ccc-Tips for Deep Learning-李宏毅(8)
文章目录
- Recipe of Deep Learning
- Good Results on Training Data
- New activation function
- Adaptive Learning Rate
- Good Results on Testing Data
- Early Stopping
- Regularization
- Dropout
- why Dropout work?
- Reason for bias&variance
- Dropout is a kind of ensemble
Recipe of Deep Learning
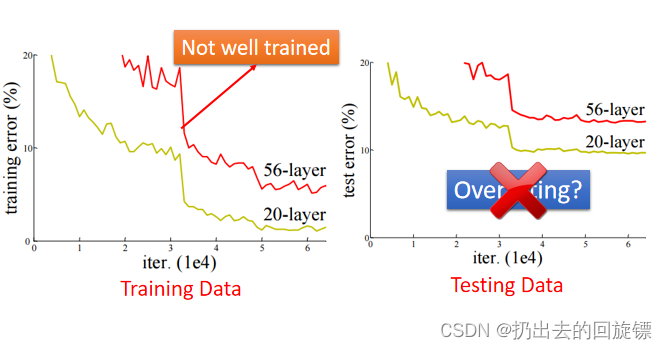
Do not always blame overfitting
对于DL模型而言,测试集效果不好不一定是overfitting,可能和训练方式和模型结构有关,下图就是一个56层神经网络在测试集和训练集效果都不如26层的例子:
Good Results on Training Data
New activation function
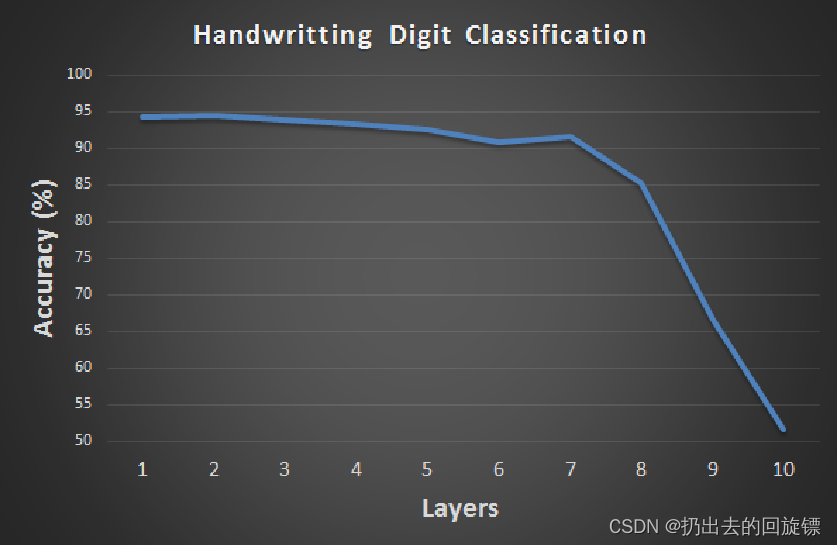
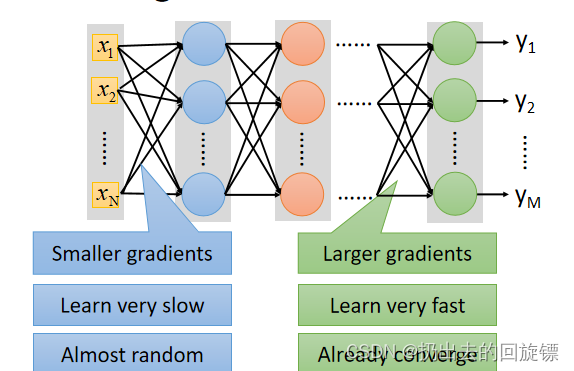
当model使用sigmoid这个激活函数时会出现层数增加准确率反而减小的问题,问题来源是vanishing gradient problem(梯度消失)
vanishing gradient problem
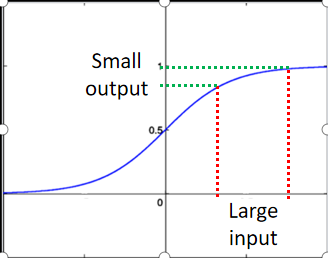
