opencv+python物体检测【03-模仿学习】
仿照练习:原文链接
步骤一:准备图片
正样本集:正样本集为包含“识别物体”的灰度图,一般大于等于2000张,尺寸不能太大,尺寸太大会导致训练时间过长。
负样本集:负样本集为不含“识别物体”的任何图片,一般大于等于5000张,尺寸比正样本集稍大。一般为正样品集的3倍。
效果:
需要识别的物体称为正样本集,不含该物体称为负样本集
正样本集:20张

负样本集:60张
步骤二:图片预处理
统一大小
统一改为灰度图
处理后正样本集:

处理后负样本集:

步骤三:生成描述文件(.txt文件)
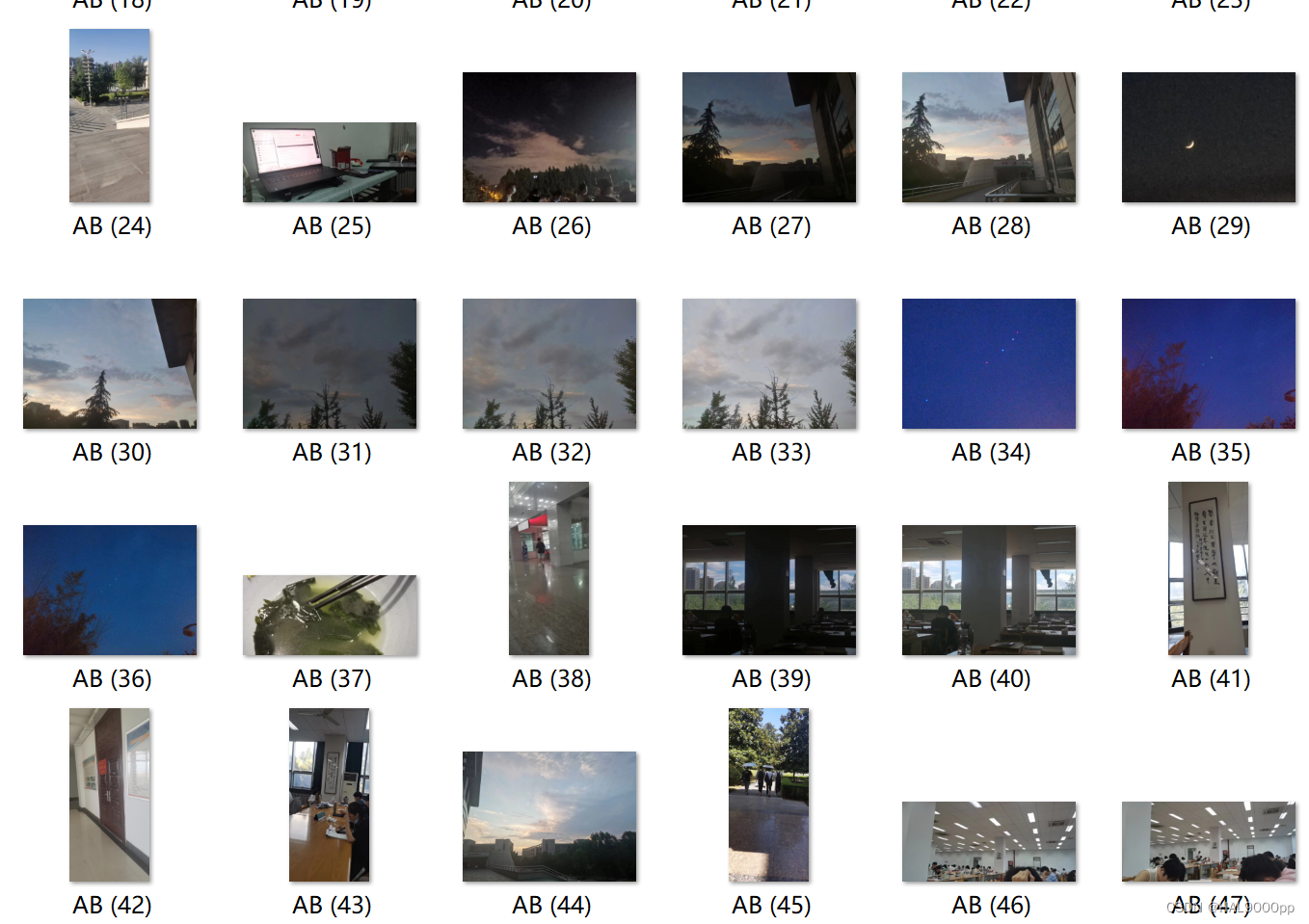
正样本描述文件:
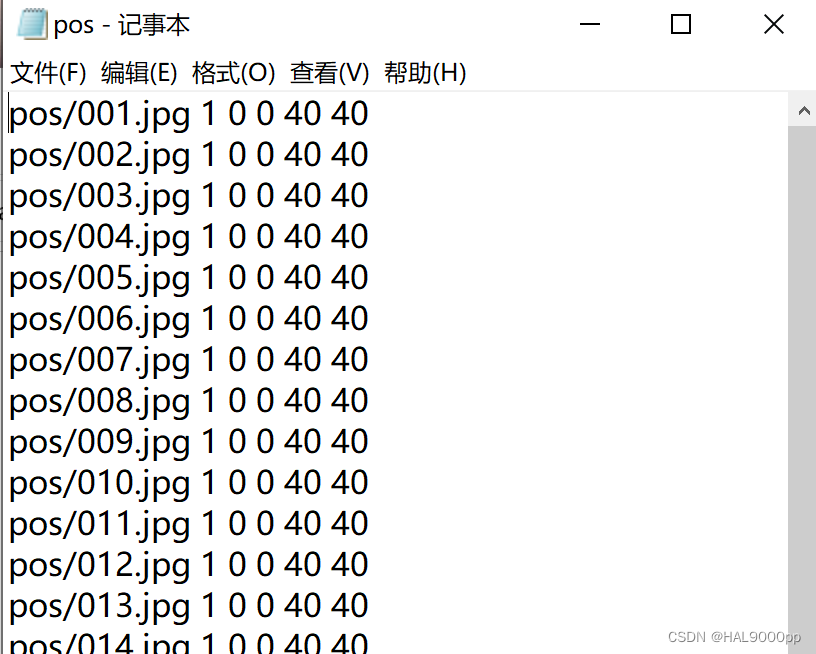
负样本描述文件:
步骤四:生成.vec文件
在该主目录文件下打开终端窗口
.\opencv_createsamples.exe -info pos.txt -vec detect_number.vec -bg neg.txt -num 19 -w 40 -h 40
-info 正样本txt
-vec 是你生成vec文件的位置和名称
-bg 负样本txt
-num 正样本数量
-w 正样本宽度
-h 正样本高度
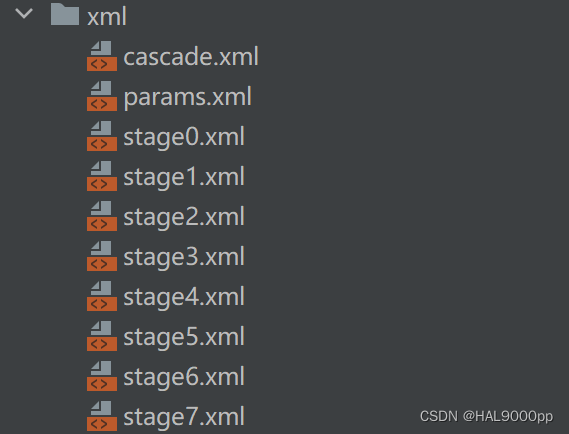
步骤五:生成自定义分类器文件(.xml)
在该主目录文件下打开终端窗口
./opencv_traincascade.exe -data xml -vec detect_number.vec -bg neg.txt -numPos 19 -numNeg 25 -numStages 20 -featureType HAAR -w 40 -h 40
-data 前面创建好的xml文件夹
-vec 是你之前生成vec文件
-bg 负样本集txt
-numPos 正样本的数量
-numNeg 负样本的数量
-numStages 训练步数
-featureType 特征类型
训练时,提取图像特征的类型,目前只支持LBP、HOG、Haar三种特征。但是HAAR训练非常非常的慢,而LBP则相对快很多,因为HAAR需要浮点运算,精度自然比LBP更高
-w -h 正样本的宽高
步骤六:识别检测
训练集路径:./xml/cascade.xml
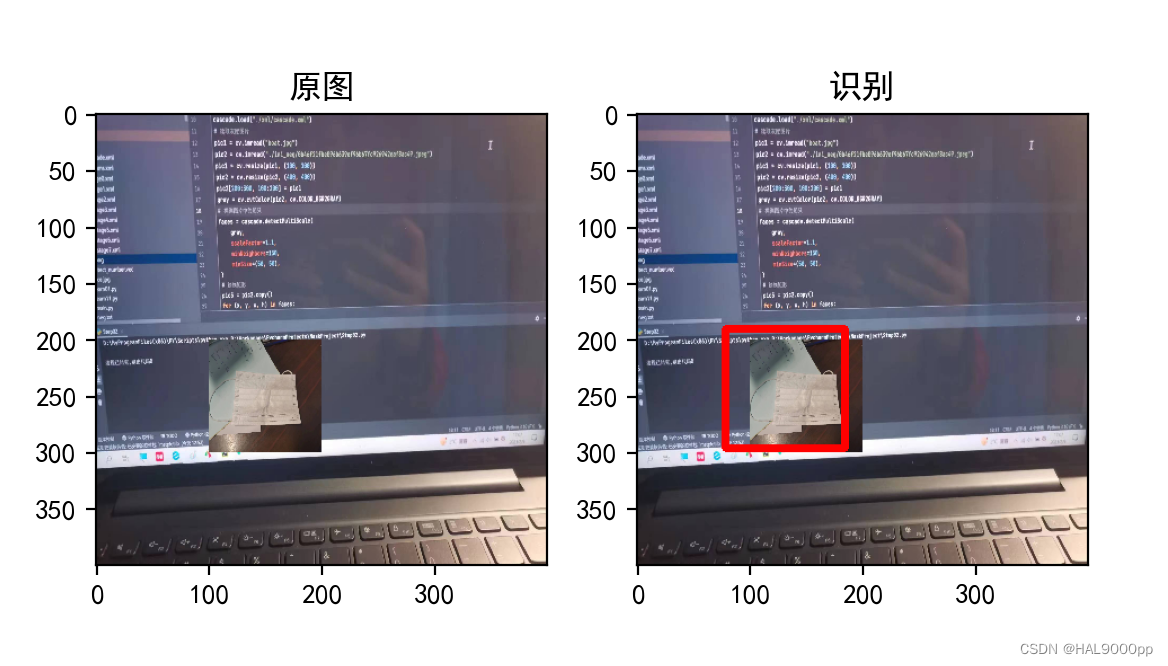
代码部分::
