concurrenthashmap
SizeCtl的用法
sizeCtl=0或容量大小 (二个构造方法)
sizeCtl>0(初始化或扩容后)扩容阈值
sizeCtl=-1:正在初始化中
sizeCtl<-1:线程扩容中
知道为什么第一个线程扩容时+2,后面的其他线程扩容+1(每加一次,代表新增一个线程扩容)
因为sizeCtl=-1代表初始化
binCount用法
链表,当前桶 高 binCount++
红黑树:2
rs
resizeStamp( ):盖扩容戳
见:https://blog.csdn.net/weixin_42169336/article/details/121133677
我理解的,先计算前面有多少个0,然后转成进行或运算(高16位0,低16位的第一位是1),
然后左移16位,这样就很明确了。
即高18位标记:迁移动作+容量标记,低16位,即线程数(每个线程如果要迁移,则加1)
后面有反操作,如果线程完成迁移的话,则会减1,所有线程减完,等到这个戳,表示迁移完了。
构造方法
public ConcurrentHashMap(int initialCapacity) {if (initialCapacity < 0)throw new IllegalArgumentException();int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?MAXIMUM_CAPACITY :tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));this.sizeCtl = cap;}
1.hash
(h ^ (h >>> 16)) & HASH_BITS;
将高位置0,因为后面要判断是MOVE等状态
2.初始化table
private final Node<K,V>[] initTable() {Node<K,V>[] tab; int sc;while ((tab = table) == null || tab.length == 0) {if ((sc = sizeCtl) < 0)Thread.yield(); // lost initialization race; just spinelse if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {try {if ((tab = table) == null || tab.length == 0) {int n = (sc > 0) ? sc : DEFAULT_CAPACITY;@SuppressWarnings("unchecked")Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];table = tab = nt;sc = n - (n >>> 2);}} finally {sizeCtl = sc;}break;}}return tab;}
2.尝试直接在桶下标放置元素
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {if (casTabAt(tab, i, null,new Node<K,V>(hash, key, value, null)))break; // no lock when adding to empty bin}
3.判断是否在迁移
如果是,则线程协助迁移
else if ((fh = f.hash) == MOVED)tab = helpTransfer(tab, f);
4.加锁操作
(1) fh>0说明是链表操作
采用尾插法
(2) f instanceof TreeBin说是是红黑树
synchronized (f) {if (tabAt(tab, i) == f) {if (fh >= 0) {binCount = 1;for (Node<K,V> e = f;; ++binCount) {K ek;if (e.hash == hash &&((ek = e.key) == key ||(ek != null && key.equals(ek)))) {oldVal = e.val;if (!onlyIfAbsent)e.val = value;break;}Node<K,V> pred = e;if ((e = e.next) == null) {pred.next = new Node<K,V>(hash, key,value, null);break;}}}else if (f instanceof TreeBin) {Node<K,V> p;binCount = 2;if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,value)) != null) {oldVal = p.val;if (!onlyIfAbsent)p.val = value;}}}}