图像中可以看到,输入的差值在经过sigmoid函数后会被缩小,这也导致model很深的时候,靠近input参数对于损失函数的影响很小(Backpropagation反向),而靠近output时梯度update确很快。所以导致训练结束时,前面的参数还是未收敛的random状态,形象解释如下:
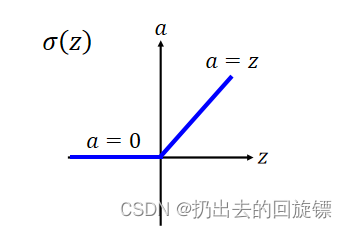
Rectified Linear Unit (ReLU)
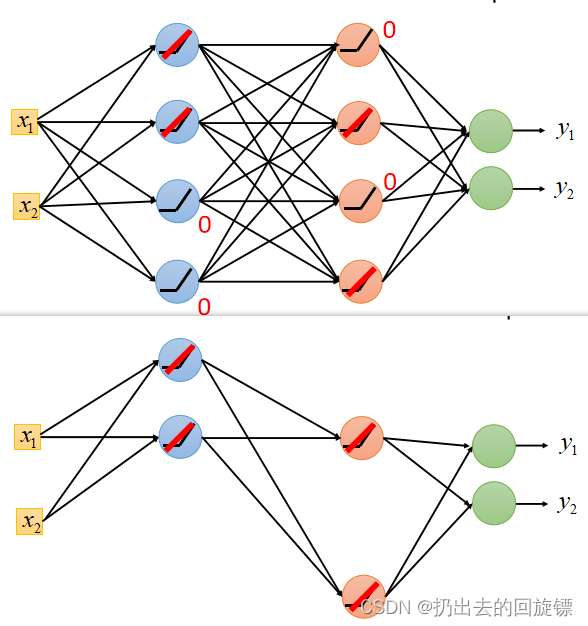
特点如下:
- 解决梯度消失问题
- 相当于无数bias不同的sigmoid叠加
- 计算快
- 使网络变得thinner
- 单个神经元是线性的,但整体网络还是非线性
- 直接放弃输出为0的neural
操作示意图如下:
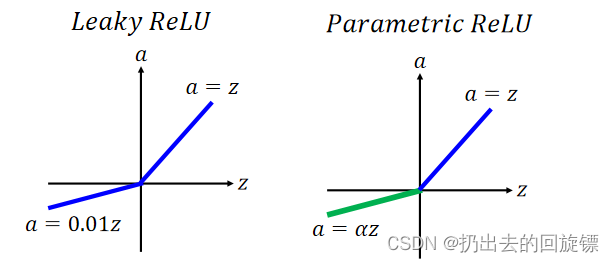
ReLU - variant
大同小异,为了让0的那部分更加合理,有东西可学
Maxout
就是对于同一组输出选最大的当作下一组输入,示意图如下:
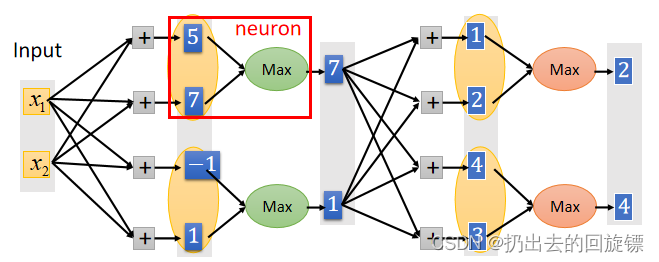
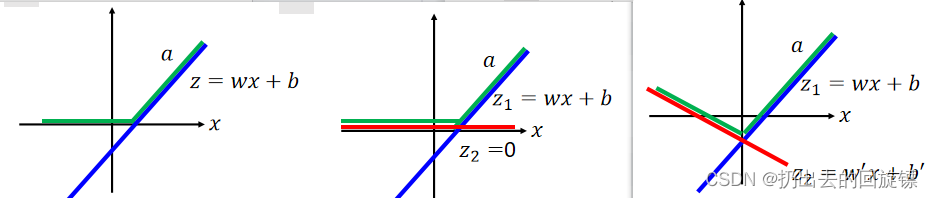
它相当于ReLU 的普遍状态,状态图(2 elements)如下:
Adaptive Learning Rate
这些优化算法在之前的文章有过更加详细全面的讲解
Good Results on Testing Data
Early Stopping
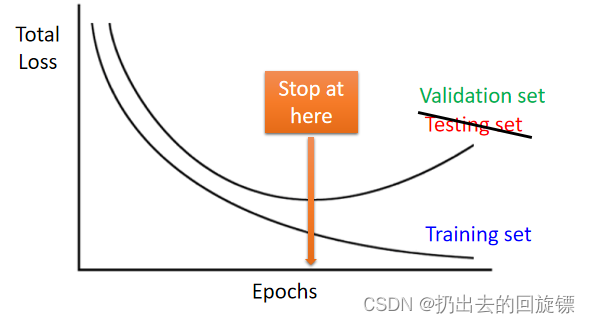
“testing set”效果最好时手动停止训练,这里的“testing set”指validation set模拟的testing set
Regularization
目的是让objective function平滑,通常去掉bias后效果更好