import cv2 as cv
import osfrom matplotlib import pyplot as plt# 解决中文显示问题,固定格式
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = Falsepospath = "./ini_pos" # 正样本集文件夹路径
pos = os.listdir(pospath) # 读取路径下的所有文件
negpath = "./ini_neg"
neg = os.listdir(negpath)# 图片处理,注意图片不能有gif格式
def picdif():global pos, negi = 1for picname in pos: # 遍历pos文件数组所有的文件名# 读取灰度图pic = cv.imread(pospath + "\\" + picname)pic = cv.cvtColor(pic, cv.COLOR_BGR2GRAY)# 修改尺寸pic = cv.resize(pic, (40, 40))# 保存图片cv.imwrite("./pos/" + str("%03d" % i) + ".jpg", pic)i += 1# 同理对负样本集进行处理j = 1for picname in neg: # 遍历neg文件数组所有的文件名# 读取灰度图pic = cv.imread(negpath + "\\" + picname)pic = cv.cvtColor(pic, cv.COLOR_BGR2GRAY)# 修改尺寸pic = cv.resize(pic, (50, 50))# 重命名,并保存图片cv.imwrite("./neg/" + str("%03d" % j) + ".jpg", pic)j += 1# 描述文件生成
def createtxt():global pos, neg# 正样本描述文件:for picname in pos:line = "pos/" + picname + " 1 0 0 40 40" + "\n" # "1"为图片数量(0,0)是坐标,(40,40)是正样本集的w,hwith open('pos.txt', 'a') as f:f.write(line)# 负样本描述文件:for picname in neg:line = "neg/" + picname + "\n" # (0,0)是坐标,(40,40)是正样本集的w,hwith open('neg.txt', 'a') as f:f.write(line)if __name__ == '__main__':# 1.