4.根据树高,判断是否需要树化
树高小于8且桶的长度小于64位,不能树化
if (binCount != 0) {if (binCount >= TREEIFY_THRESHOLD)treeifyBin(tab, i);if (oldVal != null)return oldVal;break;}
5.统计size
采用与logaddr分段的思想
6.扩容流程
(1) 判断能否扩容
while (s >= (long)(sc = sizeCtl) && (tab = table) != null &&(n = tab.length) < MAXIMUM_CAPACITY)
(2)
(sc < 0:表示当前 table,【正在扩容】,sc 高 16 位是扩容标识戳,低 16 位是线程数 + 1
a.当前线程是触发扩容的第一个线程,线程数量 + 2
// 逻辑到这说明当前线程是触发扩容的第一个线程,线程数量 + 2// 1000 0000 0001 1011 0000 0000 0000 0000 +2 => 1000 0000 0001 1011 0000 0000 0000 0010else if (U.compareAndSwapInt(this, SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT) + 2))//【触发扩容条件的线程】,不持有 nextTable,初始线程会新建 nextTabletransfer(tab, null);
b.// 设置当前线程参与到扩容任务中,将 sc 低 16 位值加 1,表示多一个线程参与扩容
// 设置失败其他线程或者 transfer 内部修改了 sizeCtl 值if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))//【协助扩容线程】,持有nextTable参数transfer(tab, nt);
(3) stride步长,根据CPU或最小16长度
nextIndex与nextBound与i
------------------B---------I
----------------------------i-
// 推进标记
boolean advance = true;
// 完成标记
boolean finishing = false;
runBit
链表处理的 LastRun 机制,可以减少节点的创建
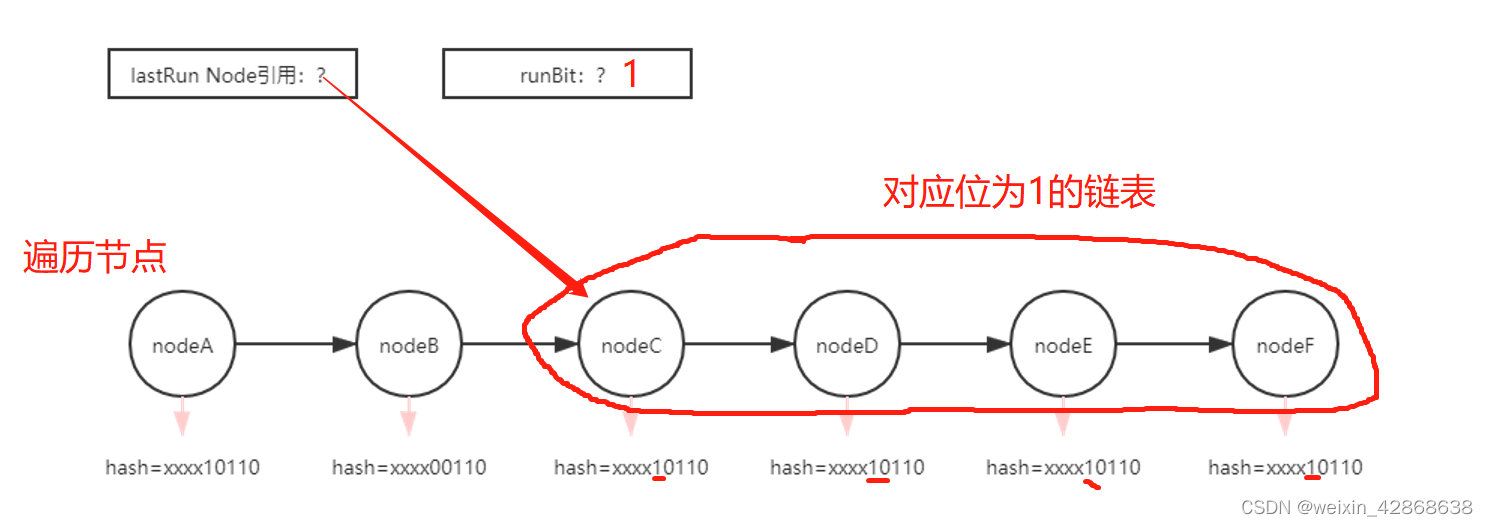
// 判断筛选出的链表是低位的还是高位的if (runBit == 0) {ln = lastRun; // ln 指向该链表hn = null; // hn 为 null}// 说明 lastRun 引用的链表为高位链表,就让 hn 指向高位链表头节点else {hn = lastRun;ln = null;}// 从头开始遍历所有的链表节点,迭代到 p == lastRun 节点跳出循环for (Node<K,V> p = f; p != lastRun; p = p.next) {int ph = p.hash; K pk = p.key; V pv = p.val;if ((ph & n) == 0)// 【头插法】,从右往左看,首先 ln 指向的是上一个节点,// 所以这次新建的节点的 next 指向上一个节点,然后更新 ln 的引用ln = new Node<K,V>(ph, pk, pv, ln);elsehn = new Node<K,V>(ph, pk, pv, hn);}// 高低位链设置到新表中的指定位置setTabAt(nextTab, i, ln);setTabAt(nextTab, i + n, hn);// 老表中的该桶位设置为 fwd 节点setTabAt(tab, i, fwd);advance = true;