链式哈希,一致性哈希,倒排表
在普通的查询中,通过关键码的比较进行查找,而哈希是根据关键码直接定位到数据项
哈希冲突:同一个关键码经过哈希函数后指向同一个记录集
链式哈希
using namespace std;
#define M 13
typedef int KeyType;
//typedef struct
//{
// KeyType key;
// Record recptr;
//}Elemtype;
typedef struct HashNode
{HashNode* next;KeyType key;
} HashNode;
typedef struct
{HashNode* data[M];int cursize;
}HashTable;
HashNode* BuyNode()
{HashNode* s = (HashNode*)calloc(1, sizeof(HashNode));if (s == nullptr)exit(1);return s;
}
void FreeNode(HashNode*p)
{free(p);
}
void InitHashTable(HashTable* pht)
{assert(pht != nullptr);pht->cursize = 0;for (int i = 0; i < M; i++){pht->data[i] = 0;}
}
int Hash(KeyType kx)
{return kx % M;
}
bool Insert(HashTable* pht, KeyType kx)
{assert(pht != nullptr);int pos = Hash(kx);HashNode* p = pht->data[pos];while (p != nullptr && p->key != kx){p = p->next;}if (p != nullptr) return false;HashNode* s = BuyNode();s->key = kx;s->next = pht->data[pos];pht->data[pos] = s;pht->cursize += 1;return true;
}
void PrintHashTable(HashTable* pht)
{assert(pht != nullptr);for (int i = 0; i < M; i++){cout << "桶编号:" << i << "->" << " ";HashNode* p = pht->data[i];while (p != nullptr){cout << p->key << " ";p = p->next;}cout << endl;}
}
int main()
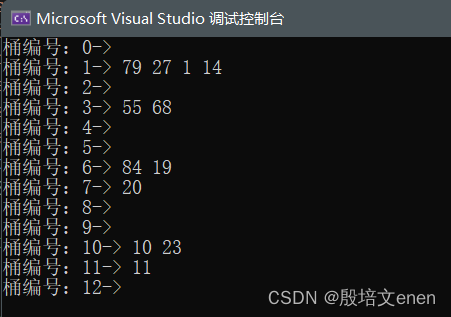
{KeyType ar[] = { 19,14,23,1,68,20,84,27,55,11,10,79};int n = sizeof(ar) / sizeof(ar[0]);HashTable ht;InitHashTable(&ht);for (int i = 0; i < n; i++){Insert(&ht, ar[i]);}PrintHashTable(&ht);
}结果:
删除
bool Remove(HashTable* pht, const KeyType kx)
{if (pht == nullptr) { return false; }int pos = Hash(kx);HashNode* p = pht->data[pos];HashNode* ptr = nullptr;while (p != nullptr && p->key != kx){ptr = p;p = p->next;}if (p == nullptr) { return false; }if (ptr == nullptr){pht->data[pos] = p->next;free(p);p = nullptr;}else{ptr->next = p->next;free(p);p = nullptr;}pht->cursize -= 1;return true;
