, 深入理解, 找到本质。 就拿我个人来说, 我已经烦透了去讲述或被讲述一堆概念和结论, 而不分析这些概念和结论 是怎么来的, 以及它们是用来解决什么问题的。 在大学里, 这样的教材很流行, 直接导致了芸芸学子成绩很高, 但解决问题的能力很差。 其实, 知其然知其所以然, 才算真的学明白 了。
我属于理论派,我认为工程上的解决方案,一定要有理论做基础 。 所以在学习并发编程的过程中,我都会探索它背后的理论是什么。 比如,当看到 Java SDK 里面的条件变量 Condition 的时候,我会下意识地问,“它是从哪儿来的?是 Java 的特有概念,还是一个通用的编程概念?” 当我知道它来自管程的时候,我又会问,“管程被提出的背景和解决的问题是什么?”这样一路探索下来, 我发现 Java 语言里的并发技术基本都是有理论基础的,并且这些理论在其他编程语言里也有类似的实现。所以我认为,技术的本质是背后的理论模型
注:
从性能角度讲,我们为了提高执行一定计算机任务的效率,所以IO等待的时候不能让cpu闲着,所以我们把任务拆分交替执行,有了分时操作系统,出现了并发,后来cpu多核有了并行计算。 这里也就是作者说的[分工]
分工以后我们为了进一步提升效率和更加灵活地达到目的, 所以我们要对任务进行组织编排, 也就是对线程组织编排。 于是线程之间需要通信, 于是操作系统提供了一些让进程,线程之间通信的方式。 也就是作者说的[同步]
01 | 可见性、原子性和有序性问题:并发编程Bug的源头
为什么并发编程容易出问题呢?它是怎么出问题的?今天我们就重点聊聊这些 Bug 的源头。 并发程序幕后的故事这些年,我们的 CPU、内存、 I /O 设备都在不断迭代,不断朝着更快的方向努力。 但是,在这个快速发展的过程中,有一个核心矛盾一直存在,就是这三者的速度差异。 程序里大部分语句都要访问内存,有些还要访问 I/O, 根据木桶理论(一只水桶能装多少水 取决于它最短的那块木板) , 程序整体的性能取决于最慢的操作——读写 I/O 设备, 也就是说单方面提高 CPU 性能是无效的。为了合理利用 CPU 的高性能, 平衡这三者的速度差异, 计算机体系机构、 操作系统、 编译程序都做出了贡献, 主要体现为:
1 . CPU 增加了缓存,以均衡与内存的速度差异;
2. 操作系统增加了进程、线程,以分时复用 CPU, 进而均衡 CPU 与 I/O 设备的速度差异;
3. 编译程序优化指令执行次序,使得缓存能够得到更加合理地利用
现在我们几乎所有的程序都默默地享受着这些成果, 但是天下没有免费的午餐,并发程序很多诡异问题的根源也在这里。
源头之一: 缓存导致的可见性问题
在单核时代,所有的线程都是在一颗 CPU 上执行, CPU 缓存与内存的数据一致性容易解决。 因为所有线程都是操作同一个 CPU 的缓存, 一个线程对缓存的写, 对另外一个线程来说一定是可见的。 例如在下面的图中, 线程 A 和线程 B 都是操作同一个 CPU 里面的缓 存, 所以线程 A 更新了变量 V 的值, 那么线程 B 之后再访问变量 V, 得到的一定是 V 的 最新值(线程 A 写过的值)
一个线程对共享变量的修改, 另外一个线程能够立刻看到,我们称为可见性 。
多核时代,每颗 CPU 都有自己的缓存,这时 CPU 缓存与内存的数据一致性就没那么容易解决了,当多个线程在不同的 CPU 上执行时,这些线程操作的是不同的 CPU 缓存。 比如下图中,线程 A 操作的是 CPU-1 上的缓存, 而线程 B 操作的是 CPU-2 上的缓存, 很明 显, 这个时候线程 A 对变量 V 的操作对于线程 B 而言就不具备可见性了。 这个就属于硬件开发者给软件程序员挖的“坑”
下面我们再用一段代码来验证一下多核场景下的可见性问题。下面的代码,每执行一次 add10K() 方法, 都会循环 10000 次 count+=1 操作。 在 calc() 方法中我们创建了两个线程,每个线程调用一次 add10K() 方法,我们来想一想执行 calc() 方法得到的结果应该是多少呢?
直觉告诉我们应该是 20000, 因为在单线程里调用两次 add10K() 方法, count 的值就是 20000, 但实际上 calc() 的执行结果是个 10000 到 20000 之间的随机数。 为什么呢?
