shell学习4
目录
一、统计文本中的词频
二、压缩javascript
三、打印文件的或行中的第n个单词或列---awk
3.1 利用awk打印文件中每行中的第五个单词。
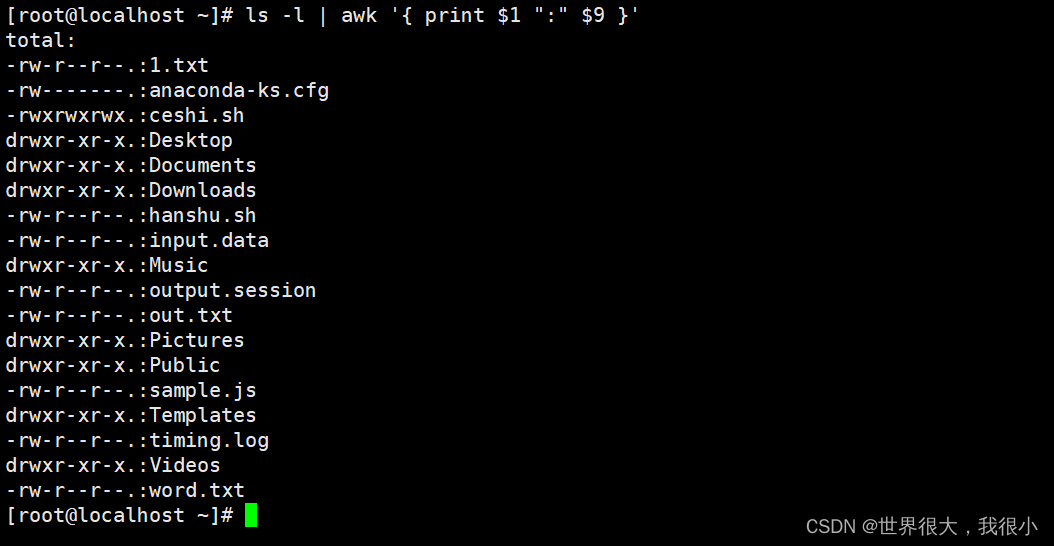
3.2 利用awk打印当前目录下的文件的权限和文件名
3.3 利用awk打印从M行到N行这个范围内的所有文本
3.4 利用awk 部分提取文件中的内容
3.5 利用awk 逆序打印
四、解析文本中的电子邮件地址和URL---egrep
五、在文件中移除包含某个单词的句子---sed
5.1 删除包含“mobile phones” 的句子
5.2 对目录中的所有文件进行文本替换
一、统计文本中的词频
#!/bin/bash
if [ $# -ne 1 ];
then
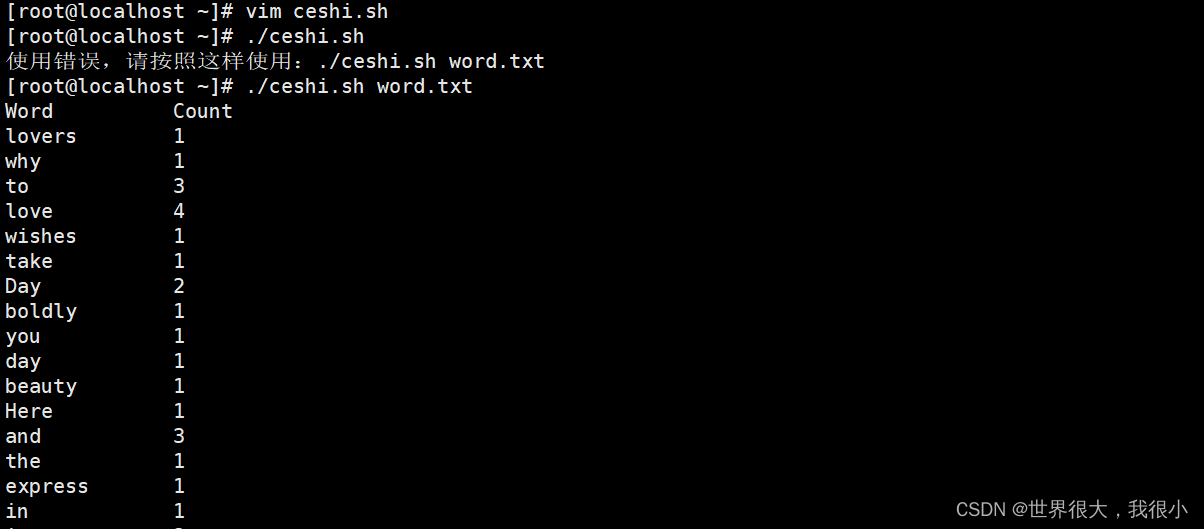
echo "用法错误,请按照这样使用:./ceshi.sh word.txt";
exit -1
fi
filename=$1
egrep -o "\b[[:alpha:]]+\b" $filename | \
awk '{ count[$0]++ }
END{ printf("%-14s%s\n","Word","Count") ;
for(ind in count)
{ printf("%-14s%d\n",ind,count[ind]); }
}'
①[ $# -ne 1 ] : 如果传递给脚本的参数不是1
②$1传递给脚本的第一个参数,$0就是脚本本身
③-o 表示只匹配本身。
egrep -o "\b[[:alpha:]]+\b" $filename 只用于输出单词。用 -o 选项打印出由换行符分隔的匹配字符序列。这样我们就可以在每行中列出一个单词。
\b 是单词边界标记符。 [:alpha:] 是表示字母的字符类。 awk 命令用来避免对每一个单词
进行迭代。因为 awk 默认会逐行执行 {} 块中的语句,所以我们就不需要再为同样的事编写循环了。
借助关联数组,当执行 count[$0]++ 时,单词计数就增加。最后,在 END{} 语句块中通过迭代所有的单词,就可以打印出单词及它们各自出现的次数。
二、压缩javascript
cat sample.js | tr -d '\n\t' | tr -s ' ' | sed 's:/\*.*\*/::g' | sed 's/ \?\([{}();,:]\) \?/\1/g'
tr -s 删除所有重复出现的字符序列
tr -d 删除字符串中出现的所有字符
tr -d '\n\t' :移除 '\n' 和 '\t'
tr -s ' ':移除多余的空格
sed 's:/\*.*\*/::g':移除注释
因为我们需要使用 /* 和 */ ,所以用 : 作为 sed 的定界符,这样就不必对 / 进行转
义了。
* 在 sed 中被转义为 \* 。
.* 用来匹配 /* 与 */ 之间所有的文本。
sed 's/ \?\([{}();,:]\) \?/\1/g' :移除 { 、 } 、 ( 、 ) 、 ; 、 : 以及 , 前后的空格。(去掉标红符号前后的空格)
sed 代码中的 / \?\([{ }();,:]\) \?/ 用于匹配, /\1/g 用于替换。
\([{ }();,:]\) 用于匹配集合 [ { }( ) ; , : ] (出于可读性方面的考虑,
在这里加入了空格)中的任意一个字符。 \( 和 \) 是分组操作符,用于记忆所匹配的
内容,以便在替换部分中进行向后引用。对 ( 和 ) 转义之后,它们便具备了另一种特
殊的含义,进而可以将它们作为分组操作符。位于分组操作符前后的 \? 用来匹配
可能出现在字符集合前后的空格。
在命令的替换部分,匹配字符串(也就是一个可选的空格、一个来自字符集的字
符再加一个可选的空格)被匹配的子字符串所替换。对于匹配的子字符串使用了
向后引用,并通过分组操作符 () 记录了匹配内容。可以用符号 \1 向后引用分组
所匹配的内容。
三、打印文件的或行中的第n个单词或列---awk
3.1 利用awk打印文件中每行中的第五个单词。