}一致性哈希
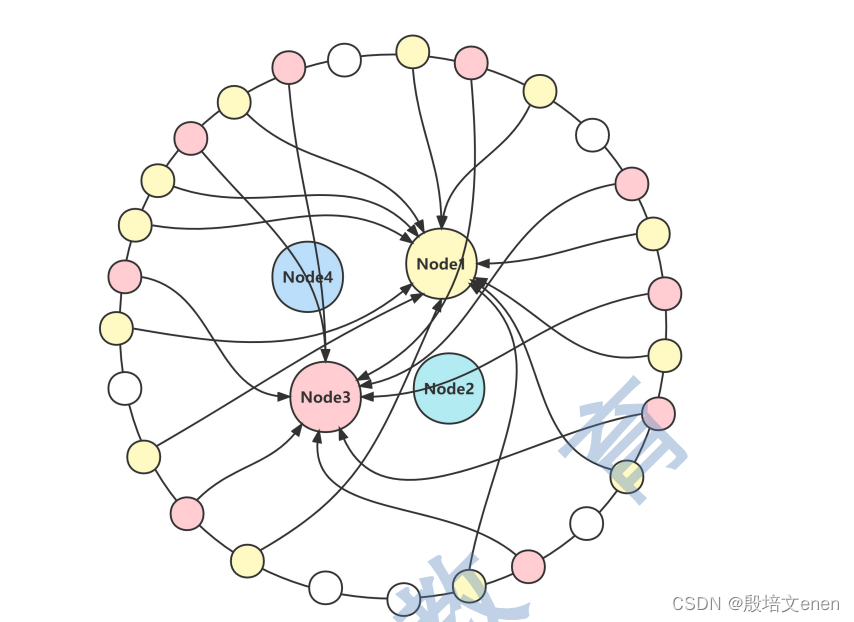
采用虚拟节点的方式,解决了添加和删除物理节点时,资源分配会不均匀的问题。
倒排表
到排表是搜索引擎的核心架构
假设我们爬取了4个文档,里面的内容如下

基于4个文档,写出我们的词库 [我们,今天,运动,昨天,上,课,什么]
统计词库中的每个单词出现在哪些文档中,显然 我们 出现在[doc1,doc2] 中
这样我们就可以把文档以到排表的方式存储了,这样做有什么优点呢???
假如用户输入:我们 上课
如果没有到排表,则只能一篇一篇的去搜索文档中 是否既包含我们又包含上课,这样复杂度太高了
有了到排表:我们知道 我们[Doc1, Doc2], 上 [ Doc3,Doc4], 课[Doc3,Doc4], 如果有交集,我们可以直接返回交集,如果没有交集,那么直接返回
并集[ Doc1,Doc2, Doc3,Doc4]
倒排的优缺点和正排的优缺点整好相反。
所有正排的【优点】易维护;【缺点】搜索的耗时太长。
倒排【缺点】在构建索引的时候较为耗时且维护成本较高;【优点】搜索耗时短(在处理复杂的多关键字查询时,可在倒排表中先完成查询的交、并等逻辑运算,得到结果后再对记录进行存取。这样不必对每个记录随机存取,把对记录的查询转换为地址集合的运算,从而提高查找速度)。
template<class TKey = std::string>
class InvIndex : public map<TKey, list<int>>
{
public:vector<vector<TKey>> docs;
public:void add(vector<TKey>& doc){docs.push_back(doc);int curDocID = docs.size();for (int i = 0; i < doc.size(); i++){typename map<TKey, list<int> >::iterator it;it = this->find(doc[i]);if (it == this->end()){list<int> newlist;(*this)[doc[i]] = newlist;it = this->find(doc[i]);}it->second.push_back(curDocID);}}
};
int main()
{string d1_tmp[] = { "杨和平","按泽鹏","殷培文","谢家桥","释小龙" };int n = sizeof(d1_tmp) / sizeof(d1_tmp[0]);vector<string>d1(d1_tmp, d1_tmp + n);string d2_tmp[] = { "杨和平","里加长","房价想","谢家桥","冬温慧" };n = sizeof(d2_tmp) / sizeof(d2_tmp[0]);vector<string>d2(d2_tmp, d2_tmp + n);string d3_tmp[] = { "释小龙","按泽鹏","殷培文","里加长","样变变" };n = sizeof(d3_tmp) / sizeof(d3_tmp[0]);vector<string>d3(d1_tmp, d1_tmp + n);string d4_tmp[] = { "杨和平","房价想","殷培文","谢家桥","作结" };n = sizeof(d4_tmp) / sizeof(d4_tmp[0]);vector<string>d4(d4_tmp, d4_tmp + n);std::shared_ptr<InvIndex<string>>inv(new InvIndex<string>());inv->add(d1);inv->add(d2);inv->add(d3);inv->add(d4);return 0;
}