导入文件夹,对图像统一处理,统一尺寸大小,统一灰度图picdif()# pos和neg改成处理后的图片文件夹;pospath = "./pos" # 正样本集文件夹路径pos = os.listdir(pospath) # 读取路径下的所有文件negpath = "./neg"neg = os.listdir(negpath)# 2.正负样本描述文件的生成createtxt()
import cv2 as cv
import matplotlib.pyplot as plt# 解决中文显示问题,固定格式
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 加载分类器
cascade = cv.CascadeClassifier("./xml/cascade.xml")
cascade.load("./xml/cascade.xml")
# 读取灰度图片
pic1 = cv.imread("1.jpg")
pic2 = cv.imread("0.jpg")
pic1 = cv.resize(pic1, (100, 100))
pic2 = cv.resize(pic2, (400, 400))
pic2[200:300, 100:200] = pic1
gray = cv.cvtColor(pic2, cv.COLOR_BGR2GRAY)
# 探测图片中的船只
faces = cascade.detectMultiScale(gray,scaleFactor=1.1,minNeighbors=150,minSize=(50, 50),
)
# 绘制矩形
pic3 = pic2.copy()
for (x, y, w, h) in faces:cv.rectangle(pic3, (x, y), (x + h, y + w), (0, 0, 255), 5)
# 绘图
fig, axes = plt.subplots(nrows=1, ncols=2)
axes[0].imshow(pic2[:, :, ::-1])
axes[0].set_title("原图")
axes[1].imshow(pic3[:, :, ::-1])
axes[1].set_title("识别")plt.show()
cv.waitKey()