3.2 利用awk打印当前目录下的文件的权限和文件名
3.3 利用awk打印从M行到N行这个范围内的所有文本

3.4 利用awk 部分提取文件中的内容

3.5 利用awk 逆序打印
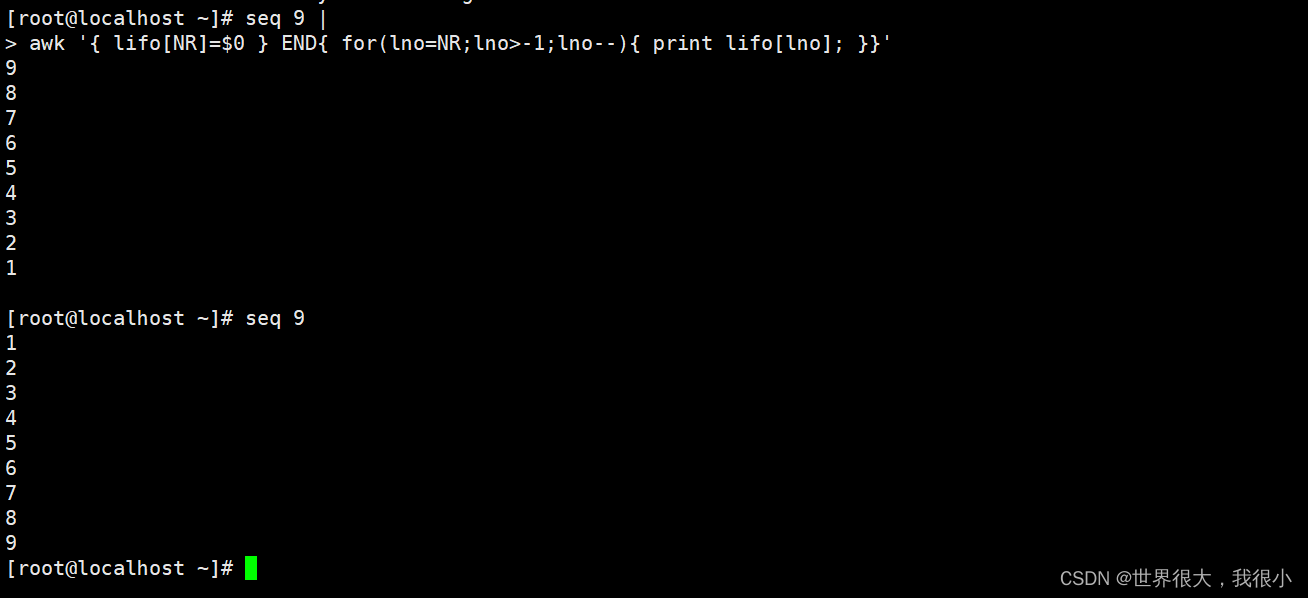
NR:是总共读取了多少行
这个 awk 脚本非常简单。我们将每一行都存入一个关联数组中,用行号作为数组索引(行
号由 NR 给出),最后由 awk 执行 END 语句块。为了得到最后一行的行号,在 { } 语句块中使用
lno=NR 。因此,这个脚本从最后一行一直迭代到第0行,将存储在数组中的各行以逆序方式
打印出来。
四、解析文本中的电子邮件地址和URL---egrep