我们假设线程 A 和线程 B 同时开始执行, 那么第一次都会将 count=0 读到各自的 CPU 缓 存里, 执行完 count+=1 之后, 各自 CPU 缓存里的值都是 1, 同时写入内存后, 我们会发 现内存中是 1, 而不是我们期望的 2。 之后由于各自的 CPU 缓存里都有了 count 的值, 两个线程都是基于 CPU 缓存里的 count 值来计算,所以导致最终 count 的值都是小于 20000 的。 这就是缓存的可见性问题。 循环 10000 次 count+=1 操作如果改为循环 1 亿次, 你会发现效果更明显, 最终 count 的值接近 1 亿,而不是 2 亿。 如果循环 10000 次,count 的值接近 20000,原因是两个 线程不是同时启动的,有一个时差
源头之二: 线程切换带来的原子性问题
由于 IO 太慢,早期的操作系统就发明了多进程, 即便在单核的 CPU 上我们也可以一边听着歌, 一边写 Bug, 这个就是多进程的功劳。 操作系统允许某个进程执行一小段时间, 例如 50 毫秒, 过了 50 毫秒操作系统就会重新选 择一个进程来执行(我们称为 “任务切换” ) , 这个 50 毫秒称为 “ 时间片 ” 。
在一个时间片内,如果一个进程进行一个 IO 操作, 例如读个文件, 这个时候该进程可以把自己标记为 “休眠状态” 并出让 CPU 的使用权,待文件读进内存,操作系统会把这个休眠的进程唤醒, 唤醒后的进程就有机会重新获得 CPU 的使用权了。 这里的进程在等待 IO 时之所以会释放 CPU 使用权,是为了让 CPU 在这段等待时间里可以 做别的事情,这样一来 CPU 的使用率就上来了; 此外, 如果这时有另外一个进程也读文件, 读文件的操作就会排队, 磁盘驱动在完成一个进程的读操作后, 发现有排队的任务, 就 会立即启动下一个读操作,这样 IO 的使用率也上来了。 是不是很简单的逻辑?但是,虽然看似简单,支持多进程分时复用在操作系统的发展史上却 具有里程碑意义, Unix 就是因为解决了这个问题而名噪天下
早期的操作系统基于进程来调度 CPU, 不同进程间是不共享内存空间的, 所以进程要做任 务切换就要切换内存映射地址, 而一个进程创建的所有线程, 都是共享一个内存空间的, 所 以线程做任务切换成本就很低了。 现代的操作系统都基于更轻量的线程来调度, 现在我们提 到的“任务切换”都是指“线程切换” 。 Java 并发程序都是基于多线程的, 自然也会涉及到任务切换, 也许你想不到, 任务切换竟然也是并发编程里诡异 Bug 的源头之一。 任务切换的时机大多数是在时间片结束的时候, 我们现在基本都使用高级语言编程, 高级语言里一条语句往往需要多条 CPU 指令完成, 例 如上面代码中的 count += 1 , 至少需要三条 CPU 指令:
指令 1: 首先,需要把变量 count 从内存加载到 CPU 的寄存器;
指令 2: 之后,在寄存器中执行 +1 操作;
指令 3: 最后,将结果写入内存(缓存机制导致可能写入的是 CPU 缓存而不是内存)
操作系统做任务切换, 可以发生在任何一条 CPU 指令 执行完, 是的, 是 CPU 指令, 而不 是高级语言里的一条语句。 对于上面的三条指令来说, 我们假设 count=0, 如果线程 A 在 指令 1 执行完后做线程切换, 线程 A 和线程 B 按照下图的序列执行, 那么我们会发现两个 线程都执行了 count+=1 的操作, 但是得到的结果不是我们期望的 2, 而是 1
我们潜意识里面觉得 count+=1 这个操作是一个不可分割的整体,就像一个原子一样, 线程的切换可以发生在 count+=1 之前, 也可以发生在 count+=1 之后, 但就是不会发生在 中间。 我们把一个或者多个操作在 CPU 执行的过程中不被中断的特性称为原子性 。 CPU 能保证的原子操作是 CPU 指令级别的, 而不是高级语言的操作符, 这是违背我们直觉的地方。 因此很多时候我们需要在高级语言层面保证操作的原子性。
源头之三: 编译优化带来的有序性问题
那并发编程里还有没有其他有违直觉容易导致诡异 Bug 的技术呢?有的,就是有序性。 顾名思义, 有序性指的是程序按照代码的先后顺序执行。 编译器为了优化性能, 有时候会改变程序中语句的先后顺序, 例如程序中: “a=6; b=7; ” 编译器优化后可能变成“b=7; a=6; ” ,在这个例子中, 编译器调整了语句的顺序, 但是不影响程序的最终结果。 不过有时候编译器及解释器的优化可能导致意想不到的Bug。 在 Java 领域一个经典的案例就是利用双重检查创建单例对象
总结
要写好并发程序,首先要知道并发程序的问题在哪里, 只有确定了“靶子” ,才有可能把问题解决, 毕竟所有的解决方案都是针对问题的。 并发程序经常出现的诡异问题看上去非常无厘头, 但是深究的话,无外乎就是直觉欺骗了我们,只要我们能够深刻理解可见性、 原子性、有序性在并发场景下的原理,很多并发 Bug 都是可以理解、 可以诊断的
在介绍可见性、 原子性、 有序性的时候, 特意提到缓存导致的可见性问题,线程切换带来的原子性问题, 编译优化带来的有序性问题, 其实缓存、 线程、 编译优化的目的和我们写并发程序的目的是相同的,都是提高程序性能。但是技术在解决一个问题的同时, 必然会带来另外一个问题, 所以在采用一项技术的同时,一定要清楚它带来的问题是什么,以及如何规避 。 我们这个专栏在讲解每项技术的时候, 都会尽量将每项技术解决的问题以及产生的问题讲清楚,也希望你能够在这方面多思考、多总结。
课后思考
常听人说, 在 32 位的机器上对 long 型变量进行加减操作存在并发隐患,到底是不是这样呢? 现在相信你一定能分析出来