论文笔记NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
NeRF使用神经网络来表示场景。给定一个场景,输入该场景稀疏的视角图片,NeRF可以合成该场景新的视角的图片。

神经辐射场
神经辐射场(neural radiance field,NeRF)使用5D的向量值函数表示一个场景。
输入是连续的5D坐标(包括位置x=(x,y,z)\mathbf x = (x,y,z)x=(x,y,z)和视角方向d=(θ,ϕ)\mathbf d = (\theta, \phi)d=(θ,ϕ)),输出是发光颜色c=(r,g,b)\mathbf c = (r, g, b)c=(r,g,b)和体积密度σ\sigmaσ。
具体地,用一个全连接网络近似这个场景,也就是学习 FΘ:(x,d)→(c,σ)F_{\Theta}:(\mathbf x, \mathbf d) \rightarrow (\mathbf c, \sigma)FΘ:(x,d)→(c,σ)。
作者鼓励让体积密度只依赖于位置。所以网络结构是先输入位置x\mathbf xx,输出σ\sigmaσ和一个特征向量。之后将特征向量和视角方向拼接,最后映射到c\mathbf cc颜色。
注意不同的场景需要训练不同的NeRF。
位置编码
在将输入传递到网络之前,使用高频函数将输入映射到更高维空间可以更好地拟合包含高频变化的数据。类似Transformer,作者提出将x,d\mathbf x, \mathbf dx,d映射到高维空间中,再输入网络。
![]()
使用辐射场进行立体渲染
为了配合辐射场,作者采用立体渲染(volume rendering)方法渲染图像。
关于立体渲染可以参考 https://zhuanlan.zhihu.com/p/595117334
体积密度σ(x)\sigma(\mathbf x)σ(x)可以解释为光线在位置x\mathbf xx处终止于无穷小粒子的微分概率。
立体渲染中,相机光线r(t)=o+td\mathbf r(t) = \mathbf o + t\mathbf dr(t)=o+td在范围[tn,tf][t_n, t_f][tn,tf]的期望颜色C(r)C(\mathbf r)C(r)如下计算:
C(r)=∫tntfT(t)σ(r(t))c(r(t),d)dtwhereT(t)=exp(−∫tntσ(r(s))ds)C(\mathbf r) = \int_{t_n}^{t_f} T(t) \sigma(\mathbf r(t)) \mathbf c(\mathbf r(t), \mathbf d) dt \\ where~~ T(t) = \exp(-\int_{t_n}^t \sigma(\mathbf r(s))ds) C(r)=∫tntfT(t)σ(r(t))c(r(t),d)dtwhere T(t)=exp(−∫tntσ(r(s))ds)从连续的神经辐射场渲染一个视角,需要追踪所需虚拟相机的相机光线上的每个像素,来估计积分C(r)C(\mathbf r)C(r)。
上面公式的积分实际中用数值方法计算。如果固定在某些点采样计算积分,会限制表示的分辨率。为了解决这个问题,作者提出使用分层采样(stratified sampling)的方法。首先将[tn,tf][t_n, t_f][tn,tf]平分成N个大小一样的桶,然后在每个桶中采样一个样本:
ti∼U[tn+i−1N(tf−tn),tn+iN(tf−tn)]t_i \sim \mathcal U [t_n + \frac{i-1}{N}(t_f - t_n), t_n + \frac{i}{N}(t_f - t_n)] ti∼U[tn+Ni−1(tf−tn),tn+Ni(tf−tn)]虽然采样的样本还是离散的,但是优化过程是循环的,需要进行多次采样,每次采样可以采样到不同的位置,所以相当于在连续的位置优化。用采样的样本估计C(r)C(\mathbf r)C(r)的方法如下:
C^(r)=∑iNTi(1−exp(−σiδi))ciwhereTi=exp(−∑j=1i−1σjδj)\hat C(\mathbf r) = \sum_{i}^{N} T_i (1-\exp(-\sigma_i \delta_i)) \mathbf c_i \\ where~~ T_i = \exp(- \sum_{j=1}^{i-1} \sigma_j \delta_j) C^(r)=i∑NTi(1−exp(−σiδi))ciwhere Ti=exp(−j=1∑i−1σjδj)其中δi=ti+1−ti\delta_i = t_{i+1} - t_iδi=ti+1−ti。这个估计C(r)C(\mathbf r)C(r)的方法是可导的,所以可以方便的优化参数。
Hierarchical立体采样
如果沿每个相机光线的 N 个查询点密集地计算NeRF的值,这样的渲染策略是效率低下的,因为对渲染图像没有贡献的自由空间和遮挡区域会被重复采样。
为了解决这个问题,作者提出训练两个网络,一个是粗粒度(coarse)的,一个细粒度(fine)的。首先对粗粒度网络分层采样NcN_cNc个点,然后计算C^c(r)\hat{C}_c(\mathbf r)C^c(r)。
 标准化w^i=wi∑jwj\hat{w}_i=\frac{w_i}{\sum_j w_j}w^i=∑jwjwi得到一个概率密度函数。根据这个分布,采样得到NfN_fNf个点。再使用细粒度网络计算这Nc+NfN_c + N_fNc+Nf个点的颜色C^f(r)\hat{C}_f(\mathbf r)C^f(r)。这样的方式可以对可见部分采样更多的点。
标准化w^i=wi∑jwj\hat{w}_i=\frac{w_i}{\sum_j w_j}w^i=∑jwjwi得到一个概率密度函数。根据这个分布,采样得到NfN_fNf个点。再使用细粒度网络计算这Nc+NfN_c + N_fNc+Nf个点的颜色C^f(r)\hat{C}_f(\mathbf r)C^f(r)。这样的方式可以对可见部分采样更多的点。
损失函数
损失函数是渲染像素和真实像素的平方误差:
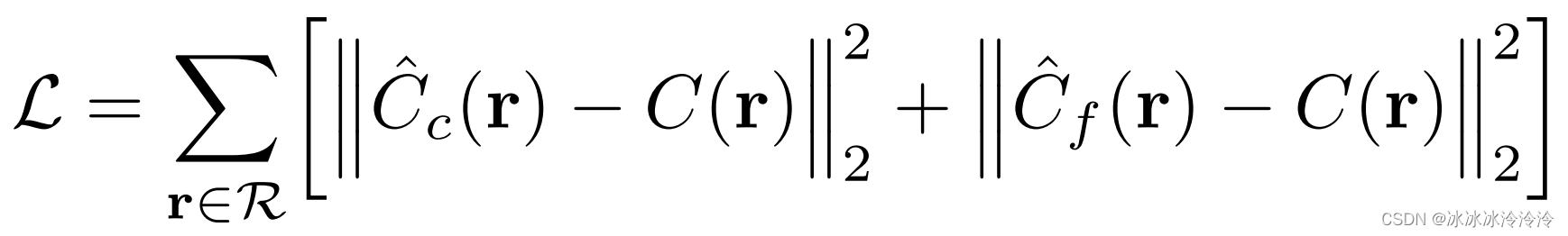
其中R\mathcal RR是一个batch的光线集合。
在训练的每个循环中,从像素中随机采样一个batch的相机光线。
虽然最后渲染的图像由细粒度网络产生,但是粗粒度网络同样需要训练。