电子邮件:

URL:

因为用到了扩展正则表达式(例如+),所以得使用 egrep 命令
. 匹配任意一个字符
\. 用来匹配点字符,而不是任何字符的通配符。
[a-zA-Z]{2,4} 表示字母的长度应该在2到4之间(包括2和4)。eg:cn、com、edu
五、在文件中移除包含某个单词的句子---sed
5.1 删除包含“mobile phones” 的句子
文本内容要保证在在同一行。


该正则表达式的格式为: 's/ 匹配模式/替代字符串 /g' 。
这里的匹配模式是用来匹配整句文本的正则表达式。文件中的每一句话第一个字符都是空
格,句与句之间都以“ . ”来分隔。因此我们需要匹配内容的格式就是:空格+若干文本+需要匹
配的字符串+若干文本+句点。一个句子除了作为定界符的句点之外,可以包含任意字符。因此我
们要使用 [^.] 。 [^.]* 可以匹配除句点之外的任何字符的组合。用来匹配文本的“mobile phone”
被放置在两个 [^.]* 之间。每一个匹配的句子均被 // 替换(注意, / 与 / 之间没有任何内容)。
5.2 对目录中的所有文件进行文本替换
将所有.cpp文件中的 Copyright 替换成 Copyleft.
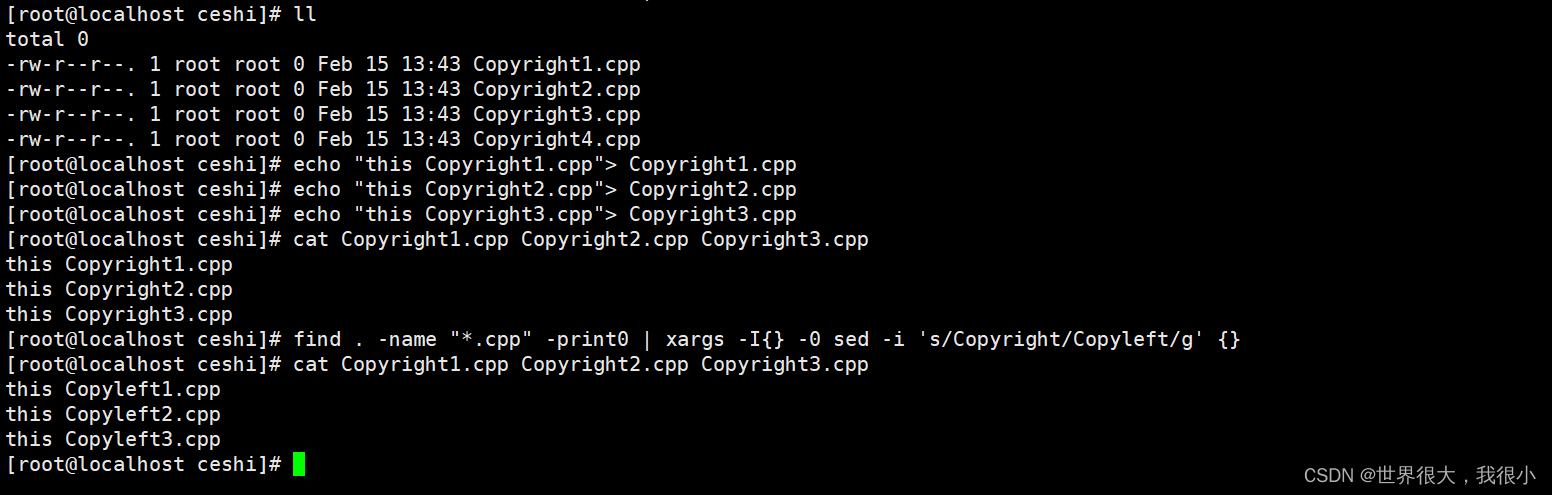
我们使用 find 在当前目录下查找所有的.cpp文件,然后使用 print0 打印出以null字符( \0 )作为分隔符的文件列表。(这可以避免文件名中的空格所带来的麻烦。)接着使用通道将列表传递
给 xargs ,后者将对应的文件作为 sed 的参数,由 sed 对文件内容进行修改。