L2 regularization

ηλ\eta \lambdaηλ这项是很小的正数,最后会使参数wnw^nwn接近0 ,L2 regularization可以让weight每次都变得更⼩⼀点(由于第二项的存在,不会为0)也称Weight Decay(权重衰减)
L1 regularization
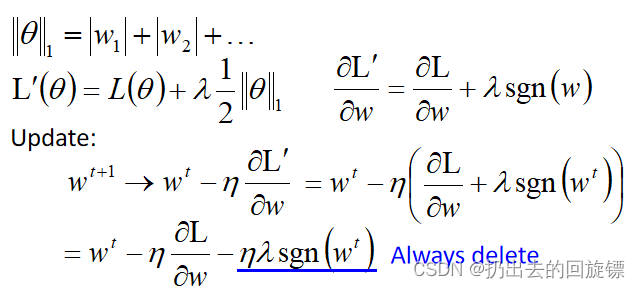
也是让参数变小,不过是通过减去ηλsgn(wt)\eta \lambda sgn(w^t)ηλsgn(wt)来使得绝对值靠近0
L1 V.s. L2
- 参数w的绝对值⽐较⼤的时候,L2下降得更快
- L1 training 出来的model,参数会有很大的值
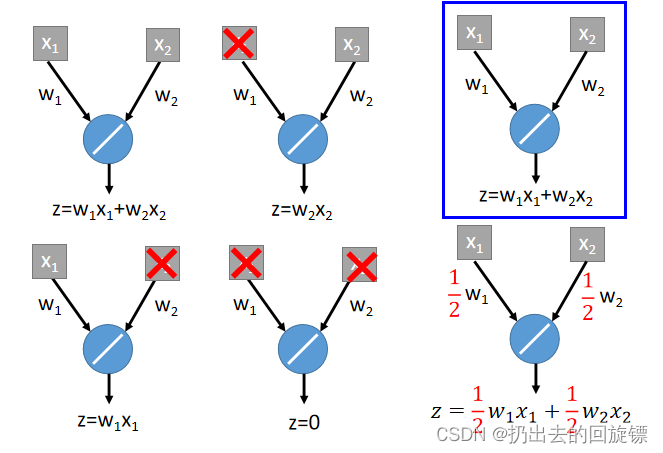
Dropout
在training时,每一个Neuron都有机率p完全失效,得到thinner 的network;
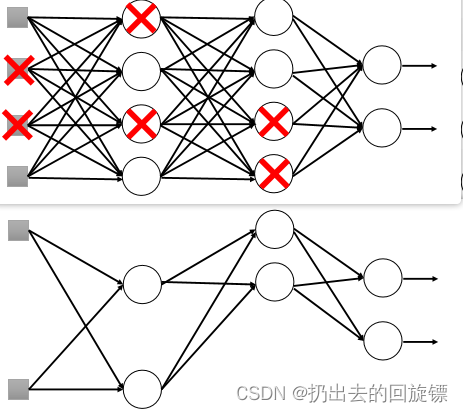
testing时将weight乘(1-p),不需要dropout。之所以乘(1-p)中和未失效结点与失效结点的关系
why Dropout work?
Reason for bias&variance
复杂的model,bias小而variance大。多个复杂的model结合计算平均,可能使variance减小
Dropout is a kind of ensemble
对于M个neurons,使用Dropout 方式就有2M2^M2M可能的network;对这样多的minibatch计算平均结果是非常困难的,但testing时将weight乘(1-p)可以很大程度上估计它,原理示意如下:
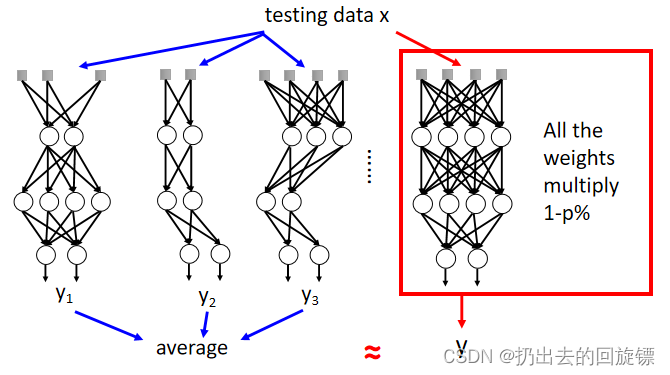
形象解释如下: